You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD Execution Thread [2023]
- Thread starter Kaotik
- Start date
- Status
- Not open for further replies.
Silent_Buddha
Legend
And labour costs are one of the biggest factor. No company is letting their high paid employees sitting around doing nothing because they have to wait twice as long for a result.
Twice as long is nothing in the sector this is relevent for. There it's all about whether something is an order of magnitude (10x) slower or faster. In that world programming ease and implementation is far more important that a measly 2x improvement in execution speed.
It's one reason why Python and now PyTorch is the king. They aren't the fastest languages in terms of execution but they are the fastest and easiest WRT programming and implementation across a broad spectrum of R&D efforts (corporate and research institutions).
Regards,
SB
D
Deleted member 2197
Guest
Nvidia runs quite well with PyTorch and since October PyTorch also supports CUDA, so compute optimizations are available.
I couldn't find the price for them. How much more expensive are the AMD chips compared to Nvidia H100?MI300 is much more expensive
Nvidia runs quite well with PyTorch and since October PyTorch also supports CUDA, so compute optimizations are available.
Yes, just repeating myself here, right now in inference the platform that people are using is PyTorch, with vLLM and running on NVidia hardware. That's where AMD needs to be good at to compete, and other platforms and workloads just matter a lot less.
I think that MI300X will do well enough there to sell everything AMD is going to build, but at much worse margins than NV because it clearly is a more expensive product to build that what it's competing against. Which is probably why AMD didn't go all out making a lot more of them. Still, if they can sell a few B worth of them and get them widely used, it will potentially be very good for them going forwards, as it would mean they are going to be able to compete on a level playing field with good software support.
Thats not how GPGPU works. You need optimize software for accelerators. Otherwise companies just wasting money. This is the reason why nVidia has invested so much money into software. Even processors with less (hardware) performance can be competitive when your software is more efficient. AMD must spend twice as much ressource to be barely faster. nVidia can invest these ressources into a CPU and sell the package for a similiar price. AMD customers have to decide to go with MI300X and still have to invest into the host-system or go with MI300A and getting worse performance with only 1/4 of the memory of GH200.Twice as long is nothing in the sector this is relevent for. There it's all about whether something is an order of magnitude (10x) slower or faster. In that world programming ease and implementation is far more important that a measly 2x improvement in execution speed.
It's one reason why Python and now PyTorch is the king. They aren't the fastest languages in terms of execution but they are the fastest and easiest WRT programming and implementation across a broad spectrum of R&D efforts (corporate and research institutions).
Regards,
SB
Last edited:
So GH200 with 4 times memory with what bandwidth?Thats not how GPGPU works. You need optimize software for accelerators. Otherwise companies just wasting money. This is the reason why nVidia has invested so much money into software. Even processors with less (hardware) performance can be competitive when your software is more efficient. AMD must spend twice as much ressource to be barely faster. nVidia can invest these ressources into a CPU and sell the package for a similiar price. AMD customers have to decide to go with MI300X and still have to invest into the host-system or go with MI300A and getting worse performance with only 1/4 of the memory of GH200.
Wut?So GH200 with 4 times memory with what bandwidth?
GH200 HBM3E Superchip has total of 5.5 TB/s mem bandwidth, split at 5 TB/s HBM3E and 512 GB/s LPDDR5X. That's far cry from "4 times memory bandwidth" compared to 5.3 TB/s of MI300X or MI300A
GH200 has 3.2x (MI300X) or 4.8x (MI300A) the memory, but 480 GB of it is behind just 512 GB/s bandwidth, 141 GB (which is less than MI300X but more than MI300A) behind 5TB/s
(late edit: I blame alcohol and other intoxicants if I missed obvious sarcasm)
Last edited:
I was talking to troyan. He complained about memory capacity.Wut?
GH200 HBM3E Superchip has total of 5.5 TB/s mem bandwidth, split at 5 TB/s HBM3E and 512 GB/s LPDDR5X. That's far cry from "4 times memory bandwidth" compared to 5.3 TB/s of MI300X or MI300A
GH200 has 3.2x (MI300X) or 4.8x (MI300A) the memory, but 480 GB of it is behind just 512 GB/s bandwidth, 141 GB (which is less than MI300X but more than MI300A) behind 5TB/s
(late edit: I blame alcohol and other intoxicants if I missed obvious sarcasm)
I somehow missed the "what" portion there, see my late edit which was still in time for your quoteI was talking to troyan. He complained about memory capacity.

Bondrewd
Veteran
Well no, you're limited by NVL-C2C quirks quite heavily, and 512GB/s is only for 120/240GB SKUs.of it is behind just 512 GB/s bandwidth
512GB Grace uses 6400 ICs; all in NV's Grace technical manual.
DavidGraham
Veteran
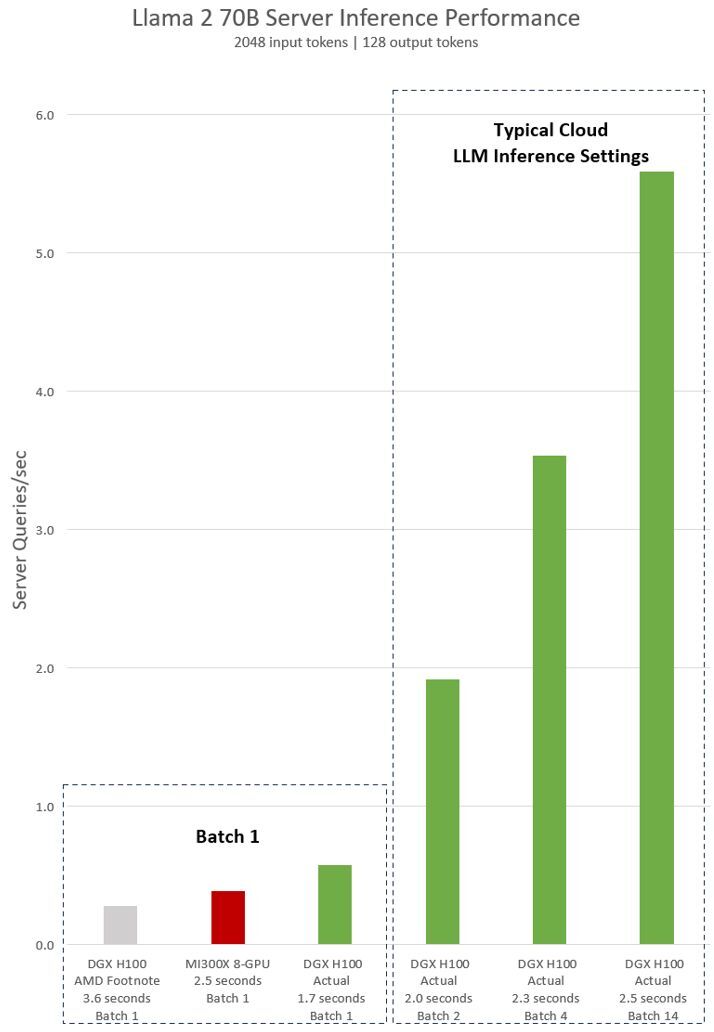
NVIDIA published their numbers for the inference benchmarks AMD used in their presentation. NVIDIA claims AMD results didn't use properly optimized code.

 developer.nvidia.com
developer.nvidia.com
At a recent launch event, AMD talked about the inference performance of the H100 GPU compared to that of its MI300X chip. The results shared did not use optimized software, and the H100, if benchmarked properly, is 2x faster.
Achieving Top Inference Performance with the NVIDIA H100 Tensor Core GPU and NVIDIA TensorRT-LLM | NVIDIA Technical Blog
Best-in-class AI performance requires an efficient parallel computing architecture, a productive tool stack, and deeply optimized algorithms. NVIDIA released the open-source NVIDIA TensorRT-LLM…
developer.nvidia.com
Last edited:
Bondrewd
Veteran
little did Nvidia know you can also amp batch sizes on MI300X; the thing has 304 CUs after all.NVIDIA published their numbers for the inference benchmarks AMD used in their presentation. NVIDIA claims AMD results didn't use properly optimized code.
Achieving Top Inference Performance with the NVIDIA H100 Tensor Core GPU and NVIDIA TensorRT-LLM | NVIDIA Technical Blog
Best-in-class AI performance requires an efficient parallel computing architecture, a productive tool stack, and deeply optimized algorithms. NVIDIA released the open-source NVIDIA TensorRT-LLM…
Was clear from AMD's own numbers. Even nVidia claims that one H200 is 1.9x faster in Llama than H100. Like is said: MI300 is the bottom for AMD. I only hope it can go better from now on.NVIDIA published their numbers for the inference benchmarks AMD used in their presentation. NVIDIA claims AMD results didn't use properly optimized code.
Achieving Top Inference Performance with the NVIDIA H100 Tensor Core GPU and NVIDIA TensorRT-LLM | NVIDIA Technical Blog
Best-in-class AI performance requires an efficient parallel computing architecture, a productive tool stack, and deeply optimized algorithms. NVIDIA released the open-source NVIDIA TensorRT-LLM…
D
Deleted member 2197
Guest
Well one discussion both IHV's can't lie about is when reliable testing comes out from third parties. AMD's internal gpu benchmarks (gaming, ML, AI) I always take with a "grain of salt" since they rarely present a true performance scenerio versus what rival is capable of. Looking forward to the MLPerf benchies ...
D
Deleted member 2197
Guest
AFAIK, I don't think AMD has ever participated in any MLPerf which is a shame since they won't be able to compare performance uplifts against the previous generations.MLPerf was created to prevent these problems.
Last edited by a moderator:
DavidGraham
Veteran
With significantly more performance deficit. With optimized software batch 1, the H100 is 47% faster in Inference. I imagine with larger batches it's probably even faster.little did Nvidia know you can also amp batch sizes on MI300X; the thing has 304 CUs after all.
Last edited:
- Status
- Not open for further replies.
Similar threads
- Replies
- 18
- Views
- 7K
- Replies
- 97
- Views
- 18K
- Replies
- 33
- Views
- 6K
- Replies
- 21
- Views
- 5K