DegustatoR
Legend
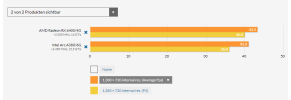
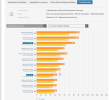
Worth remembering that A770 is using a chip which is is fact more complex than GA104, so unless it beats 3070 I don't see how we can say that Intel has a (relatively) good RT performance.In path traced games: like Quake 2 RTX, the A770 is massively behind NVIDIA, to the point that it's more like an AMD GPU, as the 3060 is 70% faster than A770, and 80% faster than RX 6650XT.
Elsewhere, the A770 is 40% faster than the 3060 in Metro Exodus, Dying Light 2 and Hitman 3 (as expected), but less than 10% in Cyberpunk 2077, Doom Eternal, Deathloop and Ghostwire Tokyo.

Preview • Intel ARC A770 LE 16 Go & A750 LE
Test des nouvelles cartes graphiques ARC A750 et ARC A770 16 Go au travers des modèles Limited Edition d'Intel. Au programme, 14 jeux testés, dont 10 en rastérisation, 10 en Ray Tracing, 13 benchmarks, des mesures de consommation, nuisances sonores, températures et imagerie infrarouge.www.comptoir-hardware.com