Both are Nvidia supplied information.Are the die sizes and transistor counts from Nvidia directly? I haven't seen the numbers mentioned anywhere else. And the RTX 3070 uses 16 Gbps GDDR6 dosen't it?
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Nvidia Ampere Discussion [2020-05-14]
- Thread starter Man from Atlantis
- Start date
-
- Tags
- nvidia
D
Deleted member 2197
Guest
I made the move to GFE right after registering for a GOG account and have not looked back. I think if you want to take full advantage of features using tensor/rt cores (gamers or professionals) then it will become necessary.This nvidia tool looks like it can do the same thing, but if it requires geforce experience I'm not sure that I want it.
Maybe this is normalized to the same number of ALUs?
Maybe but what would be the point of that.
DegustatoR
Legend
Most of those which give an option between a simpler and more complex shading workload.Which tests demonstrate this?
I've already mentioned TS vs TSE.
RT results are similar albeit it's harder to decouple RT improvements from flops gains there.
I think that people don't fully understand that Ampere is mostly limited by other stuff besides math atm. And it will likely increase it's performance advantage over Turing over time as more next gen games (even without RT) will come to market.
To demonstrate progress? If the 1080 was twice as fast as per your suggestion, it would be as fast as RTX 3080 in that example.Maybe but what would be the point of that.
Most of those which give an option between a simpler and more complex shading workload.
I've already mentioned TS vs TSE.
RT results are similar albeit it's harder to decouple RT improvements from flops gains there.
I think that people don't fully understand that Ampere is mostly limited by other stuff besides math atm. And it will likely increase it's performance advantage over Turing over time as more next gen games (even without RT) will come to market.
Nvidia hasn't said anything yet about why they went so hard on flops. It's certainly not guaranteed to pay dividends in the future. SVOGI is getting some attention but I don't know if that's even compute bound. There's also a lot of focus on high quality asset streaming but that's likely to be rasterization bound anyway. Not sure where all these flops will prove beneficial.
To demonstrate progress? If the 1080 was twice as fast as per your suggestion, it would be as fast as RTX 3080 in that example.
But there is no progress to demonstrate so the slide is misleading at best. A Pascal SM retired 256 FP32 flops per clock and INT32 had to compete for instruction slots, same as Ampere.
DegustatoR
Legend
Well, RTX I/O is flops, for one.Nvidia hasn't said anything yet about why they went so hard on flops. It's certainly not guaranteed to pay dividends in the future. SVOGI is getting some attention but I don't know if that's even compute bound. There's also a lot of focus on high quality asset streaming but that's likely to be rasterization bound anyway. Not sure where all these flops will prove beneficial.
Jawed
Legend
I think you should post specifics so that we can have a discussion about your theory.Most of those which give an option between a simpler and more complex shading workload.
I've already mentioned TS vs TSE.
So "fine wine"?RT results are similar albeit it's harder to decouple RT improvements from flops gains there.
I think that people don't fully understand that Ampere is mostly limited by other stuff besides math atm. And it will likely increase it's performance advantage over Turing over time as more next gen games (even without RT) will come to market.
But there is no progress to demonstrate so the slide is misleading at best. A Pascal SM retired 256 FP32 flops per clock and INT32 had to compete for instruction slots, same as Ampere.
They're demonstrating the architectural improvement irrespective of unit counts.
Ampere can issue FP and INT simultaneously just like Turing and unlike Pascal. The difference is in the ratios which in Ampere represent a more realistic real world ratio. This test demonstrates that. Pascal would always come out behind, but if the test featured a more unrealistic 50/50 FP/INT split then Turing would have equaled Ampere in this unit count agnostic test.
An SM is just a measure of control per compute. Or do you think, all generations after Kepler with its 192 FP32 ALUs per SM are a regression?But there is no progress to demonstrate so the slide is misleading at best. A Pascal SM retired 256 FP32 flops per clock and INT32 had to compete for instruction slots, same as Ampere.
DegustatoR
Legend
Specifics are coming in a week from now.I think you should post specifics so that we can have a discussion about your theory.
Kinda similar. GCN's "fine wine" was partially due to an excessive compute performance of earlier generations too.So "fine wine"?
SMs can issue 4 warps per clock, warp is 32 threads. There are 4 fp32 SIMDs that are 16 wide and 4 fp32+int32 SIMDs that are also 16 wide. Issuing a warp to SIMD will take 2 clocks to consume. So other combinations are possible if warps are available.I wasn't sure how granular the split could be but Computerbase.de states its either 128FP or 64FP + 64INT. I figured it was a scheduling limitation of some type and would help explain the performance scaling deficit. With finer grained scheduling and higher utilization i would have expected the dramatic increase in core counts to result in a bigger performance increase even with other possible bottlenecks.
They're demonstrating the architectural improvement irrespective of unit counts.
And this is why the picture is wrong. Looking at a single unit (i.e. SM) Pascal has the same instruction throughput as Ampere for mixed INT and FP loads. Ampere wins because it has more SMs total.
Ampere can issue FP and INT simultaneously just like Turing and unlike Pascal.
And Pascal's units are twice as wide so it's a wash.
Pascal would always come out behind
No, there's no scenario under which a Pascal SM has lower ALU throughput than an Ampere SM.
Geekbench 5 numbers from the 3080: https://browser.geekbench.com/v5/compute/1456542
And this is why the picture is wrong. Looking at a single unit (i.e. SM) Pascal has the same instruction throughput as Ampere for mixed INT and FP loads. Ampere wins because it has more SMs total.
And Pascal's units are twice as wide so it's a wash.
No, there's no scenario under which a Pascal SM has lower ALU throughput than an Ampere SM.
I don't think the chart was supposed to represent an SM, rather it's just normalised ALU throughput.
Man from Atlantis
Veteran
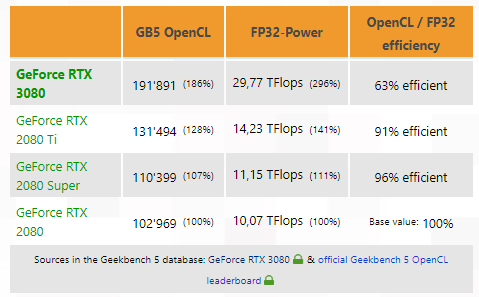
Seems about right. I'm super curious about overclocking. Overclocking will speed up the rops, the raster engines, the texture units, but I would assume in an OpenCL test those wouldn't be the bottleneck. That means the gpu most likely doesn't have enough bandwidth in all situations for the number of cuda cores, or is there something else in the front-end that could explain it? Is it possible this test is mixing int32, but in an unequal ratio to fp32, like a 2:1 split for fp32 to int32?
Similar threads
- Replies
- 49
- Views
- 8K
- Replies
- 98
- Views
- 35K
- Replies
- 1
- Views
- 7K