iMacmatician
Regular
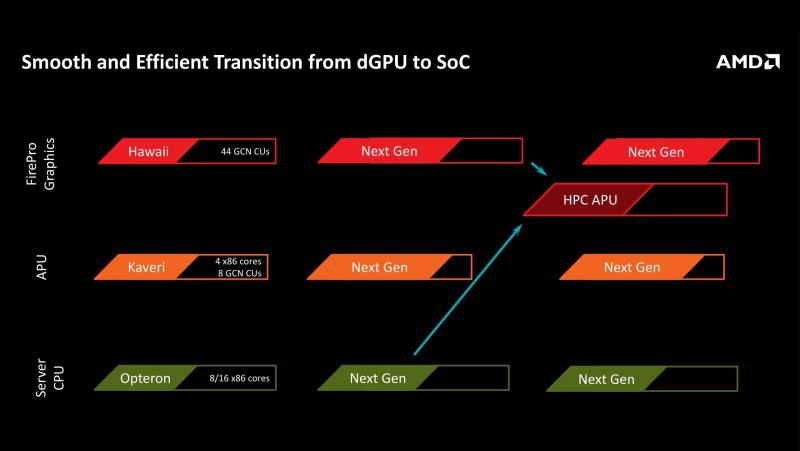
AMD has presented a GPU roadmap up to 2020 at the PC Cluster Consortium (from news.mynavi.jp).

The HPC APU scheduled for 2017 may have a TDP of up to 200-300 W.
Is it too much to hope for a consumer variant of that APU?
According to WCCFTech, the two-year cycle is specifically regarding APUs, and discrete GPUs will be updated more frequently.news.mynavi.jp said:In the graphics field, in 2012 "Tahiti", it has been developed a "Hawaii" in 2014, new graphics chips every two years: go to develop (dGPU discrete GPU). And, I will continue the cycle of incorporating it into the APU to the next odd-numbered years. As a result, APU of 2019 is that will have the computing performance of a few TFlops.
The HPC APU scheduled for 2017 may have a TDP of up to 200-300 W.
Is it too much to hope for a consumer variant of that APU?
")