Begun the attack of the quotes has...  No, not really. I'll focus on the older point quoted, but try to regard more of your objections in the course of the post.
No, not really. I'll focus on the older point quoted, but try to regard more of your objections in the course of the post.
I don't think, AMD lied to us, when they said, a 4-way symmetrical design makes life easier for the compiler, for their toolchain and is more efficient for generalized algorithms. Now, if you want to APU-ify every single market segment, you don't want to waste your expensive CPU cycles with all their OoO-overhead (area- and thus cost wise) just to feed another processor inside the processor.
Having the experience that they have with VLIW5 and the evolution of workloads both for graphics and especially more generalized loads, and having actually listened (not only read PDFs) to some of the AFDS presentations, it seems pretty clear to me that they want to get rid of VLIW5 better sooner than later. And that not only, because they don't have to cater for one less architecture variant. In Eric Demers' keynote (~22:20) he explicitly mentions that they VLIW4 arch is better optimized for compute workloads and remember the Cayman launch - there they said, they'd be getting 10% better performance per area for this kind of VLIW and have a simplified register management (which won't play a big role once they move to GCN, I'll admit). Again - AMD is all about cost conscious products these days - and obviously they need to - so it just makes sense to have the best possible solution integrated into their products.
With regard to RBEs, I don't think AMD has been introducing EQAA modes just because Nvidia has them (as CSAA), especially not with independently selectable number of coverage samples. And I don't think, the coalesced write ops are there just because it's funky to show in a presentation. AMD knows that they are severely bandwidth limited in their fusion APUs and that they will need ways, methods and tricks to save up as much of this bandwidth as they can. Because even if they add area here, every byte of bandwidth wasted puts more of the expensive SIMD arrays (and in future CUs) to idle.
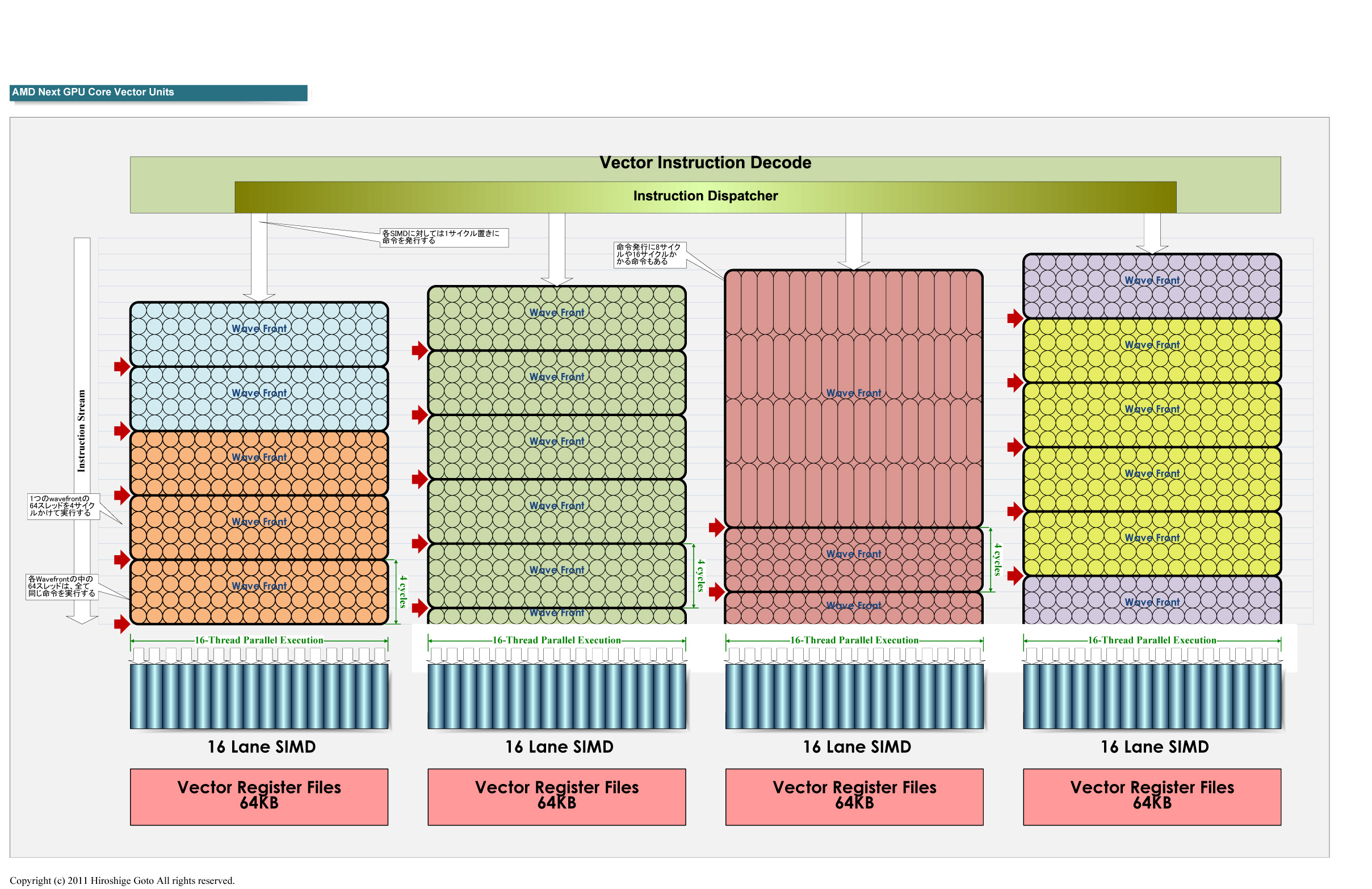
Another - maybe quite far fetched - hypothesis of mine is, that the actual execution units in Cayman being symmetrical as they are, might not be so very different to what we're going to see integrated into GCN's CUs' vector units. What I'm talking about are the individual ALU lanes, of course - stripped of the branch unit (which will then be handled by the scalar unit) and grouped into a 4x4 configuration.
How exactly DP is handled and thus probably gets handled in GCN I have no idea. I only hear on the forums about ganged operation of ALUs, but with all I've read neither AMD nor Nvidia provide specifics about this - they only talk about "operations" (instruction slots?). AFAIK, you need 23 bits of mantissa for single precision and 52 bits for doubles, right? Wouldn't it suffice then to "just" extend your SP-SP's mantissa to 26 bits (of course also the required data paths) in order to combine just two ALU lanes? Note that Demers only said about current VLIW4 "They're all effectively the same" (~22:50, my bold) and how it was easier to optimize (the hell out of) just one unit. I don't know if that's really a clue whether or not the four (or soon 16) Lanes are identical or if two out of four are just a little wider for half-rate DP.
No, not really. I'll focus on the older point quoted, but try to regard more of your objections in the course of the post.I disagree - especially in terms of RBEs, but first things first.Cayman is marginal as an "improvement" in these regards though, a tweak.
I don't think, AMD lied to us, when they said, a 4-way symmetrical design makes life easier for the compiler, for their toolchain and is more efficient for generalized algorithms. Now, if you want to APU-ify every single market segment, you don't want to waste your expensive CPU cycles with all their OoO-overhead (area- and thus cost wise) just to feed another processor inside the processor.
Having the experience that they have with VLIW5 and the evolution of workloads both for graphics and especially more generalized loads, and having actually listened (not only read PDFs) to some of the AFDS presentations, it seems pretty clear to me that they want to get rid of VLIW5 better sooner than later. And that not only, because they don't have to cater for one less architecture variant. In Eric Demers' keynote (~22:20) he explicitly mentions that they VLIW4 arch is better optimized for compute workloads and remember the Cayman launch - there they said, they'd be getting 10% better performance per area for this kind of VLIW and have a simplified register management (which won't play a big role once they move to GCN, I'll admit). Again - AMD is all about cost conscious products these days - and obviously they need to - so it just makes sense to have the best possible solution integrated into their products.
With regard to RBEs, I don't think AMD has been introducing EQAA modes just because Nvidia has them (as CSAA), especially not with independently selectable number of coverage samples. And I don't think, the coalesced write ops are there just because it's funky to show in a presentation. AMD knows that they are severely bandwidth limited in their fusion APUs and that they will need ways, methods and tricks to save up as much of this bandwidth as they can. Because even if they add area here, every byte of bandwidth wasted puts more of the expensive SIMD arrays (and in future CUs) to idle.
Another - maybe quite far fetched - hypothesis of mine is, that the actual execution units in Cayman being symmetrical as they are, might not be so very different to what we're going to see integrated into GCN's CUs' vector units. What I'm talking about are the individual ALU lanes, of course - stripped of the branch unit (which will then be handled by the scalar unit) and grouped into a 4x4 configuration.
How exactly DP is handled and thus probably gets handled in GCN I have no idea. I only hear on the forums about ganged operation of ALUs, but with all I've read neither AMD nor Nvidia provide specifics about this - they only talk about "operations" (instruction slots?). AFAIK, you need 23 bits of mantissa for single precision and 52 bits for doubles, right? Wouldn't it suffice then to "just" extend your SP-SP's mantissa to 26 bits (of course also the required data paths) in order to combine just two ALU lanes? Note that Demers only said about current VLIW4 "They're all effectively the same" (~22:50, my bold) and how it was easier to optimize (the hell out of) just one unit. I don't know if that's really a clue whether or not the four (or soon 16) Lanes are identical or if two out of four are just a little wider for half-rate DP.