You don't have to keep them from success, you just need to ensure that their success cannot be mass applied or cheaply implemented. There were a number of stellar hacks for the PS3 and the 360 that never amounted to anything, simply because of the difficulty in implementing them in mass scale.If not for Sony's stupidity in the implementation, PS3 would have been remarkably robust. That same approach this gen, executed properly and with further refinements, should be enough to stave off mass piracy. The major issue is when your platform is hard to hack, you'll attract champions like Hotz trying to prove their brilliance, in it for the challenge. You need to keep them from success long enough that no piracy industry can evolve, as the pirates themselves have know interest in the hacking and won't invest in it.
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
PlayStation 4 (codename Orbis) technical hardware investigation (news and rumours)
- Thread starter Love_In_Rio
- Start date
- Status
- Not open for further replies.
I think piracy is more widespread on x360 than on PS3. Just check popular torrent sites and the numeber of people downloading titles for each system. Other thing, if that's due to security reasons or just DVD/Bluray diffrence, where burning Blurays is not so popular thing to do even nowdays, so you have to buy big HDD in your PS3 instead of simply get some DVD-R for x360.
Silent_Buddha
Legend
And as you can see with PC, online activation doesn't work either... it's a fools errand, if you ask me. Everything gets cracked. It's just a matter of time... but PSP openness was pretty massive^^
Not really, there is still no functional full game crack (single player) for Diablo 3 on PC. A functional full game crack (again single player) for the Original Guild Wars took well over 5 years to accomplish due to the encryption used and handhshake requirements for the client/server setup after which server emulation took another fair chunk of time, IIRC.
There are ways to make it nigh uncrackable, or at least so difficult to crack that no cracking group even wants to attempt it. But it is expensive. For Diablo 3, it meant they had to have an MMO like infrastructure to basically support a single player game. And things like that are expensive, especially when all numerical calculations and data (item/monster/character/etc.) are processed and stored server side. The client machine on PC basically only handles graphics and physics and processes player input.
Any functional crack would require full server emulation. Not just of the data but any calculations used during combat. One group attempted it, but never even fully emulated ACT 1 before they gave up.
Other games with an "online requirement" in order to play single player often had very little processed or stored server side (the last Sim City is a great example of this) which made them exceptionally easy to crack and emulate.
Regards,
SB
pMax
Regular
What Sony did was implement an encryption standard, but get it wrong.
Actually, this is wrong. If Sony had an encryption standard going wrong, the algorithm would have been exploited, which was not.
The problem was in the "Sony Random", as you called it, and that's something slightly different.
No amount of code review would have EVER spotted that, as such code would probably not even be in software platform.
No, in this case, you're wrong. The encryption standard specifies that one of the parameters must be random. Sony used the same random number every time. They botched their implementation of the standard.Actually, this is wrong. If Sony had an encryption standard going wrong, the algorithm would have been exploited, which was not.
The problem was in the "Sony Random", as you called it, and that's something slightly different.
No amount of code review would have EVER spotted that, as such code would probably not even be in software platform.
An encryption standard is more than just the algorithm used in it, it is also the specification of the parameters and how to choose them. Sony implemented the ECDSA encryption standard incorrectly.
TheWretched
Regular
Not really, there is still no functional full game crack (single player) for Diablo 3 on PC. A functional full game crack (again single player) for the Original Guild Wars took well over 5 years to accomplish due to the encryption used and handhshake requirements for the client/server setup after which server emulation took another fair chunk of time, IIRC.
There are ways to make it nigh uncrackable, or at least so difficult to crack that no cracking group even wants to attempt it. But it is expensive. For Diablo 3, it meant they had to have an MMO like infrastructure to basically support a single player game. And things like that are expensive, especially when all numerical calculations and data (item/monster/character/etc.) are processed and stored server side. The client machine on PC basically only handles graphics and physics and processes player input.
Any functional crack would require full server emulation. Not just of the data but any calculations used during combat. One group attempted it, but never even fully emulated ACT 1 before they gave up.
Other games with an "online requirement" in order to play single player often had very little processed or stored server side (the last Sim City is a great example of this) which made them exceptionally easy to crack and emulate.
Regards,
SB
Those are some really unfair comparisons. Diablo 3 isn't "cracked" because it's non-M morpg. Even when playing alone. Guild Wars IS an MMORPG. That's not online activation but online PLAYING.
Ubisoft, with Uplay starting with AC1 (iirc) tried the same as Sim City... took them longer to crack... but oh wonder it didn't work. And with AC2 and all others following it, it was opened within minutes of the release of the game.
Also, to elaborate on my previous point. On PC, it doesn't work at all against piracy. It ONLY works against second hand sales! I am yet to use a keygen for a cracked game today. Why? Because the crack would take care of it. Adding activation keys to console games would be just the same... make the game unsellable. Great stuff, as we've seen by MSs flip flopping on this topic. Imho, they were NEVER trying to combat piracy here. They were merely trying to get new sources of revenue, by tapping into second hand sales forcefully.
Don't get me wrong... I have little problems with DRM, if done right! I don't even mind not being able to resell my games (in fact, I have pretty much sold only 4 games in my entire gaming career, because I needed the money for new games at University^^), but that is me, because I collect my games.
pMax
Regular
An encryption standard is more than just the algorithm used in it, it is also the specification of the parameters and how to choose them. Sony implemented the ECDSA encryption standard incorrectly.
I disagree. The usage of it was clearly done incorrectly - essentially, an use case has been violated. But the implementation itself, was obviously right.
Same implementation, but with good (pseudo)random numbers, would have leaded to the correct behavior.
So imho the error is not in the implementation.
Silent_Buddha
Legend
Those are some really unfair comparisons. Diablo 3 isn't "cracked" because it's non-M morpg. Even when playing alone. Guild Wars IS an MMORPG. That's not online activation but online PLAYING.
The original Guild Wars was not an MMO. Unless you also consider the original Quake an MMO. Heck, Killzone 2, 3, and 4 are as much MMO as the original Guild Wars.
The only difference between something like the original Quake and the original Guild Wars was that Guild Wars had a graphical matchmaking lobby (town hubs) and single player enforced client/server gameplay.
And it isn't really an unfair comparison. There are lots more "uncrackable" single player games. Except most of them are currently in the F2P world. Warframe and Path of Exile are prime examples. Warframe continues with the Quake model of single/multiplayer style gaming but with the Guild Wars requirement of having to be online even if you only want to play single player. There is lots of content locked behind a "paywall" which is how they fund further development and expansion of the game.
The online requirement also removes the ability for people to crack the game and cheat, for the most part. Something that plagued games that allowed offline single player (Diablo 2, all Quake Games, etc.).
Ubisoft, with Uplay starting with AC1 (iirc) tried the same as Sim City... took them longer to crack... but oh wonder it didn't work. And with AC2 and all others following it, it was opened within minutes of the release of the game.
And as mentioned almost all other games that used token online requirements did barely anything online making them extremely easy to crack/emulate. After AC2, even less was done online thus removing the need to do extensive server emulation.
When done correctly, it makes your game pretty much uncrackable without spending so much time and effort that it's not worthwhile.
Also, to elaborate on my previous point. On PC, it doesn't work at all against piracy.
It does indeed work against piracy. The original Guild Wars continued to sell copies over a span of 5-6 years due to the inability to pirate the game.
Compare the sales of Diablo 3 to Torchlight 2 (which almost anyone that is into Action RPGs of this type consider the far better game). Then compare how many people actively play Diablo 3 to Torchlight 2.
Diablo 3 sales on PC dwarfed all other console and multiplatform titles not named COD due to the inability to pirate a working version of the game. Had they implemented an offline version of the game and hence made it as easy to crack as the later AC games or the latest Sim City game, sales would have been significantly lower despite gaining more active players.
Anyway, this is going off topic. I probably shouldn't have posted a reply. And I definitely won't after this.
") But the point remains it is possible to make something uncrackable/unhackable or at least not worth the effort to crack/hack. But doing so is expensive. Be it hardware or software.
But the point remains it is possible to make something uncrackable/unhackable or at least not worth the effort to crack/hack. But doing so is expensive. Be it hardware or software.Last gen Sony took the easy way out with not correctly implementing the security on the PS3. And Microsoft took the easy way out by relying on DVD drive firmware. Here's hoping they both took it seriously for the current gen.
Regards,
SB
No. The random number is not a user parameter, and most implementations of ECDSA do not expose it to the user. It is part of the implementation. The only parameters a user needs are the key and the data. If Sony had picked up an ECDSA library from elsewhere, they could not have made this mistake without modifying the source. Thus implementation.I disagree. The usage of it was clearly done incorrectly - essentially, an use case has been violated. But the implementation itself, was obviously right.
Same implementation, but with good (pseudo)random numbers, would have leaded to the correct behavior.
So imho the error is not in the implementation.
Sony should have just stood their ground and said that they were using a random number. They were and continued to be just really, really, really, really, reaaaallllyyy, unlucky.
pMax
Regular
No. The random number is not a user parameter, and most implementations of ECDSA do not expose it to the user.
You missed the point. Obviously it is not exposed to the user (well, technically one is), but it doesnt matter.
NO encryption standard will tell you how to generate a random number -it will only ask you to furnish a random number.
The way you generate it (from chaotic laser behavior, flipcoin, whatever) it is not business of the algorithm itlsef.
If they were able to tell you how to do so, you would not need an encryption algorithm at all. Just make it as long as your message, xor it and go on (which is btw what AES tries to do).
The random number is provided by your OWN random number generator, and it is not part of the encryption standard, which only requires you to furnish a random number.
An encryption standard does not tell you how to generate a random number, with the (partial) exception of some exotic schemes like BD's AACS.
...bad luck never last forever... even if, with Sony, it could have been the caseThey were and continued to be just really, really, really, really, reaaaallllyyy, unlucky.
... or maybe not
Last edited by a moderator:
TheWretched
Regular
...
It does indeed work against piracy. The original Guild Wars continued to sell copies over a span of 5-6 years due to the inability to pirate the game....
If you have to use server for DRM means and whatnot I consider that an online game. Doesn't matter if it's an MMORPG or not.
Guild Wars focus was PvP and instanced arenas... so... yes. An online game. Not an RPG in a sense of WoW, but surely others. NOT really a fair comparison.
LOL.
pMax and bkilian.
I think maybe you both need to clarify your individual definitions of the word "implementation" because it looks like two people debating from the same side of the argument.
"Sony was wrong"
"No. No. No. Sony was wrong."
"No you miss my point. See Sony was wrong."
"I got your point but it doesn't change the fact that Sony was wrong!!!"
pMax and bkilian.
I think maybe you both need to clarify your individual definitions of the word "implementation" because it looks like two people debating from the same side of the argument.
"Sony was wrong"
"No. No. No. Sony was wrong."
"No you miss my point. See Sony was wrong."
"I got your point but it doesn't change the fact that Sony was wrong!!!"
pMax
Regular
LOL.
"No you miss my point. See Sony was wrong."
"I got your point but it doesn't change the fact that Sony was wrong!!!"
No, the point isnt on what/who was wrong, but the type of error in itself.
The whole point of cryptography is (to make a long, long story short) to be able to transform your data in something not readable to unauthorized guys (and more, but just to summarize).
An encryption algorithm is composed by the algorithm itself, and then you have to generate its 'keys'. This is especially critical for any asymmetric encryption scheme, for various reasons.
Now, in order to generate your keys, you are always required to give some random number, in one shape or another.
Fact is, the standard dictates such numbers to be 'random', but it does NOT tell you how to make a random number, because it is impossible.
Reason is, if you knew a way to uniquely generate a fully arbitrary random number out of a seed, THAT would be your perfect encryption algorithm, as you would just make it as long as you need, 1-time XOR your message with it and game over. No crytoanalys, no cryptoattack, nothing. Game over.
most - if not all- common cryptos (and hashes) are avaialble in well coded libraries, and well implemented.
However, as the standard dictates you to have random numbers, YOU are to provide them with your pick on a random number generators.
It is not unusual that asymmetric ciphers are broken this way. As example, many years ago, a relatively well used protector was using RSA taking the random seed using the c library rand and the time function. By getting out the time of the protected executable's build, attackers were able to kill RSAs keys, getting back the random seed used to generate the keys.
Yet, the author DID NOT use a custom rsa, but a standard implementation of it!
heh, yeah. I'm giving up now.LOL.
pMax and bkilian.
I think maybe you both need to clarify your individual definitions of the word "implementation" because it looks like two people debating from the same side of the argument.
"Sony was wrong"
"No. No. No. Sony was wrong."
"No you miss my point. See Sony was wrong."
"I got your point but it doesn't change the fact that Sony was wrong!!!"
Another confirmation that PS4 has much slimmer abstraction layers between gaming engine and hardware:
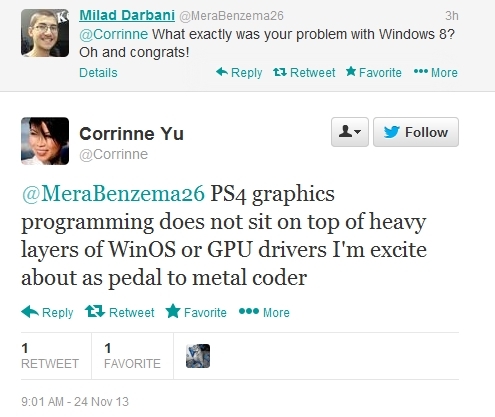
https://twitter.com/Corrinne/status/404655972976586752
This was response to this [now deleted] tweet.
https://twitter.com/Corrinne/status/404655972976586752
This was response to this [now deleted] tweet.
Another confirmation that PS4 has much slimmer abstraction layers between gaming engine and hardware:
This really isn't news. It's common knowledge that consoles have always had much lower access to the hardware than PC's. If anything the current news is that thanks to Mantle, this decades old situation looks like it finaly be ending (or at least improving significantly in the PCs favour). Perhaps she's jumped ship at the wrong time!
If Mantle doesn't say anything about compute, I don't know if it is adequate.
If Mantle is a replacement for Direct X then perhaps it doesn't since as far as I'm aware, devs don't go through DX for compute work. That said, GPGPU is going to be far less important for PC's due to the greater CPU resources and the added latency of PCI-E. Even without improving the interface for compute, Mantle cleary brings massive advantages for PC's in terms of low level GPU access though.
If Mantle doesn't say anything about compute, I don't know if it is adequate.
It may need a combination of Mantle and integrated chips combining CPU/GPU to see if hybrid algorithms are plausible. We haven't seen those so far - nearly everything launching now was developed on PC for the most part, even the exclusives. Even Guerilla had a full PC implementation of their engine.
- Status
- Not open for further replies.
Similar threads
- Replies
- 10
- Views
- 4K
- Replies
- 90
- Views
- 17K
- Replies
- 213
- Views
- 27K
- Replies
- 4
- Views
- 2K