Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD Radeon RDNA2 Navi (RX 6500, 6600, 6700, 6800, 6900 XT)
Here is a link to my save in this spot:
https://we.tl/t-ji2oR2IqIG
Your save file doesn't load for me. Do I need the full version of Quake 2? I installed the "shareware" version of Quake 2 RTX from Steam. Your save says "base1.sav", my saves say "demo1.sav".
For what it's worth here are numbers from a 3090 taken from the very start of the demo version standing in front the translucent wall. Settings are the same as posted earlier in the thread.

Last edited:
Your save file doesn't load for me. Do I need the full version of Quake 2? I installed the "shareware" version of Quake 2 RTX from Steam. Your save says "base1.sav", my saves say "demo1.sav".
For what it's worth here are numbers from a 3090 taken from the very start of the demo version standing in front the translucent wall. Settings are the same as posted earlier in the thread.
Yes, full version of a classic game
")
NightAntilli
Newcomer
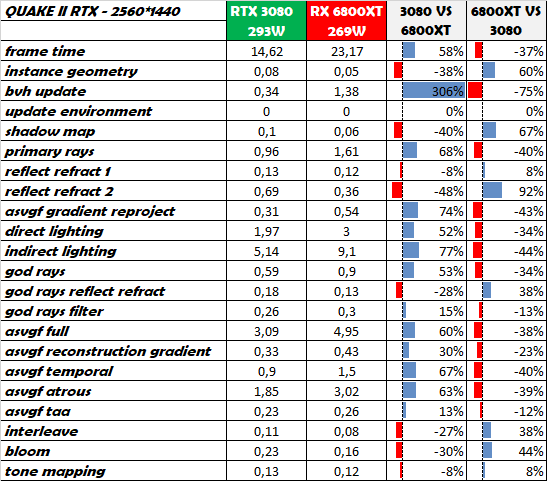
That is particularly interesting, because, the bvh update here seems to be faster than the RDNA2 cards...? That takes a particularly long time on the RDNA2 cards for some reason.For the LOLs, here is a 1080Ti @ 2037/13000 MHz :

The RT fixed function hardware in RTX card is specifically and solely designed to highly accelerate BVH traversal.That is particularly interesting, because, the bvh update here seems to be faster than the RDNA2 cards...? That takes a particularly long time on the RDNA2 cards for some reason.
NightAntilli
Newcomer
The 1080Ti doesn't have RT cores.The RT fixed function hardware in RTX card is specifically and solely designed to highly accelerate BVH traversal.
oh sorry, didn't notice the reference there.The 1080Ti doesn't have RT cores.
Reflection and refraction rays are still pretty much coherent since they mostly bounce in the same direction.Looks like AMD is [at times] better at inhoherent rays (all the reflect ones), and worst at coherent ones (primary ray)
Incoherent rays are the "indirect lighting", which is 2 bounce GI, where rays bounce in completely random directions. Would be interesting to see how 6800 XT fares with medium GI setting (1 bounce IIRC).
Nice graph, but does it representative of the average ingame performance?
Timedemo benchmark shows different proportions between these 2 GPUs and I guess it's way more close to the performance one might expect in the game in general.
In order to gain something representative of average ingame performance, I would look for a scene with FPS proportions as close to the timedemo results as possible.
https://www.nvidia.com/content/dam/...pere-GA102-GPU-Architecture-Whitepaper-V1.pdfThat is particularly interesting, because, the bvh update here seems to be faster than the RDNA2 cards...?
Look at the table 3 in the GA102 whitepaper
There is a feature called "Instance Transform Acceleration", it's related to the BVH building (probably it cost nothing for SIMD's in GA102 to apply the instance transformation - move/rotate a box or a model).
Do we know whether RDNA2 supports this feature?
Last edited:
Tried to get an impression, but too much code.Denoising is pure math, is it? More flops win?
One example: For each pixel they fetch a 3x3 neighborhood. This could be optimized by caching larger tiles (or a scrolling window) in LDS, to read every pixel just once instead 27 times.
Not sure if such extra work is still worth it on recent GPUs, but in the past i did get big speedups from such practices on AMD, while benefit on NV was much less or it did even hurt.
The fact NV beats AMD on pretty every listed task is surprising. It's a research project, so probably not that optimized. And my other experience with NV vs. AMD is that NV is much more forgiving to that than AMD.
... just some thoughts ofc, and i don't know how current Quake2 RTX has changed from the open source project.
Yeah, i'm no expert either, just wanted to make clear tensors do generic math ops which return immediately. In contrast, tracing a rays on RT cores takes some time, so the calling program will pause and shader core will work on a different program while waiting.Hm, im no expert on that, but NV says DLSS runs (partially) on the tensor hardware/cores. Obviously it helps greatly in performance, turning a 1080p/1440p image into a 4k one that looks exactly like a native 4k one is kinda impressive to the untrained eye (99% of the users):
Ofc. this tells us nothing about performance. To make some general ML comparisons NV vs. AMD, we could do so using DirectML, because here the vendors can implement commonly used subroutines optimized for their hardware.
But i guess it will take some time until all this is done and benchmarks show up.
If AMDs upcoming upsampling won't use DirectML but compute shaders, it likely can run on NV too. But then i'm unsure if NV compiler manages to not fully utilize tensor cores, so the result could be underutilizing, even if it would beat AMD non the less.
Making perf comparisons only becomes harder... : )
DegustatoR
Legend
Why wouldn't it run on NV even if it will use DirectML? As of right now NV support more DML metacommands than AMD and does support everything which is supported on RDNA2.If AMDs upcoming upsampling won't use DirectML but compute shaders, it likely can run on NV too.
My point only was that a non-DirectML upscaling compute shader optimized for AMD would run on NV, but might not fully utilize its tensor cores.Why wouldn't it run on NV even if it will use DirectML?
DegustatoR
Legend
It won't utilize the tensor cores at all since these must be specifically accessed and programmed for. It doesn't mean much for performance though. Nv is actually ahead in general compute too these days.My point only was that a non-DirectML upscaling compute shader optimized for AMD would run on NV, but might not fully utilize its tensor cores.
I doubt this. Because fp16 is also processed by tensor cores, the compiler should utilize tensor instructions from any shader stage and program without manual extra work?It won't utilize the tensor cores at all since these must be specifically accessed and programmed for.
Though if true, i don't know what this means to the programmer.
E.g. i never use built in shading language matrix types. Instead i do the math manually using dot products, and it saves me some registers so that's a speed up.
But now i'm no longer sure. Maybe using matrix types would help the compiler to utilize tensors.
Maybe somebody can clarify. Also, if tensors do affect regular game development, it would be worth for NV to give some information and advise on that.
I'll only know after testing (and - if necessary- optimize for) both architectures myself. Benchmarks never reflected what i have experienced.Nv is actually ahead in general compute too these days.
Still waiting for Christkind to bring me bunch of GPUs...
DegustatoR
Legend
FP16 is regular math, nothing to do with matrix multiplications. Anything targeting DirectML is using its calls specifically. If you're suggesting that you can perform matrix ops on regular math pipeline then sure, you can. This way you're not using DML though and limiting yourself from taking advantage of ML h/w - for no apparent reason.Because fp16 is also processed by tensor cores, the compiler should utilize tensor instructions from any shader stage and program without manual extra work?
Wait what? Am I reading your post right, it looks like you're suggesting you'd have to use tensor cores to use DirectML and that DirectML would be just about matrix multiplications?FP16 is regular math, nothing to do with matrix multiplications. Anything targeting DirectML is using its calls specifically. If you're suggesting that you can perform matrix ops on regular math pipeline then sure, you can. This way you're not using DML though and limiting yourself from taking advantage of ML h/w - for no apparent reason.
DegustatoR
Legend
No.looks like you're suggesting you'd have to use tensor cores to use DirectML
Yes.and that DirectML would be just about matrix multiplications?
FP16 is regular math, nothing to do with matrix multiplications. Anything targeting DirectML is using its calls specifically. If you're suggesting that you can perform matrix ops on regular math pipeline then sure, you can. This way you're not using DML though and limiting yourself from taking advantage of ML h/w - for no apparent reason.
Now it becomes confusing. If DirectML is only about matrix multiplications as you say, then why would a game developer need to use a new API just to make them run on proper HW units, and why would a ML developer care about an API over just matrix multiplications?Yes.
Can't agree with either. DML is certainly about more than just multiplications:
Coming back to non ML game tasks, i still don't think not using DML limits HW advantage.The library of operators in DirectML supplies all of the usual operations that you'd expect to be able to use in a machine learning workload.
- Activation operators, such as linear, ReLU, sigmoid, tanh, and more.
- Element-wise operators, such as add, exp, log, max, min, sub, and more.
- Convolution operators, such as 2D and 3D convolution, and more.
- Reduction operators, such as argmin, average, l2, sum, and more.
- Pooling operators, such as average, lp, and max.
- Neural network (NN) operators, such as gemm, gru, lstm, and rnn.
- And many more.
If we do low precision math in a regular compute shader, Tensor Cores should process it, and there is and should be no need for DML?
Further i would assume Tensor Cores can do other operations, including scalar math and dot products?
It's hard to figure out. Here they say it is 4x4 madd, yes, but we also know Turing does all fp16 on tensors, and Ampere has new ML HW features as well.
(edit: talking only about NV HW ofc.)
DegustatoR
Legend
Cause that's what gives these calculations a performance boost. And it's not a new API, not really, it's a part of D3D12, in the same way as DXR.Now it becomes confusing. If DirectML is only about matrix multiplications as you say, then why would a game developer need to use a new API just to make them run on proper HW units, and why would a ML developer care about an API over just matrix multiplications?
Sure, never said it does.Coming back to non ML game tasks, i still don't think not using DML limits HW advantage.
Regular FP16 (and lower?) math is ran on TCs on NV h/w but you don't get any h/w advantage from that, it runs at the same speed as FP32 (on Ampere) or twice that (on Turing), similarly to how it runs on FP16-capable GPUs without TCs. Ampere could probably run FP16 math in parallel with FP32/INT32 but I dunno if it does in practice. Seems like at the very least the code must be optimized for such option.If we do low precision math in a regular compute shader, Tensor Cores should process it, and there is and should be no need for DML?
It does FMAs, no matrix math. Thus TCs aren't actually used to their fullest potential this way.but we also know Turing does all fp16 on tensors
Similar threads
- Replies
- 30
- Views
- 14K