Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Nvidia GeForce RTX 4090 Reviews
- Thread starter DavidGraham
- Start date
In only 6 years and 3 generations, Nvidia has improved rendering performance by more than 9 times!


 techgage.com
techgage.com
NVIDIA GeForce RTX 4090: The New Rendering Champion
NVIDIA has just kicked-off its Ada Lovelace generation with a new flagship GPU: GeForce RTX 4090. Our first performance look will revolve around rendering, and once you see the results, you'll understand why. Whereas Ampere itself brought huge rendering gains over Turing, Ada Lovelace does the...
techgage.com
DegustatoR
Legend
Lag will be rather noticeable at FG from <60 fps. It may work in some titles but generally I'd say it's undesireable, because of lag and more visible artifacting.Arstechnica.com did fg from 40-50fps and they say it looks fine.
I have not watched any fg videos tho.
Yeah, interestingly gains in path traced applications don't seem to be out of the ordinary. I wonder if this is another indication of insufficient memory bandwidth increases.
I think path tracing is just very hard to get good utilization of the hardware because of thread divergence, if I'm using the term correctly.
DegustatoR
Legend
In this case SER should help. Hopefully Nv will update Q2RTX with it.I think path tracing is just very hard to get good utilization of the hardware because of thread divergence, if I'm using the term correctly.
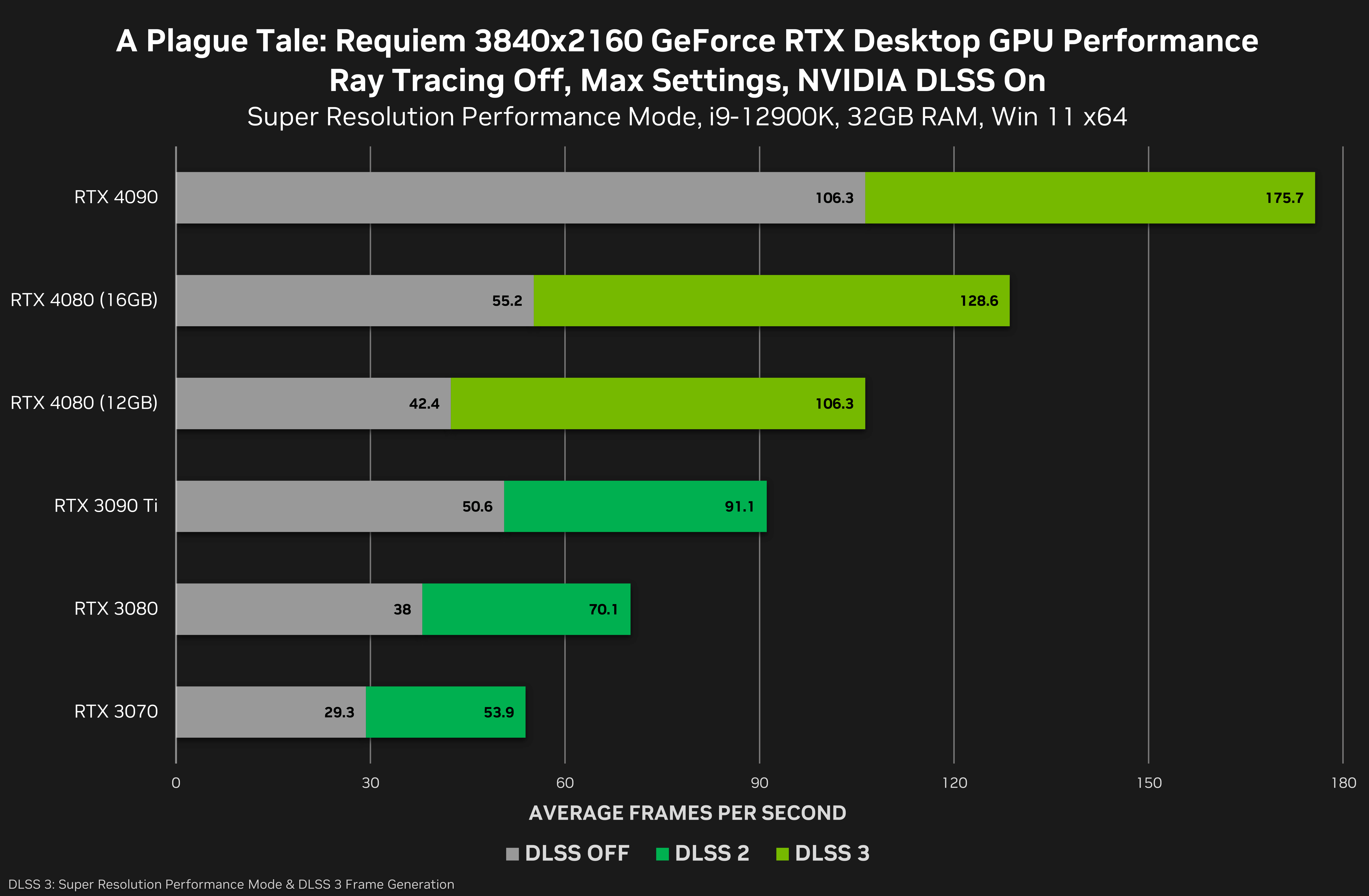

NVIDIA shares more gaming benchmarks for the RTX 4080 GPUs
NVIDIA has shared three new gaming benchmarks for its upcoming RTX 4080 12GB and RTX 4080 16GB graphics cards.
D
Deleted member 2197
Guest
I guess
From a h/w perspective doesn't DLSS3 utilize new fourth-generation Tensor Cores when calculating output?DLSS3 is the same as 2, it just takes the required engine inputs and spits out the frames, there's no engine side improvements to be made at all once it's functional. What you see is what you get.
Last edited by a moderator:
davis.anthony
Veteran
I have my doubts whether the actual cause is "big changes between frames", though have to admit it does have some clickbait appeal.
Even Digital Foundrys video showed DLSS3 to be picky with frame times and that it prefers a certain range of input data for optimal performance.
As Richard said , you feed DLSS3 garbage and it spits garbage out.
4090 is 93% faster than 4080 16G at native. That's a weirdly massive difference given the difference in specs.
Also the comparison between 3080 and the 29% more expensive ""4080"" 12G... Yikes!
D
Deleted member 2197
Guest
Yeah, I remember his comment because at the time I thought the same would be true for any type of ML output if all sample inputs were blurred/distorted. In this case it would be no different except for the degree (range) of blurred input samples.Even Digital Foundrys video showed DLSS3 to be picky with frame times and that it prefers a certain range of input data for optimal performance.
As Richard said , you feed DLSS3 garbage and it spits garbage out.
Subtlesnake
Regular
I'm curious how the 4080 12GB will do against the 3090 Ti in ray tracing. It has roughly the same FP32 capabilities and the newer architecture, but half the bandwidth.
DegustatoR
Legend
Again, I suspect a lack of memory bandwidth to be a key reason for such results. It is interesting that they've shown non-RT performance as well.4090 is 93% faster than 4080 16G at native. That's a weirdly massive difference given the difference in specs.
That's as bad as a comparison between a 3080/10 and a 3090Ti this gen - with 4080/12 being closer to the latter.Also the comparison between 3080 and the 29% more expensive ""4080"" 12G... Yikes!
But yeah, perf/price improvements will probably hit zero below 4080/12 with such prices.

You mean applications that are mostly or completely ray traced, with minimum or inexistent rasterization? I would guess it's simply way heavier than mixed rendering, so expected, as there is still more rasterization hardware in it that Ray Tracing? What makes you think it's a memory bandwidth issue?Yeah, interestingly gains in path traced applications don't seem to be out of the ordinary. I wonder if this is another indication of insufficient memory bandwidth increases.
davis.anthony
Veteran
Looking at the average clock speeds of the 4090 it seems to run at a clock speed that's 50% higher on average than the 3090.
And then factor in ~60% more 'shader' cores and it should actually be performing higher and scaling better than it actually is.
The only reason I can see that would cause this kind of scaling is memory bandwidth as it's not really seen an increase to match the increased compute performance.
I have previously mentioned that AMD and Nvidia may need to start looking at HBM memory as these cards are really stretching GDDR now and surely at some point the cost of GDDR must be approaching HBM cost.
And then factor in ~60% more 'shader' cores and it should actually be performing higher and scaling better than it actually is.
The only reason I can see that would cause this kind of scaling is memory bandwidth as it's not really seen an increase to match the increased compute performance.
I have previously mentioned that AMD and Nvidia may need to start looking at HBM memory as these cards are really stretching GDDR now and surely at some point the cost of GDDR must be approaching HBM cost.
4090 is 93% faster than 4080 16G at native. That's a weirdly massive difference given the difference in specs.
Also the comparison between 3080 and the 29% more expensive ""4080"" 12G... Yikes!
They are just a 4070 and 4060Ti wit a 4080 label attaches to them and if DLSS3 is not used (majority of the games) they show exactly that performance level.
DegustatoR
Legend
Path traced so yes.You mean applications that are mostly or completely ray traced, with minimum or inexistent rasterization?
Lovelace scales way further in RT than in rasterization, most RT benchmarks show this. This implies that a purely RT application must scale the most between Ampere and Lovelace but alas this isn't the case - they seem to scale in line with "hybrid" raster+RT engines. This is a weird outcome considering that said "hybrid" engines themselves tend to scale better than pure raster ones, and one possible explanation is the comparatively low memory bandwidth improvements on Lovelace - PT is very memory bandwidth intensive.I would guess it's simply way heavier than mixed rendering, so expected, as there is still more rasterization hardware in it that Ray Tracing? What makes you think it's a memory bandwidth issue?
Another possible explanation though is that these pure rasterization engines don't scale as well as "hybrid" or PT ones because they are CPU limited more often.
Or that in mixed rendering the RT hardware is simply not being taxed as much (in other words RT hardware for mixed rendering is now overkill, excluding Psycho CP2077)? I still think it's more about the workload than anything else. Are there any benchmarks showing energy consumption of mixed rendering versus path tracing? It would be interesting to see if there is a significant difference.Path traced so yes.
Lovelace scales way further in RT than in rasterization, most RT benchmarks show this. This implies that a purely RT application must scale the most between Ampere and Lovelace but alas this isn't the case - they seem to scale in line with "hybrid" raster+RT engines. This is a weird outcome considering that said "hybrid" engines themselves tend to scale better than pure raster ones, and one possible explanation is the comparatively low memory bandwidth improvements on Lovelace - PT is very memory bandwidth intensive.
Another possible explanation though is that these pure rasterization engines don't scale as well as "hybrid" or PT ones because they are CPU limited more often.
DegustatoR
Legend
Scaling seems fine to me. Most of 4090 benchmark results are CPU limited, even on a 5800X3D.The 4090 is a monster but for how much more engineered over the 3090 Ti, shouldn’t we be seeing way more performance? Why is the scaling so poor? Have we hit a wall regarding game engines, cpus, or something else?
Similar threads
- Replies
- 454
- Views
- 46K
- Replies
- 140
- Views
- 9K
- Replies
- 3
- Views
- 686
- Replies
- 7
- Views
- 3K