The IEEE-754 standard already defines a maximum of 128 bits (quad-precision) for binary and decimal values and to this date only few exotic IBM main-frame processor architectures support native QP math. The rest of the IHVs don't bother beyond an optimized macro sequencing routine.
For a massive parallel architecture, like GPU, such thing will be a huge overkill.
I personally wouldn't mind a native 80-bit FP (extended precision) implementation though, mostly because of the spacious mantissa range.
For a massive parallel architecture, like GPU, such thing will be a huge overkill.
I personally wouldn't mind a native 80-bit FP (extended precision) implementation though, mostly because of the spacious mantissa range.
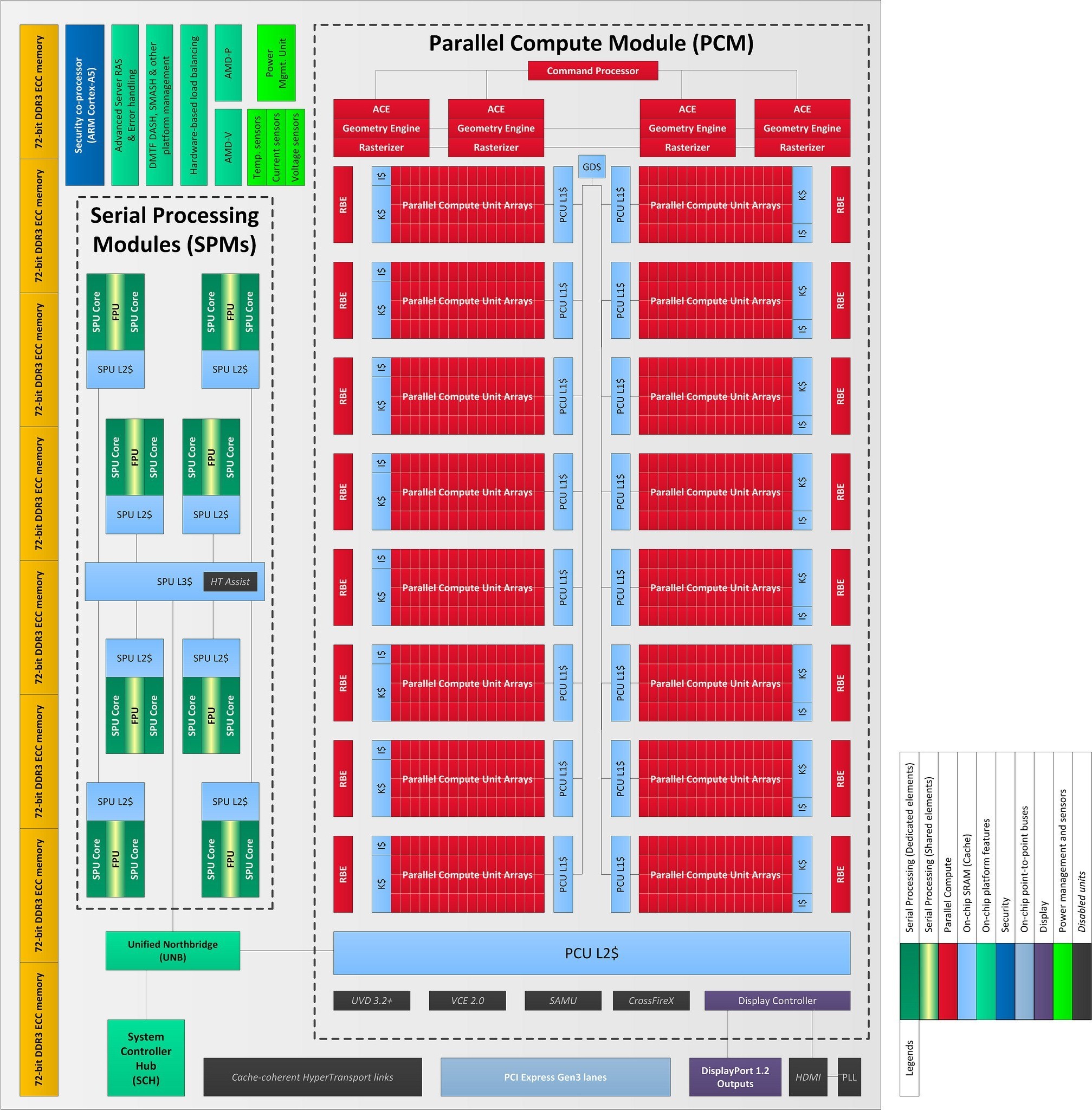
")