
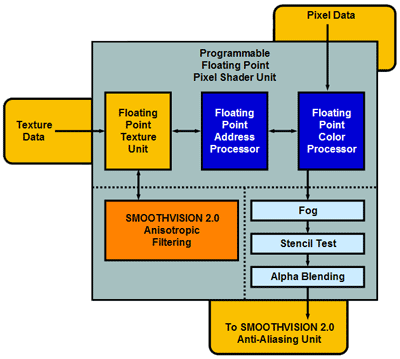
There's always so much talk of the somewhat obscure "3D Pipeline" and it's advantages over general computing. Companies go to great length to put out cute and simplistic block diagrams of their 3D chip such as this one by ATI:
At it's foundation, what is the underlying logic that is presently driving Vertex Shaders, Fragment Shaders, and the other ops done per clock?
Traditionally, it was my understanding that at heart, the 3D pipeline was nothing but many logic blocks put in parrallel that are dedicated to a specific feature. This was the [main] advantage to dedicated 3D ASICs as that they benefit from a linear preformance scaling with each additional logic block thats added. Bilinear Filtering comes to mind as an op that used many parrallel logic blocks to manipulate and produce a sample per clock.
Is this still relevant? For example, aren't VS's basically just an array of FP/SIMD processors that are in parrallel so that they can execute XX vertices/second? What about the T-Setup?
I think you can see where I'm going with this, anything related to the very lowest level of hardware implimentations would be greatly appreciated as it's never talked about.
At it's foundation, what is the underlying logic that is presently driving Vertex Shaders, Fragment Shaders, and the other ops done per clock?
Traditionally, it was my understanding that at heart, the 3D pipeline was nothing but many logic blocks put in parrallel that are dedicated to a specific feature. This was the [main] advantage to dedicated 3D ASICs as that they benefit from a linear preformance scaling with each additional logic block thats added. Bilinear Filtering comes to mind as an op that used many parrallel logic blocks to manipulate and produce a sample per clock.
Is this still relevant? For example, aren't VS's basically just an array of FP/SIMD processors that are in parrallel so that they can execute XX vertices/second? What about the T-Setup?
I think you can see where I'm going with this, anything related to the very lowest level of hardware implimentations would be greatly appreciated as it's never talked about.