Handling the Difficult Tasks in the SoC Dataplane
Chris Rowen discusses the benefits of dataplane processing with SemIsrael.
Designers have long understood how to use a single processor for the control functions in an SoC design. However, there are a lot of data-intensive functions that control processors cannot handle. That's why designers design RTL blocks for these functions. However, RTL blocks take a long time to design and verify, and are not programmable to handle multiple standards or changes.
Designers often want to use programmable functions in the dataplane, and only Cadence offers the core technology that overcomes the top four objections to using processors in the dataplane:
- Data throughput—All other processor cores use bus interfaces to transfer data. Cadence® Tensilica® cores allow designers to bypass the main bus entirely, directly flowing data into and out of the execution units of the processor using a FIFO-like process, just like a block of RTL.
- Fit into hardware design flow—We are the only processor core company that provides glueless pin-level co-simulation of the instruction set simulator (ISS) with Verilog simulators from Cadence, Synopysys, and Mentor. Using existing tools, designers can simulate the processor in the context of the entire chip. And we offer a better verification infrastructure over RTL, with pre-verified state machines.
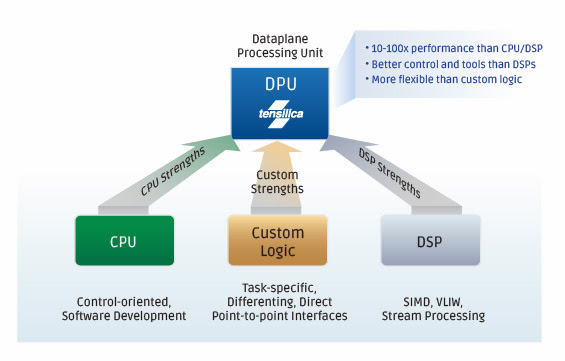
- Processing speed—Our patented automated tools help the designer customize the processor for the application, such as video, audio, or communications. This lets designers use Tensilica DPUs to get 10 to 100 times the processing speed of traditional processors and DSP cores.
- Customization challenges—Most designers are not processor experts, and are hesitant to customize a processor architecture for their needs. With our automated processor generator, designers can quickly and safely get the customized processor core for their exact configuration.
The Best of CPUs and DSPs with Better Performance
Tensilica processors combine the best of CPUs and DSP cores with much better performance and fit for each application. Where our processors really shine is in the dataplane - doing the hard work, handling complex algorithms, and offloading the host processor. Our processors and DSPs deliver programability, low power, optimized performance, and small core size.