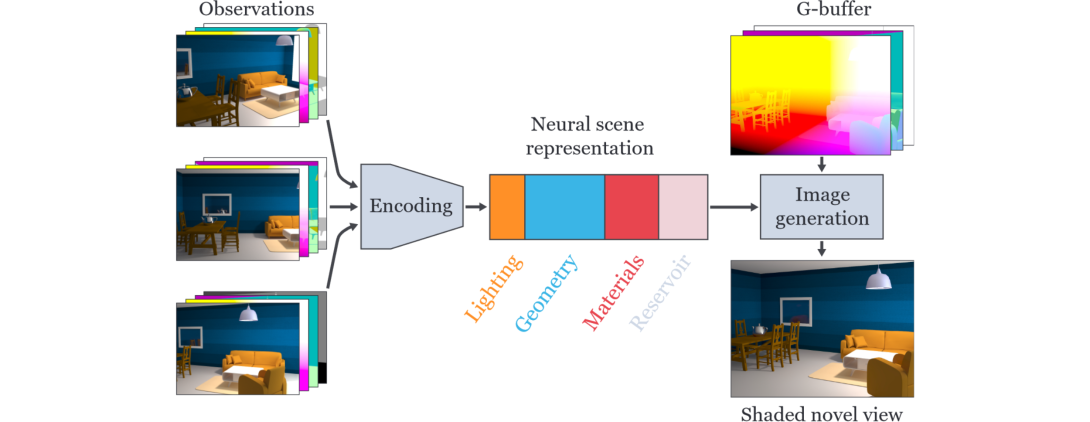
In recent years, computer-vision algorithms have demonstrated agreat potential for extracting scenes from images and videos in a(semi-)automated manner [Eslami et al. 2018]. The main limitation, common to most of these techniques, is that the extracted scene representation is monolithic with individual scene objects mingled together. While this may be acceptable on micro and meso scales, it is undesired at the level of semantic components that an artist may need to animate, relight, or otherwise alter.
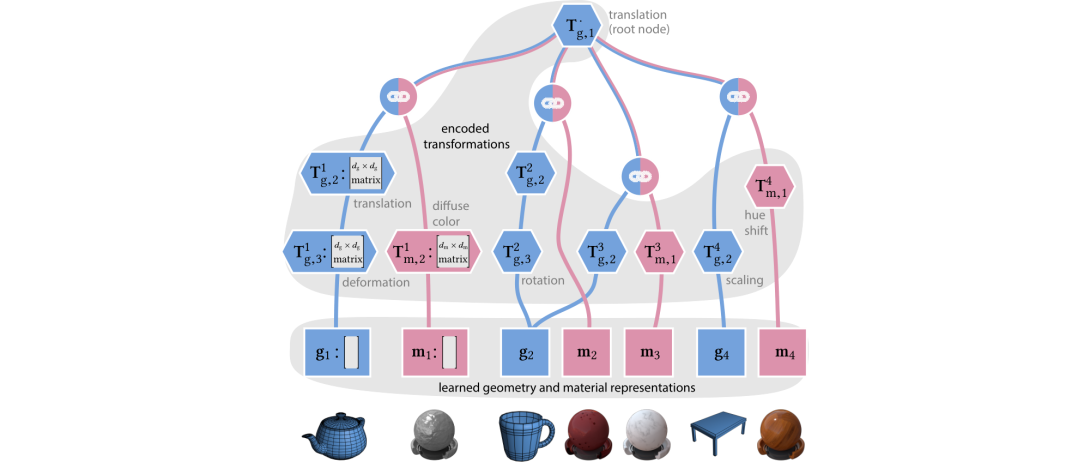
Compositionality and modularity—patterns that arise naturally in the graphics pipeline—are key to enable fine control over the placement and appearance of individual objects. Classical 3D models and their laborious authoring, however, are ripe for revisiting as deep learning can circumvent (parts of) the tedious creation process.
We envision future renderers that support graphics and neural primitives. Some objects will still be handled using classical models (e.g. triangles, microfacet BRDFs), but whenever these struggle with realism (e.g. parts of human face), fail to appropriately filter details (mesoscale structures), or become inefficient (fuzzy appearance), they will be replaced by neural counterparts that demonstrated great potential. To enable such hybrid workflows, compositional and controllable neural representations need to be developed first.