How exactly is it the 'opposite' if ROCm only works on specific AMD HW (CPU/GPU/FPGAs) combinations with Broadcom (collaborative partner) PCIe switches ?It’s literally the first two paragraphs. Can you stop pretending you don’t understand what I’m referring to?
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD Execution Thread [2024]
- Thread starter del42sa
- Start date
- Status
- Not open for further replies.
DmitryKo
Veteran
How exactly is it the 'opposite' if ROCm only works on specific AMD HW (CPU/GPU/FPGAs) combinations
She laid down an AMD AI landscape that is polar opposite to Nvidia’s proprietary approach.
In her view, customers have a choice: choose a dystopian Nvidia world in which the company owns the assets, or select AMD’s world, where you can select your partners, hardware, technologies, and AI tools.
Isn't that a reference to Nvidia's current 'hardware subscription' model, where Nvidia is installing their own DGX-series supercomputers at major data centers to charge customers a $4500 yearly usage fee per each GPU?

Nvidia plans subscription-fueled journey to $1tr revenue
Think about Tesla charging extra for features like Autopilot, then look at your GPU card, and you'll get the idea
 www.theregister.com
www.theregister.com

Nvidia’s subscription software empire is taking shape
$4,500 per GPU per year adds up pretty quick – even faster when you pay by the hour
www.theregister.com
Last edited:
D
Deleted member 2197
Guest
Could be. Nvidia adopted the Oracle (database companies, etc..) subscription model for companies choosing to host their AI Enterprise product suite remotely at major data centers instead of locally on their corporate computers. Since they Nvidia and Oracle have a partnership I would guess the subscription is a carryover from Oracle's per CPU usage fee. Outside the database subscription, Oracle's product suite also includes a wide range of applications for federal, heathcare, manufacturing, etc... that run on their database. For companies choosing DYI applications usually become overwhelmed by the amount of annual updates required to maintain a reliable, functioning system.Isn't that a reference to Nvidia's current 'hardware subscription' model, where Nvidia is installing their own DGX-series supercomputers at major data centers to charge customers a $4500 yearly usage fee per each GPU?
All of the large consulting companies (Arthur Anderson, Booze Hamilton, etc..) also have subscription models for their Enterprise product suites. The amount of annual updates required by these products (especially latest Govt., and Federal changes affecting many industries) is well beyond the capability of most company's ability to maintain on an annual basis and the primary reason clients chose subscription based data center applications. Unfortunately consulting companies are getting on the AI bandwagon and now offering AI enterprise suites.
Last edited by a moderator:
DmitryKo
Veteran
ROCm only works on specific AMD HW (CPU/GPU/FPGAs) combinations
Well, HIP is not limited to AMD hardware, the runtime can also run on NVidia hardware conforming to CUDA 6.0 or later - so if you program CUDA directly, you can convert your code to HIP and it will still run on NVidia hardware (though HIP is a subset of CUDA, so you will probably lose some functionality).
You will also need to port your code to hip* versions of common math libraries (BLAS, RAND, SOLVER, SPARSE) - but these will also run on NVidia hardware by redirecting to standard cu* versions.
So at least it's more portable comparing to CUDA, which is firmly locked to NVidia's own hardware.
And if you're building your ML models with high-level frameworks like ONNX, PyTorch and TensorFlow, these days you should be able to run them on either CUDA or HIP/ROCm hardware (unless you specifically require a recent version that hasn't been ported to ROCm yet).
Companies couldn't even build their local HPC clusters lately because of NVidia's GPU shortages, as shipping dates would slip by several months. That's why NVidia's customers were forced to either turn to their hardware subscription model, or consider alternative platforms.Nvidia adopted the Oracle subscription model (database companies, etc..) for companies choosing to host their products remotely at major data centers
BTW Business Insider published an interview with AMD's head of AI in July, and it does put a similar emphasis on ROCm as an 'open-source' alternative to NVidia's ecosystem - but of course you should treat it as a marketing pitch rather than a technical statement. The intention was obviously to take advantage of GPU shortages and make people in charge reconsider AMD platforms, not provide fine technical details to engineers maintaining actual software...

AMD has an open-source plan to compete with NVIDIA
At the recent Reuters' Momentum AI conference in San Jose, California, Ramine Roane, AMD's corporate vice president of data center,
How exactly is it the 'opposite' if ROCm only works on specific AMD HW (CPU/GPU/FPGAs) combinations with Broadcom (collaborative partner) PCIe switches ?
That’s a question for the articles author.
Isn't that a reference to Nvidia's current 'hardware subscription' model, where Nvidia is installing their own DGX-series supercomputers at major data centers to charge customers a $4500 yearly usage fee per each GPU?
At the last earnings call Nvidia downplayed the scope of its involvement in systems integrations. They claim their business is all about providing technology at every level of the stack and leaving integration up to partner ODMs. I doubt very much that “Nvidia’s model” here refers to fully integrated solutions that they provide since it’s supposedly not a large part of their business.
The part that’s opposite to what AMD is proposing is that Nvidia provides nearly all of the tech required up and down the stack. They’re a one stop shop and don’t need to negotiate interfaces or timelines with anyone else (aside from their own component suppliers of course).
You can auto-generate certain subsets of CUDA compatible code from HIP code or vis a vis but that doesn't ultimately change the fact that you as a developer have to do QA testing for each of these platforms (CUDA/ROCm) on a separate basis because they have incompatible runtimes/compilers (ROCr/HIP-CLANG vs CUDA/NVCC) and different programming features/paradigm (inline assembly vs intermediate representation/wave64 vs wave32/more SIMD functions vs independent thread scheduling/etc) ...Well, HIP is not limited to AMD hardware, the runtime can also run on NVidia hardware conforming to CUDA 6.0 or later - so if you program CUDA directly, you can convert your code to HIP and it will still run on NVidia hardware (though HIP is a subset of CUDA, so you will probably lose some functionality).
You will also need to port your code to hip* versions of common math libraries (BLAS, RAND, SOLVER, SPARSE) - but these will also run on NVidia hardware by redirecting to standard cu* versions.
So at least it's more portable comparing to CUDA, which is firmly locked to NVidia's own hardware.
On a surface level (HLL source code/compatible subsets of APIs) you might be able pigeonhole some trivial commonality between them but AMD are absolutely expecting you to do manual coding/performance tuning especially if you want to use mutually exclusive extensions between CUDA or HIP. HIP is not an API designed to where you can just make the "write once, run everywhere" approach viable in every case. HIP softens the barrier to cross-platform development but you absolutely do need to do independent building/testing for them ...
QA usually are different People than devs. And test shall be HW agnostic.You can auto-generate certain subsets of CUDA compatible code from HIP code or vis a vis but that doesn't ultimately change the fact that you as a developer have to do QA testing for each of these platforms (CUDA/ROCm) on a separate basis because they have incompatible runtimes/compilers (ROCr/HIP-CLANG vs CUDA/NVCC) and different programming features/paradigm (inline assembly vs intermediate representation/wave64 vs wave32/more SIMD functions vs independent thread scheduling/etc) ...
On a surface level (HLL source code/compatible subsets of APIs) you might be able pigeonhole some trivial commonality between them but AMD are absolutely expecting you to do manual coding/performance tuning especially if you want to use mutually exclusive extensions between CUDA or HIP. HIP is not an API designed to where you can just make the "write once, run everywhere" approach viable in every case. HIP softens the barrier to cross-platform development but you absolutely do need to do independent building/testing for them ...
Can they even guarantee testing on an application level to be hardware agnostic when you can implement potentially different code (algorithms & data structures)/undefined behaviours/features/etc. between these different platforms ?QA usually are different People than devs. And test shall be HW agnostic.
Speaking from direct experience, there's a limit on how much hardware any rationally sized QA team can actually test. Beyond a moderate handful of primary use cases, you can only test aginst items which should be indicative of the larger population. Eg you shouldn't need to test a 3050, 3050 mobile, 3060, 3060Ti, 3060 Mobile, 3070, 3070 Ti, 3070 Mobile, 3070 Super, 3070 Ti Super, 3070 Mobile Super.... You should be able to test against a single 3000-series video card, and when it works, make a rational assertion the rest of the 3000-series cards should repeat the same behavior and call it good. Same goes for CPU types (eg a single 14700 should suffice for the entire 14xxx line of 20-something CPUs.)
So, it's entirely possible one software can be tested against the majority of hardware cases, allowing for proxy substitutions. Reality will sneak in and still break things, as a function of driver changes, firmware changes, underlying system configuration changes, OS changes, and I'm sure another two dozen things I'm simply just not thinking about at this exact moment.
So, it's entirely possible one software can be tested against the majority of hardware cases, allowing for proxy substitutions. Reality will sneak in and still break things, as a function of driver changes, firmware changes, underlying system configuration changes, OS changes, and I'm sure another two dozen things I'm simply just not thinking about at this exact moment.
Someone in this thread mentioned other backends. Seems that vLLM catched up.
D
Deleted member 2197
Guest
I think they tested using A100s & H100s and did not use TensorRT LLM due to support issues.Someone in this thread mentioned other backends. Seems that vLLM catched up.
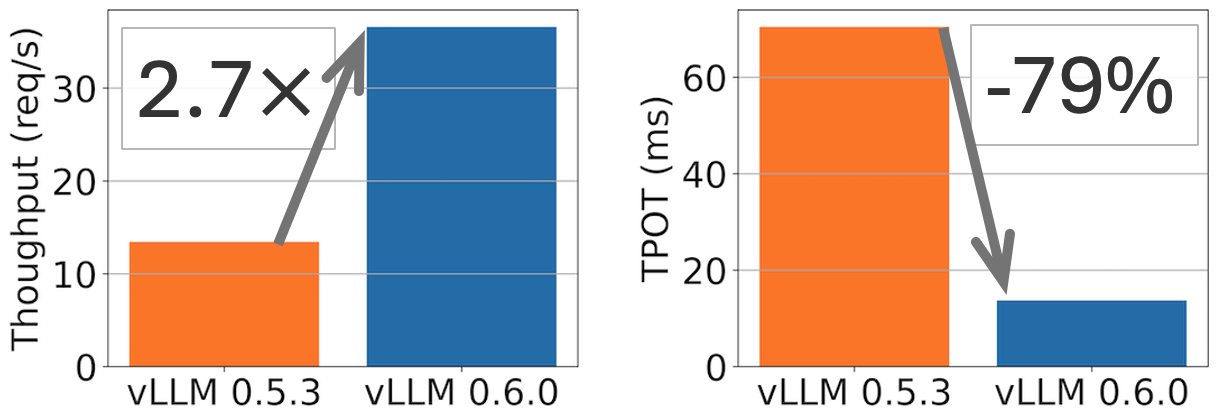
vLLM v0.6.0: 2.7x Throughput Improvement and 5x Latency Reduction
TL;DR: vLLM achieves 2.7x higher throughput and 5x faster TPOT (time per output token) on Llama 8B model, and 1.8x higher throughput and 2x less TPOT on Llama 70B model.
blog.vllm.ai
DegustatoR
Legend

AMD deprioritizing flagship gaming GPUs: Jack Huynh talks new strategy against Nvidia in gaming market
The battle seems to be over before it starts.
digitalwanderer
Legend
Is this new? I can't recall the last time AMD really tried to make a top end card. They always seem to go for middle-high end at best and their strength has been their mid-tiers for a while, 'til last gen or so. :sAMD deprioritizing flagship gaming GPUs: Jack Huynh talks new strategy against Nvidia in gaming market
The battle seems to be over before it starts.www.tomshardware.com
to me this is spelling out the narrative well after the corresponding the products decisions have been taken.
I guess lowering the expectations of consumers could be a good ideea, given how it played out with previous launches. (even including Zen 5 with even AMD having some slides that incorrectly stated they've launched the best gaming cpu ( or something like that ))
I guess lowering the expectations of consumers could be a good ideea, given how it played out with previous launches. (even including Zen 5 with even AMD having some slides that incorrectly stated they've launched the best gaming cpu ( or something like that ))
Frenetic Pony
Veteran
to me this is spelling out the narrative well after the corresponding the products decisions have been taken.
I guess lowering the expectations of consumers could be a good ideea, given how it played out with previous launches. (even including Zen 5 with even AMD having some slides that incorrectly stated they've launched the best gaming cpu ( or something like that ))
Yeah this is just PR controlling the narrative as to why RDNA4 doesn't have a flagship, you get out ahead of it and everyone believes you. Then when RDNA5 has a flagship you spin a new story

DavidGraham
Veteran
Yep, it's pretty evident it's PR when he rationalizes going for the best in AI while not doing the same for graphics!Yeah this is just PR controlling the narrative as to why RDNA4 doesn't have a flagship
It's like the AI side doesn't have a developer element while the consumer side does! Oh really?Here's the thing: In the server space, when we have absolute leadership, we gain share because it is very TCO-based [Total Cost of Ownership]. In the client space, even when we have a better product, we may or may not gain share because there's a go-to-market side, and a developer side; that's the difference.
Then he says this false thing:
Even Microsoft said Chat GPT4 runs the fastest on MI300
Which isn't surprising given the recent AMD marketing problems in RDNA3 and Zen 5 (their people must really lack base line accuracy), Microsoft only said MI300 is the best price to performance inference solution for GPT4. They said nothing about it being the fastest.
Also what the hell is that?
Last edited:
This sounds oh-so-similar to PR that accompanied Navi 10 in 2019 (post-Vega), which in turn was an almost verbatim rehash of 2016 talking points that accompanied RX 480 launch (post-Fury). Which of course drew inspiration from 2007 and RV670 “midrange dominance” strategy (post-R600).
Call me foolish, but I honestly believe that AMD’s penchant for declaring that they “don’t want to play in that sandbox anyway” and abandoning high-end after a generation underperforms (for either technological or marketing reason) has been a major obstacle for them making the consistent market share gains. As many misses as Nvidia had, the users never had to wonder whether they would have to wait 3-4 years until a next high-end part comes along.
Call me foolish, but I honestly believe that AMD’s penchant for declaring that they “don’t want to play in that sandbox anyway” and abandoning high-end after a generation underperforms (for either technological or marketing reason) has been a major obstacle for them making the consistent market share gains. As many misses as Nvidia had, the users never had to wonder whether they would have to wait 3-4 years until a next high-end part comes along.
Call me foolish, but [...] abandoning high-end after a generation underperforms (for either technological or marketing reason) has been a major obstacle for them making the consistent market share gains.
It's a very reasonable assumption actually. However, doesn't mean the extra market share that would have been gained or at least preserved that way is enoungh to offset the overall investment costs in the high end part
As I stated elsewhere, this is a good move for amd. Their current trajectory has them losing market share and mindshare because it sends the impression they keep falling short of the competition.
If they shift their messaging and product lineup to best value similar to early Zen generations they can generate a lot of positive buzz and sales momentum.
If they shift their messaging and product lineup to best value similar to early Zen generations they can generate a lot of positive buzz and sales momentum.
- Status
- Not open for further replies.
Similar threads
- Replies
- 70
- Views
- 13K
- Replies
- 17
- Views
- 5K
- Replies
- 4K
- Views
- 543K
D