Is your 295 still OCed? Your sig says EVGA GTX 295 C=621 S=1512 M=1152?
Yes, I am running at: C=621, Shaders=1512, and Memory=1152
BTW - Where is the 'edit post' button?
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
Is your 295 still OCed? Your sig says EVGA GTX 295 C=621 S=1512 M=1152?
Yes, I am running at: C=621, Shaders=1512, and Memory=1152
BTW - Where is the 'edit post' button?
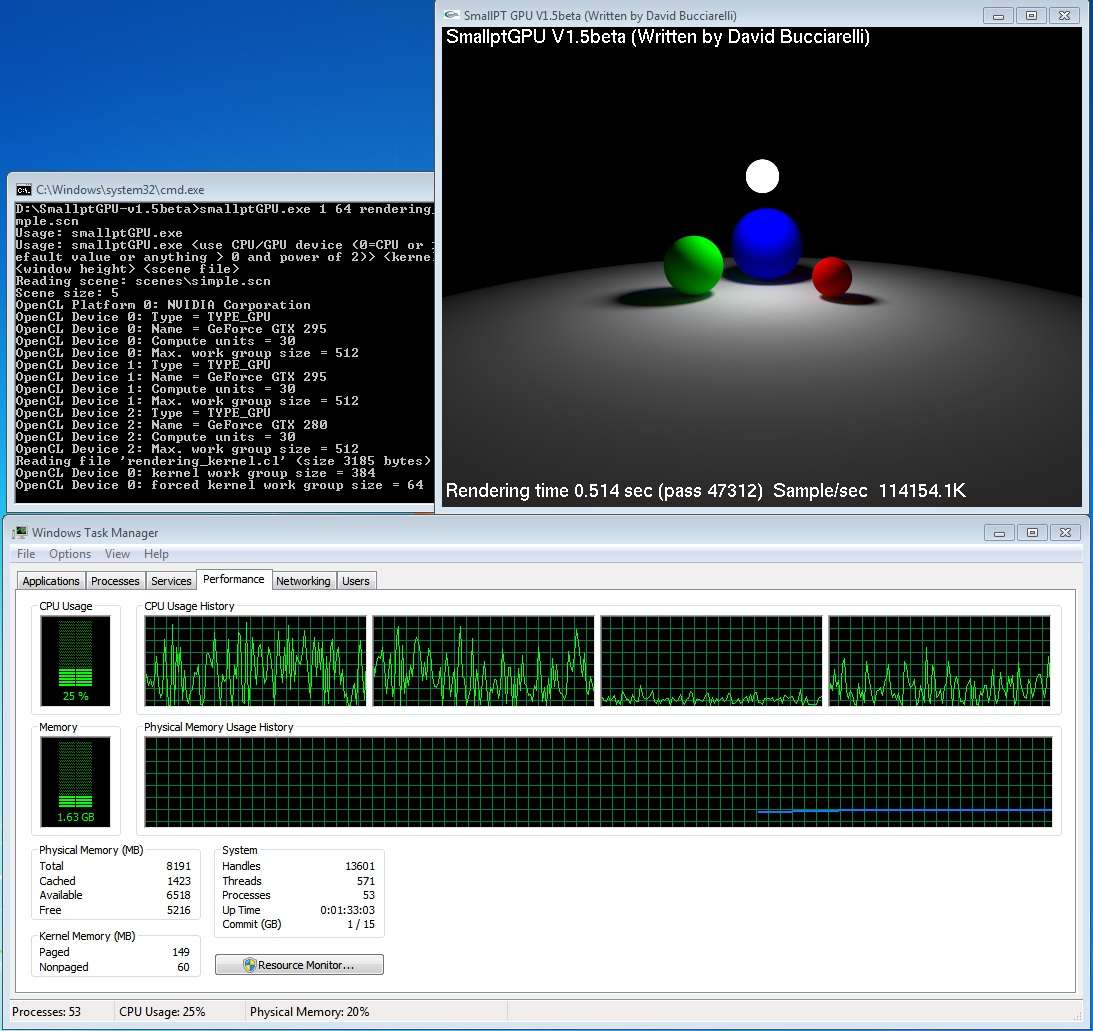
If we knew what the CPU was up to, I think it would help to put our finger on the performance issue.
What is the CPU load like when running simple.scn? That might be a clue.
Jawed
Thanks all, the performances on NVIDIA are still quite disappointing, I will try to give a look to NVIDIA OpenCL samples to see if I can find an explanation to the poor performances.
On ATI the register allocation has gone down by 1 and there's slightly less instructions. The reduction in register allocation doesn't affect the count of hardware threads which is approximately: floor(256/NUM_GPRS). The number of clause temporaries used can have a small impact, since these count towards register allocation.Thanks all, the performances on NVIDIA are still quite disappointing, I will try to give a look to NVIDIA OpenCL samples to see if I can find an explanation to the poor performances.
There's a 2-element array of integer seeds that's private per work-item. This array is put into local memory. On ATI the compiler just uses registers.Do you use any private array in your kernel?