Sorry you are correct, I got confused through calculations.
Though not your fault, AMD kept doubling stuff, my brain is swelling from SE, to SA, to dual compute units. Easy to lose track.
The diagrams don't separate what is a shader array in RDNA 2, so it can be easy to forget you're looking at shader engines instead and not shader arrays.
I wanted to point out that the number of RB's from RDNA 1 to 2 were halved. Which I guess wasn't the point you were trying to make; that instead there was 1 primitive unit and 1 raster per SA then per SE therefore the setup is like RDNA 1 and not RDNA 2. Well I'm not sure if that is correct. Because the setup is not likely to define what makes it RDNA 2. Block diagrams aren't necessarily as spot on as listed, how things are connected may not necessarily be as they appear. So it could be 2 rasterizers and 2 primitive units per shader engine. whereas RDNA 2 is 1 rasterizer and 1 primitive unit per shader engine.
If the distinction is that RDNA 1 binds those units to shader arrays than engines, then I would question why that would be a differentiation point or whether that even matters in terms of how it could affect performance. If there isn't something that highlights the difference, I'm not going to think there is any real difference.
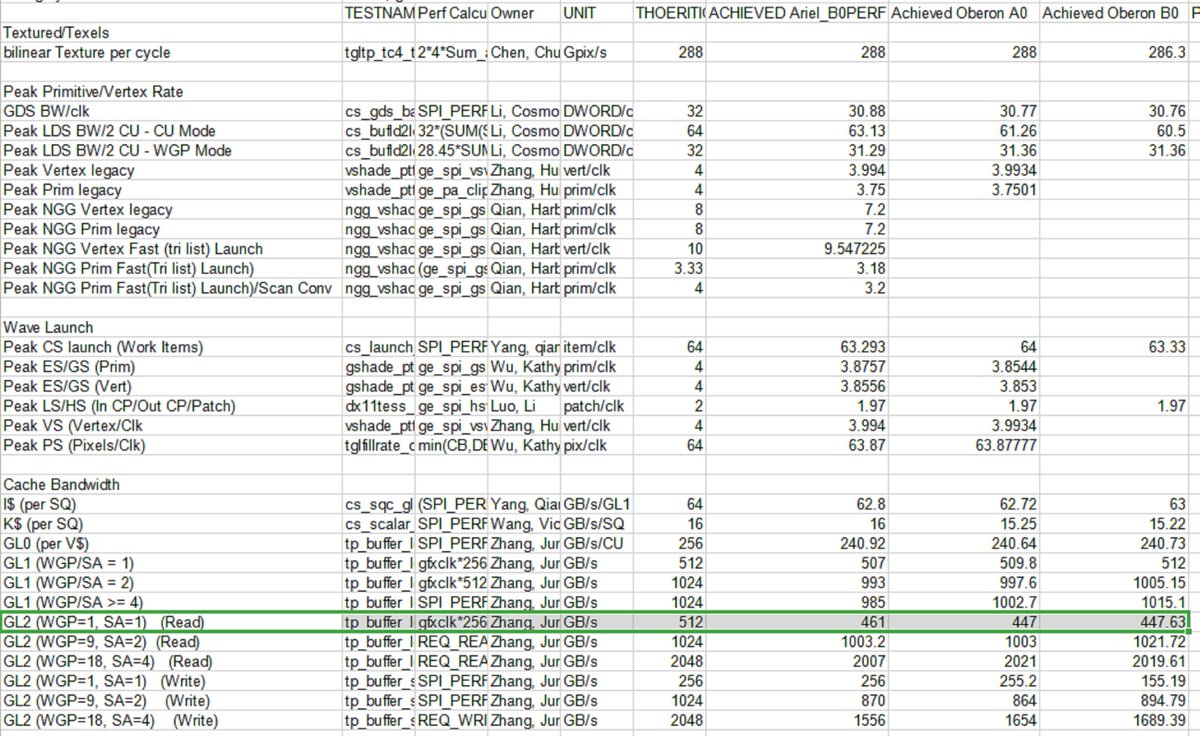
In terms of CUs as discussed earlier:
I'm going to go on a limb and say both consoles are 1.1 according to this diagram.
So as you see, it's no different from RDNA 2. I haven't found any other documentation that anything changed from RDNA 1 to 2 exception for mixed precision support and support down to int 4.
So essentially, custom CUs of RDNA 1 became the default for RDNA 2. Of which custom CUs are listed in the whitepaper anyway.
So aside from some speed differentiation in cache transfer. (which may not be necessarily optimal for 2 SE setups) we're not seeing a big difference.
That really just makes RB+ the definitive architectural change between RDNA 1 and 2. And that's really just around double pumping and support for VRS.
So as per this claim:
XSX
Front-End: RDNA 1
Render-Back-Ends: RDNA 2
Compute Units: RDNA1
RT: RDNA
Front End - makes no difference - someone thinking they're smart iwth a block diagram
RBs = RDNA 2
CUs = RDNA 2 or 1.1 which are effectively the same
RT is RDNA 2
So I would disagree with the claim.
edit: sorry I had to bounce around to see your claim here. There's a lot to take in at once, I apologize. It is easy to get lost, I wrote something and had to delete it. the doubling is taking an effect on me.
So basically it comes down to whether PS5 is based off Navi 22 in your opinion. And XSX is based on Navi 21 lite.
That is a very interesting proposition to consider. So you're basically trading off triangle performance to have much higher efficiency at micro-geometry. And because you have fewer triangles to output per cycle, you must rely very heavily on triangle discard.
That could explain things for sure. I need the games to come into my house to test, if the power output is that low, might explain why. It's basically slowing down with micro-geometry and nothing is really happening.
Interesting proposition to say the least.
Okay well we are about 6 months out now so here are some possible explanations for launch game performance as this is getting stale and probably no longer applicable (I would hope things have changed)
Geometry Shader (GS)
• Although offchip GS was supported on Xbox One, it’s not supported on Project Scarlett.
• We’re planning to move to Next-Generation Graphics (NGG) GS in a future release of the GDK.
• Performance for GS in the June 2020 release isn’t indicative of the final expected performance and will be improved in future releases.
• GS adjacency isn’t fully supported in the June 2020 release, but we’ll provide full support in a future release.
• You might encounter some issues with GS primitive ID with certain configurations. Please let us know if you do and the configuration you used so that we can further investigate the issue and provide a fix.
• When using multiple waves in a thread group, you might encounter graphics corruption in some GSs. If you do, please let us know so that we can try to help unblock you.
**
So typically IIRC, geometry shaders are very low performance and I believe most people get around them using compute shaders as the work around. But perhaps they don't suck using NGG. And that might explain why the RDNA 2 cards are performing very well in certain games? Just my thought here. It is likely outperforming a compute shader. Or just NGG in itself has been a big part of RDNA 2 success so far and more so with the titles that are supporting it. It's not exactly clear to me, nor the extent to which XSX can leverage the NGG path.
This is the convo: