boxleitnerb
Regular
What does a 580 get there?
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
What does a 580 get there?
What does a 580 get there?
Nothing, it's limited to 2 displays.
Nothing, it's limited to 2 displays.
we are talking about different cards here, there is going to be a special version, which I'm talking about
So the obvious question is, how does it compare to 3x1080p on HD7970 AND was that 29 FPS measured on the central or surround displays
According to this site http://www.overclockersclub.com/reviews/powercolor_lcs_hd7970/12.htm
HD7970 gets 22 fps.
GTX590 gets 27.
The 7970 seems a bit slow there?
That would make GK104 60% faster than a single 580.
Well, somebody once claimed that it is fundamentally impossible to have 4x distributed geometry processing without having massive latency and gargantuan power consumption. That same someone inexplicably continued to prove this by pointing at, wait for it: a cell characterization problem that was fixed with a metal patch. (WTF?) Then he murmured something about crossbars too, which is funny, because I didn't really expect a crossbar that serves memory to have much to do with distributing geometry at the front-end. Right? It made him even speculate that GK104 would only have 2x geometry, because that's what sensible people do.DarthShader said:So when are we going see the fixed bigK, aka GK100? Or at least GK110? GK112??
The resolution only increases pixel and not tessellation load, playing into HD7970's hands.
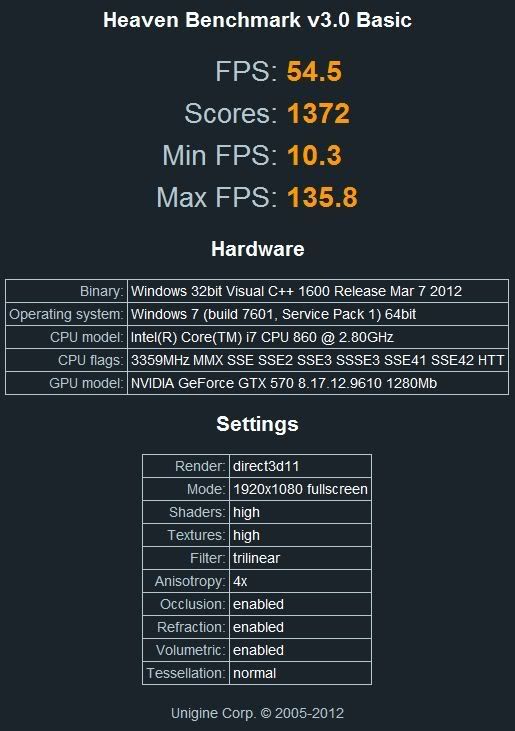
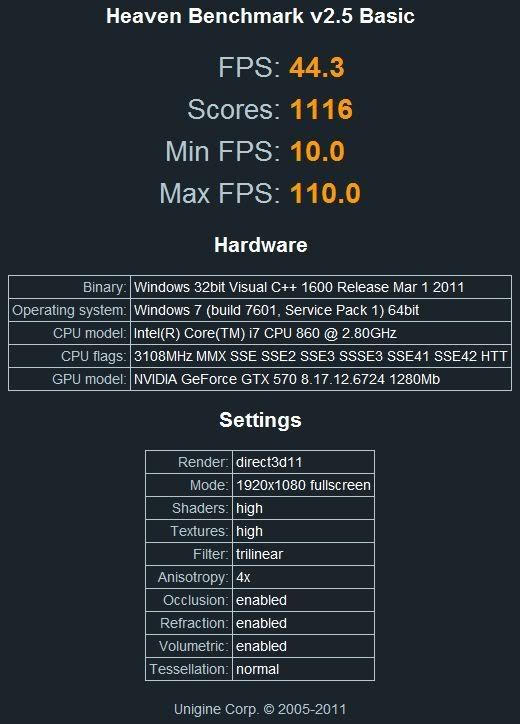
OT of Heaven 3.0: Results I've seen in the lab indicate that the 3.0 version seems to be quite a bit "faster", i.e. achieving higher fps - at least on some sort of cards.
Or you might simply ask Techpowerup's w1zzard if GPU-z 0.5.9 fully supports Kepler yet. [Hint: It doesn't, as you have noted above wrt to shaderclocks].This is curious btw
http://www.sf3d.fi/sites/default/files/3dm11 gtx 680.png
Notice the default clocks?
I thought very high resolutions are a strongsuit of AMD cards in general.
This is curious btw

Notice the default clocks?
edit:
GPU-Z obviously detects "shaderclocks" wrong, likely just "new enough nvidia, let's use gpu clock * 2"
After reading the release notes it was released not long ago. I think the previous version of that benchmark program is 2.5. I would like to see 3.0 vs 2.5 just to see if performance has changed or not using both cards.
Latency? Cross-bar interconnects are the first choice to be used in cases of low-latency communication between moderately large number of clients. The problem with complex cross-bar interconnects is the accumulation of hotspots due to signal crossings. In GF100 the distributed nature of both geometry processing (16x) and primitive setup (4x) asked for very dense wiring mesh. JHH said that this aspect of the architecture was the main reason the product delays and metal re-spins. The other obstacle was the large transistor leakage variance.Well, somebody once claimed that it is fundamentally impossible to have 4x distributed geometry processing without having massive latency and gargantuan power consumption.
Or you might simply ask Techpowerup's w1zzard if GPU-z 0.5.9 fully supports Kepler yet. [Hint: It doesn't, as you have noted above wrt to shaderclocks]...
