[Looking at the slides from Computerbase.de]
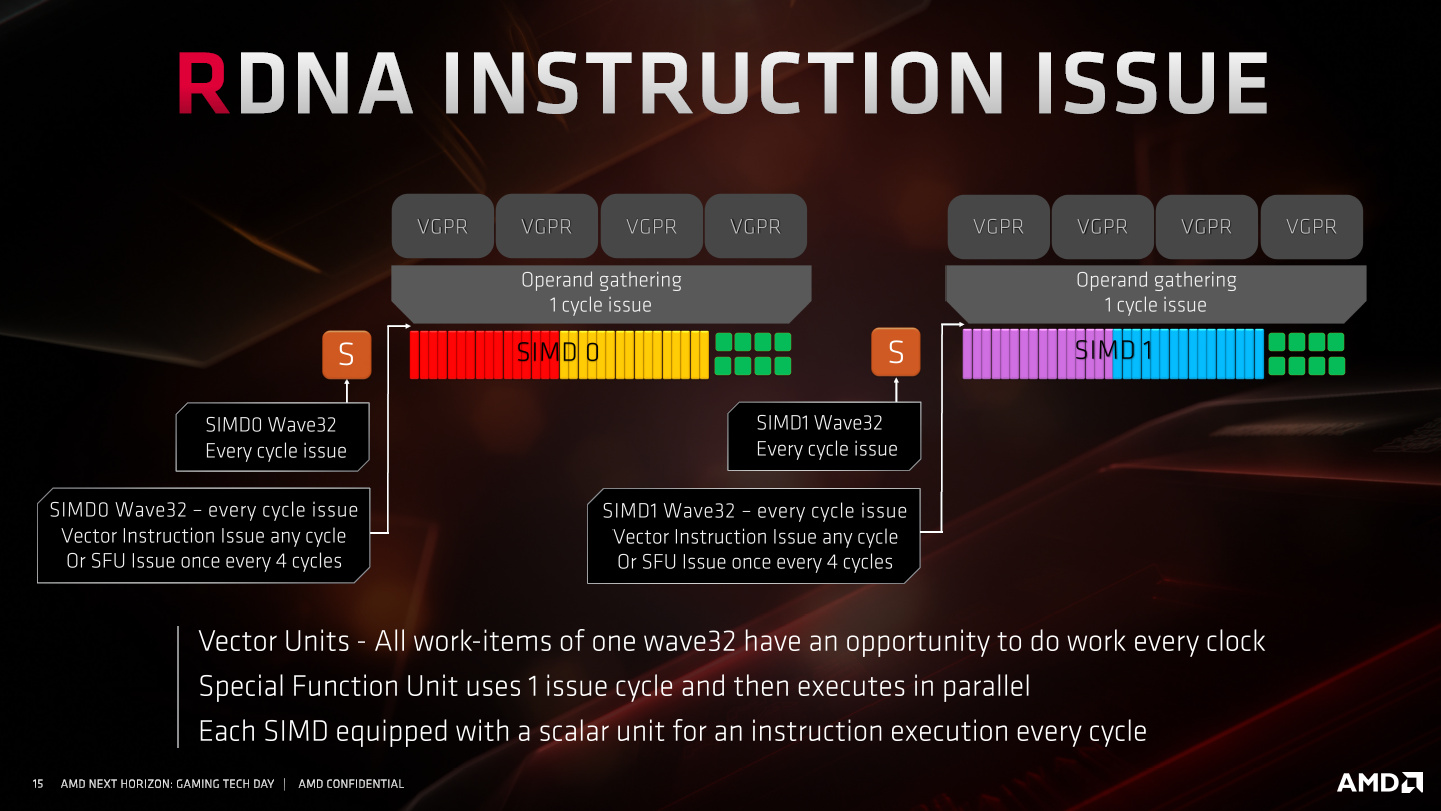
It seems the main benefit AMD is talking about is that heavy VGPR allocation threads will run with much less idle time, so shaders that allocate 64 VGPRs or more will no longer kill throughput if they are memory-intensive too. (GCN with only 2 hardware threads due to high VGPR or LDS allocation is quite happy as long as ALU:MEM ratio is fairly high, e.g. 20:1).
The pain point with GCN when it was introduced was that it was more sensitive to ALU:MEM ratio than the old VLIW machines. So this is a big deal: AMD will spend less time advising developers to watch out for VGPR allocations. NVidia solved this, eventually, by giving developers more VGPRs.
I'm not a fan of 32-wide hardware threads, even if there is a nice mapping to the bits of a DWORD, because a "square" (8x8) is often really good for breaking down work, and there's no square with a 32-wide thread. But 64 is still an option and a slide implies that in Workgroup Processor mode there are twice as many VGPRs available to each work group. So that's pretty spiffy!
This sounds like a fun machine to program: translation, they've given us a new exciting coarse-grained switch to play with, making the combinatorial space for algorithm optimisation twice as big...
Also AMD talks vaguely about spin-up and spin-down timings being better with this new design: the wider SIMDs help with that and the significantly denser scheduling hardware and caches, seemingly with no scheduler sharing even within the CU, let alone across CUs, should make time lost to short-lived and/or high-VGPR allocation threads much better.
So yeah, this really is a new hardware architecture for the CUs, not far off the change from VLIW to scalar when GCN launched.