I'm on a 2080 Ti/9900K gaming at 3440x1440/120Hz. While it's enough for 99% of the games out there, it can fall short in games with heavy RT such as Cyberpunk, and even in some demanding games without RT, it can still dip below the 60fps mark at times. Can't say I'm not tempted by something that is ostensibly 2.5x the power of my card. Seeing my fps jump from 60 to 120+ would be something. The 4090 would murder everything at 3440x1440 and I don't think any game without massive RT would make it come close to dropping below 60fps even at max settings.Am on a 3900x/2080Ti too. And in all honesty theres zero reason to upgrade other than even higher fidelity and performance. The most logical upgrade would indeed be a 4090, but then a new CPU would be needed too to not bottleneck the thing too much. And yea, while Ryzen 7000 is impressive performance wise, i think raptor lake will stomp all over it.
5800X3D is the perfect gaming CPU indeed, its like the thing is made for gaming.
Though like you, I might need to upgrade my CPU as well.
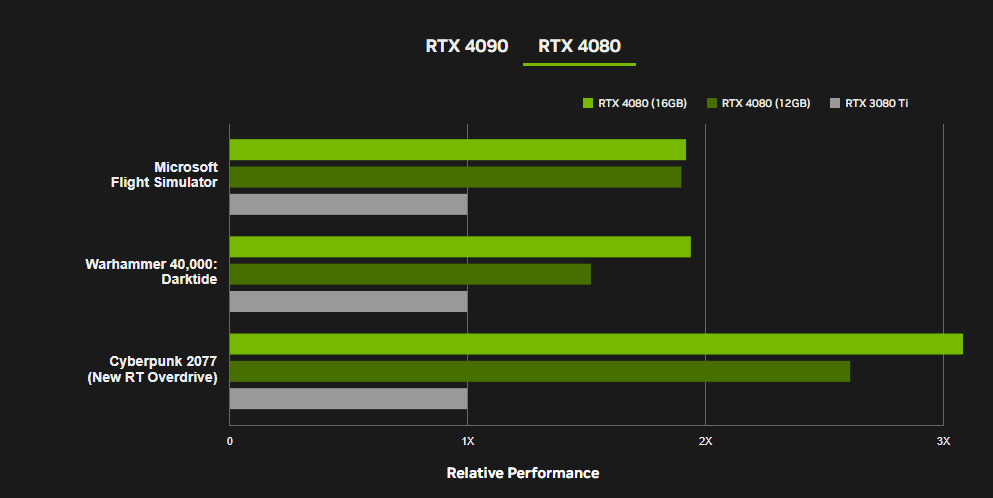

 .. the gains must not be impressive or ?
.. the gains must not be impressive or ?
