What do you mean?5th we dont really have a real GCN driver yet so let hope that comes soon and we can see what we really can expect, it could still be current level or we could get a nice boost.
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
What do you mean?
The magick driver faeirie queen has just come back from her annual leave and has been working hard on the GCN driver since her return a couple weeks back. The GCN driver she has been working on (codename: Hardy) will give 7970 180% boost in most applications!
The hot clock should give better perf/mm^2 not worse. Nvidia's warp size being smaller than AMD's wavefront likely contributes something though.AMD had better perf/mm^2 in the past, mainly because
1) They didn't have all the GPGPU gunk that nVidia chose to put in
2) They didn't have a hot clock
With this generation
1) AMD has now gone down the GPGPU route, much like Fermi
2) nVidia has allegedly dropped the hot-clock
So, I would expect things to be much closer now
- though AMD would still have an advantage if they are on 28HPL, and NV is on 28HP...
Edit: Actually, that's a perf/w issue, not a perf/mm^2 issue, AFAIK
I don't think this is that obvious. It sure will decrease peak flops/area but it should lead to higher utilization (of course, depending on the workload, dynamic branching etc. should be faster). Haven't seen any numbers though for a conclusion either way.Nvidia's warp size being smaller than AMD's wavefront likely contributes something though.
Man from Atlantis
Veteran
There will be two variants of GK107, GK107-200 GPU in D14M2-20 and the top bin GK107-300 in D14P1-10 SKU. The GK107-300 variant will be powered by GDDR3 or GDDR5 memory, while the GK107-200 will sport 512MB of DDR3 RAM.
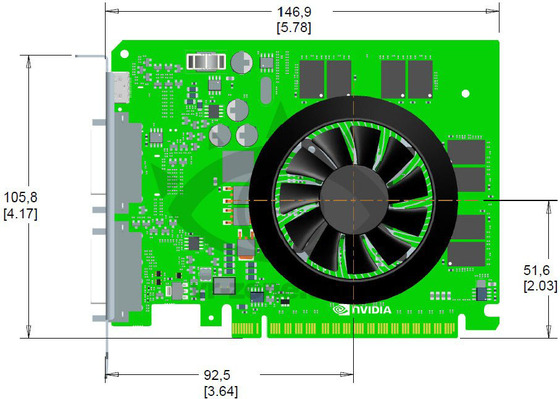
*click pic to source
i see pretty cheap pwm design should be a ~35-40W card..
Last edited by a moderator:
whitetiger
Newcomer
The hot clock should give better perf/mm^2 not worse. Nvidia's warp size being smaller than AMD's wavefront likely contributes something though.
My hunch is that the hot clock cost them more than it's worth - that's why
1) they're dropping it this time round (assuming that's a correct rumor)
2) no one else does it - i.e. if it was such a good idea to run most of the chip at this obviously stressful frequency, then AMD would have done it by now.
As discussed several pages back the hot clock costs a lot of energy and transistors to do all the additional pipeling necessary to get the clock speeds up.
whitetiger
Newcomer
2nd if you look in GCN thread lots of people where boarderline orgasmic about GCN's ALU architecture specifically around scheduling and how it is far simpler then fermi but almost as functional.
Adding GPGPU functionality costs transistors, compared to AMD's previous lean & mean design
- it's a burden that nVidia have been carrying for a few generations, but now has AMD designed a fairly comparable architecture, they also have to carry that burden.
This looks like a ddr3 equipped version so probably for GK107-200. Wouldn't be surprising then power draw would be below HD7750 level. Maybe for the other versions need more pwm circuitry?
*click pic to source
i see pretty cheap pwm design should be a ~35-40W card..
The extra transistors due to the increased clock rate are more than made up for by halving the ALUs. The negative to the hot clock concept is power, not area. Though there could be other negatives like complexity. There are a lot of bogus rumors floating about, but I have a feeling the removal of the hot clock is correct.My hunch is that the hot clock cost them more than it's worth - that's why
1) they're dropping it this time round (assuming that's a correct rumor)
2) no one else does it - i.e. if it was such a good idea to run most of the chip at this obviously stressful frequency, then AMD would have done it by now.
As discussed several pages back the hot clock costs a lot of energy and transistors to do all the additional pipeling necessary to get the clock speeds up.
That's out of a representative equivalent sample of 1, right?whitetiger said:2) no one else does it
You could also say that, right now, 50% of the contemporary, known add-on GPU architecture are using hot clocks. On average, of course...
Is it reasonable to guess that the hot clock is a power problem? I mean, it's not like these things are clocked at the 3GHz+ speed-racer CPU level. And as to the vector length and scoreboarding stuff... I'd love to see some numbers on energy consumption for the decode + issue part of a scoreboarded in-order pipeline relative to energy burned in a single fma.
Depends on what you call 'a problem'. If your performance is entirely power constrained (as I believe was and is the case for the 550mm2 beasts) every little big of improvement is going to help.psurge said:Is it reasonable to guess that the hot clock is a power problem?
Why compare it to a single FMA? (At least the decode part.)I mean, it's not like these things are clocked at the 3GHz+ speed-racer CPU level. And as to the vector length and scoreboarding stuff... I'd love to see some numbers on energy consumption for the decode + issue part of a scoreboarded in-order pipeline relative to energy burned in a single fma.
That's out of a representative equivalent sample of 1, right?
You could also say that, right now, 50% of the contemporary, known add-on GPU architecture are using hot clocks. On average, of course...
S3's Chrome 400 series (and probably Chrome 500 series, its hard to find architectural information on them but I get the feeling little changed) used hot clocks as well, and interestingly those were designs which focused on comparatively low power consumption.
That's two out of three contemporary designers of PC add-on board GPUs.
chavvdarrr
Veteran
How could they cancel a non-existing product?Here's my guess - the GK104 used TSMC's 28HP process
- however, they canned the GK100 as used too much power
- and the GK114 & GK110 will move to the 28HPL process, just like AMD are using for Tahiti...

Why compare it to a single FMA? (At least the decode part.)
Well - I figured the chances of getting/finding some information would be higher if we allow numbers from a more traditional scalar core. I was then just going to multiply the cost of a single FMA by the physical vector width. I don't know how applicable to current GPUs that would be, especially since they are heavily threaded, and numbers for a more traditional core are likely to be for a front end that has just a single thread context. Maybe some kind of scaling argument could be applied... anyway, at least it would be something slightly more concrete as a basis for speculation.
I would be ignoring stuff like the cost of sending the decoded instruction to all lanes of a SIMD, which seems like it might be non-negligeable if those are really wide. That seems like it could be a plus (in addition to covering ALU latency) for doing something like temporal SIMT. In the Maxwell thread there's a link to a description of Echelon, where there's a MIMD setup (including temporal SIMT), where a pair of DFMAs and a LD/ST unit get their own scheduler/decode issue logic (AFAICT), and so these numbers wouldn't be totally uninteresting in that context.
whitetiger
Newcomer
That's out of a representative equivalent sample of 1, right?
You could also say that, right now, 50% of the contemporary, known add-on GPU architecture are using hot clocks. On average, of course...
On average the clocks are medium-warm
Actually, superficially, going for a hot-clock scheme seem like an easy win
- a few extra pipeline stages, and boom, double your performance ...
- but as we have seen nV have had problems, and no perf/mm^2 or perf/W advantage, but really a perf advantage because they were prepared to use bigger chips.
AMD has always had more ALUs, and with the rumors pointing to a 2x increase in ALUs on the GK104 (with no hot-clocks), and AMD still managing a large ALU count on GCN, then this points to more than just power problems with hot-clocks
That's out of a representative equivalent sample of 1, right?
You could also say that, right now, 50% of the contemporary, known add-on GPU architecture are using hot clocks. On average, of course...
They're slightly different, but you could throw in Intel's HD graphics, VIA's whatever-it's-called, IMG's PowerVR, ARM's Mali, Qualcomm's Adreno…
Unless some of those actually use hot clocks, of course, but I'm not aware of that.
itsmydamnation
Veteran
Adding GPGPU functionality costs transistors, compared to AMD's previous lean & mean design
- it's a burden that nVidia have been carrying for a few generations, but now has AMD designed a fairly comparable architecture, they also have to carry that burden.
that again is assumption, how about quantifying what that burden is. its easy to say lean and mean, it doesn't really mean anything.
lets look at AMD's ALU scaling on LVIW 4/5 designs. now lets look at ALU utilization across current and near term expected workloads(the "life" of the GPU 2-3 years) and compare it to VLIW5 . its easy to say each ALU and supporting infrastructure costs more so therefore its "burdened with GPGPU like nvidia" but that assumes:
linear or near scaling of ALU's
DX11/compute shader workloads wont increase thus decreasing VLIW5/4 shader utilization
that NV and AMD made the same trade offs
now im the furthest thing from an expert in this area. But i dont see anything in your argument that really convinces me.
whitetiger
Newcomer
that again is assumption, how about quantifying what that burden is. its easy to say lean and mean, it doesn't really mean anything.
Quantifying:
Cayman has 1536 ALUs using 2.64B Transistors
Tahiti has 2048 ALUs using 4.31B Transistors
(substitute your own transistor counts if you disagree with these)
Comparing VLIW4 with GCN, then
--> 63% more transistors yields 33% more ALUs
--> therefore the overhead to support GCN vs VLIW4 is 22%
Fermi GF114 has 384 ALUs using 1.95B Transistors
Kepler GK104 has 1536 ALUs using 4.1B Transistors
(substitute your own transistor counts if you disagree with these)
Comparing Fermi to Kepler, then
--> 2.1x transistors yield 4x the ALUs
--> therefore no increase in GPGPU burden, but ditching the hot-clock gives massive benefit in terms of ALU density....
lets look at AMD's ALU scaling on LVIW 4/5 designs. now lets look at ALU utilization across current and near term expected workloads(the "life" of the GPU 2-3 years) and compare it to VLIW5 . its easy to say each ALU and supporting infrastructure costs more so therefore its "burdened with GPGPU like nvidia" but that assumes:
linear or near scaling of ALU's
DX11/compute shader workloads wont increase thus decreasing VLIW5/4 shader utilization
that NV and AMD made the same trade offs
now im the furthest thing from an expert in this area. But i dont see anything in your argument that really convinces me.
Going forward both AMD & NV agree that the GPGPU burden is worth spending the extra transistors on
- just NV made the jump before AMD did
Similar threads
- Replies
- 12
- Views
- 1K
- Replies
- 45
- Views
- 5K
- Replies
- 85
- Views
- 10K
- Replies
- 209
- Views
- 14K
- Replies
- 135
- Views
- 6K