OK but that's true for every CPU, no? So far I read nothing that let me think that xenon is different from any other Power PPC in this regard.CPU is a critical part of the security system. It has *lots* of security specific features.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD/ATI for Xbox Next?
- Thread starter AzBat
- Start date
corduroygt
Banned
I think what everyone means when they say "x86" is a kick-ass OoOE Intel CPU.I doubt the "x86" ISA itself actually takes up much space.
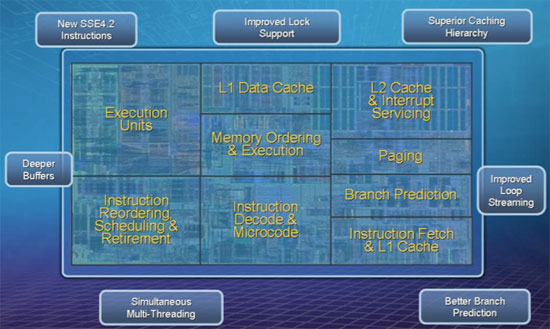
Would the x86 ISA be the part where it says instruction decodeµcode? That looks like 10-15% of one core to me. I think it'd add up if you had many cores.
I also think that the more complex cores with the instruction ordering logic should be kept to a minimum, I'd say 4 would be enough. So you could make something like 2 GP cores + 48 stripped down cores + some gpu logic to have one monster all in one CPU+GPU.
OK but that's true for every CPU, no? So far I read nothing that let me think that xenon is different from any other Power PPC in this regard.
What do typical cpu's have apart from a bog standard MMU? Did you see the video that was linked earlier?
Does every CPU perform *full* memory encryption, and maintain hashes of every cacheline on chip, have a per box encryption key of flash etc. etc. ?
Would the x86 ISA be the part where it says instruction decodeµcode? That looks like 10-15% of one core to me. I think it'd add up if you had many cores.
Well, clearly things have changed over the years with 32-bit/64-bit/registers/SSE/MMX/vectors extensions etc. I was referring to your comment about 20-years old... so... the 20-year old x86 at that time.
Hum, no... my bad I searched too quickly I guess I'll go back more carefully in the thread.What do typical cpu's have apart from a bog standard MMU? Did you see the video that was linked earlier?
Does every CPU perform *full* memory encryption, and maintain hashes of every cacheline on chip, have a per box encryption key of flash etc. etc. ?
Sorry for the insistence
Seems like ealy talk about bulldozer were spot on
AMD (for once) looks in line to deliver the good in 2010 (say end of 2010) whether it's fusion, bobcat (low power cpu core touted as 90% as efficient as nowaday CPU but in 50% the die size) and bulldozer.
They also stated that fusion, CPU/fusion will be very configurables.
Now I'm really willing to know what MS decided... I feel like somebody is playing with my nerves.
AMD (for once) looks in line to deliver the good in 2010 (say end of 2010) whether it's fusion, bobcat (low power cpu core touted as 90% as efficient as nowaday CPU but in 50% the die size) and bulldozer.
They also stated that fusion, CPU/fusion will be very configurables.
Now I'm really willing to know what MS decided... I feel like somebody is playing with my nerves.
Last edited by a moderator:
They also stated that fusion, CPU/fusion will be very configurables.
I wonder... I was just thinking of an MCM package consisting of a CPU/Shader die and the eDRAM/ROP die...
First a slide is better than my sub part englishI wonder... I was just thinking of an MCM package consisting of a CPU/Shader die and the eDRAM/ROP die...

In regard to Edram and future GPUs, I think AMD is to pass and MS too.
I still have no proper response about some questions I had around my head (I consider asking my post to be moved) but one of the question could be resume in something like "in the near future what will prevail many core GPU or multicore GPU"? (I still have no response in this regard tho
)When I say multi-core I mean multiple fully fledge GPU (dedicated CP, thread dispatcher, etc.).
Basically Intel is following the "many-core" path I should reread Fermi presentation (i'm a bit in the dark here), I think AMd will go the "multi cores".
The fusion relies on some memory controller, Anand goes as far as stating that L3 should shared between APU. My idea after trying to figure out what are GPU actual lacking could be something like this:
*AMD could built "tiny complete GPU" as building block instead of array.
If I compare a RV8xx to some phenom II of the same size (given the healthy amount of memory in GPU it's close to be fair) I would say a redone of RV8xx may be done out of 4 GPUs. I think it's likely for the CPU and the GPU core to be around the same size, modularity seems important to AMD and it should save themselves some troubles by doing so.
So if it were to be done now a tiny GPUs could be made of a Command Processor, a Thread-dispatcher, 4 SIMD arrays and 2 RBE tied to their "local" part of the L2.
In the future I think they should dump the RBE as Intel and move to tile/bin based deferred renderer. They should have more generic caches.
By having less cores ATi could let some "communication headache" that Intel has to face with Larrabee aside for a while, say you have 4 CPUs 8 GPUs and have a coherent memory model it's still a lot but it's still less bothering than dealing with 32 cores (or more).
AMD has hinted that they present unexpected advancements on the multi-GPUs front, I think the new informations we have may make things clearer. In not that far future I could see the Command Processor go through a significant evolution and be able to submit new tasks to himself and act more like a CPU or an autonomic VPU (better glossary/nomenclature wanted...). It will also have to work with CPUs and GPUs.
I could see the CPUs and the GPUs running in a kind of runtime environment, both GPUs and CPUs could update a "task/command buffer" shared and present in L3 cache (not a huge one) or keep the new job for himself, may sets task priority or affinity (CPU/GPU), etc. and even steal job from another overbooked processor.
For the cache structure, I could see CPU and GPU having read/write access to their local share of L1 and L2 and to the L3, read only to other GPUs/CPUs L2.
EDIT
In the new slides ( here slide 2) AMD plan for "heterogeneous computing" for 2012, that could be in line with MS next system launch.
EDIT 2
Repi posted a new presentation on his blog and it's pretty enlightening
It's here
There is an interesting one in regard ot are current talk page 49 "we don't need a seperate CPU and GPU"
EDIT3
This is great, possibly a quad core (4Mo of L2) packed with possibly 480SP/ 6 SIMD arrays
This could give low end laptop/desktop gaming some fresh air

Last edited by a moderator:
I know some are really interested in seeing a single chip solution like Fusion. Yet the cost of 1 die = 2 smaller dies is huge. Further 2 dies allows more flexible memory configurations.
Yet with the small Bulldozer size cores, it would be interesting to see a multi-core Fusion for the CPU and continue with a discreet dedicated GPU die. Essentially use the GPU guts on the CPU die as a huge vector extension (use OpenCL as method to use code across all resources?), GPUish tasks that can benefit from being on-die with the CPU, etc. Having 1TFLOPs of on-die GPU with the CPU and another 3TFLOPs on a dedicated GPU w/ memory could offer a lot of flexiblity without going "full board" on a risky adventure (1 huge, hot chip with low yields, poorer use of wafer space, and throttled frequencies due to heat bested by more traditional 2 chip designs with higher frequencies, more execution units due to more area, and higher yields and fewer issues configuring a memory configuration that is GPU and CPU friendly within a single die limit).
I am curious what some of the devs think. e.g. sebbbi mentioned the issue of a dedicated GPU for GPGPU would resolve resource sharing contentions/latency--how about moving a small GPU on-die with fast access to read/write to L3?
Yet with the small Bulldozer size cores, it would be interesting to see a multi-core Fusion for the CPU and continue with a discreet dedicated GPU die. Essentially use the GPU guts on the CPU die as a huge vector extension (use OpenCL as method to use code across all resources?), GPUish tasks that can benefit from being on-die with the CPU, etc. Having 1TFLOPs of on-die GPU with the CPU and another 3TFLOPs on a dedicated GPU w/ memory could offer a lot of flexiblity without going "full board" on a risky adventure (1 huge, hot chip with low yields, poorer use of wafer space, and throttled frequencies due to heat bested by more traditional 2 chip designs with higher frequencies, more execution units due to more area, and higher yields and fewer issues configuring a memory configuration that is GPU and CPU friendly within a single die limit).
I am curious what some of the devs think. e.g. sebbbi mentioned the issue of a dedicated GPU for GPGPU would resolve resource sharing contentions/latency--how about moving a small GPU on-die with fast access to read/write to L3?
I know some are really interested in seeing a single chip solution like Fusion. Yet the cost of 1 die = 2 smaller dies is huge. Further 2 dies allows more flexible memory configurations.
Yet with the small Bulldozer size cores, it would be interesting to see a multi-core Fusion for the CPU and continue with a discreet dedicated GPU die. Essentially use the GPU guts on the CPU die as a huge vector extension (use OpenCL as method to use code across all resources?), GPUish tasks that can benefit from being on-die with the CPU, etc. Having 1TFLOPs of on-die GPU with the CPU and another 3TFLOPs on a dedicated GPU w/ memory could offer a lot of flexiblity without going "full board" on a risky adventure (1 huge, hot chip with low yields, poorer use of wafer space, and throttled frequencies due to heat bested by more traditional 2 chip designs with higher frequencies, more execution units due to more area, and higher yields and fewer issues configuring a memory configuration that is GPU and CPU friendly within a single die limit).
Pretty close to what I was thinking at the time. Looking at Xenos right now, the mother die is essentially shaders and texturing. The proximity to the eDRAM being necessary for communication and bandwidth between the two. A future die reduction might even see the Mother Die/Xenon being integrated first before the eDRAM due to the latter's complexity in manufacturing versus "regular" transistors.
Though I'm not too sure about the need for a full GPU die outside of this config, unless you are making a case for multi-"gpu" rendering (to get the most graphical oomph) or just having a second bigger die with more shaders for the sake of it. Of course, it'd depend on just how much they can cram into the CPU/shader die so as to determine what is "adequate" shader power vs having two large dice.
Actually it's unclear how much solid/beefy CPU core developers want
I post it again in some miss it it's from Repi's blog (Dice chief developer?)
Parallel Future of Game Engine
Clearly by the way he makes it sounds he (and others I guess) are willing to offload bunch (most?) of stuffs to the GPU. He clearly states that the "communication/latency/etc." overhead is not worse, he wants one chip
Basically the cell push them to keep the code running on the PPu minimal, bunchs of stuffs are done on SPU and GPU, the plan is to move even further. Repi doesn't look like he want a lot of CPU power.
I can see similitude in his take and other devs takes on the future.
EDIT A bit unclear what I mean is that the CPU part on a single die may end tinier than what it is in the die shot above. A single Bulldozer core (close to two cores actually) may deliver.
I post it again in some miss it it's from Repi's blog (Dice chief developer?)
Parallel Future of Game Engine
Clearly by the way he makes it sounds he (and others I guess) are willing to offload bunch (most?) of stuffs to the GPU. He clearly states that the "communication/latency/etc." overhead is not worse, he wants one chip
Basically the cell push them to keep the code running on the PPu minimal, bunchs of stuffs are done on SPU and GPU, the plan is to move even further. Repi doesn't look like he want a lot of CPU power.
I can see similitude in his take and other devs takes on the future.
EDIT A bit unclear what I mean is that the CPU part on a single die may end tinier than what it is in the die shot above. A single Bulldozer core (close to two cores actually) may deliver.
If 2 consoles are competing visually with the same $-budget, I don't think the $ spent on a single die solution will glean enough benefit to best a 2 die solution with discrete GPU and the axillary benefits.
I would guess 1 huge die, at the same price as 2 smaller dies, will have less aggregate area (mm^2), lower frequencies, and additional memory configuration issues. And that 2 die 1xCPU 1xGPU will win via bruteforce. It isn't like you can take 2x 300mm^2 chips and buy a 600mm^2 chip of equal performance/cost.
Ugh... Yes, I loath the idea of the entire CPU and GPU budgets being pinned down to single die constraints. If they are *bet* on the IHV selling hard the concept of "gained performance" through interdie communication to diminish the lack of brute performance.
I would guess 1 huge die, at the same price as 2 smaller dies, will have less aggregate area (mm^2), lower frequencies, and additional memory configuration issues. And that 2 die 1xCPU 1xGPU will win via bruteforce. It isn't like you can take 2x 300mm^2 chips and buy a 600mm^2 chip of equal performance/cost.
Ugh... Yes, I loath the idea of the entire CPU and GPU budgets being pinned down to single die constraints. If they are *bet* on the IHV selling hard the concept of "gained performance" through interdie communication to diminish the lack of brute performance.
If 2 consoles are competing visually with the same $-budget, I don't think the $ spent on a single die solution will glean enough benefit to best a 2 die solution with discrete GPU and the axillary benefits.
But if you're putting the shaders right next to the CPU, why bother with another die full of shaders again
Well no, of course not, a big a die is a big die on the wafer, but I was also trying to consider the bandwidth issues by now having more budget for eDRAM if the CPU/Shader die was adequate. But again, it largely depends on how much they can cram into the CPU die...I would guess 1 huge die, at the same price as 2 smaller dies, will have less aggregate area (mm^2), lower frequencies, and additional memory configuration issues. And that 2 die 1xCPU 1xGPU will win via bruteforce. It isn't like you can take 2x 300mm^2 chips and buy a 600mm^2 chip of equal performance/cost.
Well there's certainly the target resolution versus diminishing returns vs audience to consider too. 1080p isn't exactly cheap compared to 720p.Ugh... Yes, I loath the idea of the entire CPU and GPU budgets being pinned down to single die constraints. If they are *bet* on the IHV selling hard the concept of "gained performance" through interdie communication to diminish the lack of brute performance.
And there'd be some neat things to come out of DX11+ for shader AA at least.But if you're putting the shaders right next to the CPU, why bother with another die full of shaders againOr are you intending to replace the vector units with the GPU ALUs, which would still need a fairly beefy upgrade to support DP at a decent rate etc. At which point, you might as well be creating more flexible SPEs.
Why? Because developers can use the vector performance w/o the latency of going to an external GPU and/or contending with resources. It is heterogenous, but instead of PPE/SPE/GPU we are down to CPU/GPU and potentially a lot of code being OpenCL which runs on both. Some nifty stuff could be done CPU-die side, maybe even extensive pre-GPU graphics processing (or post processing!) and doing graphics work closely to the computational work of objects without sacrificing graphical performance.
You get a single die with a lower total performance you will have fewer GPU resources and will also have more contentions if you are doing more "CPU" stuff on your graphics-GPU.
I am just suggesting a "GPU" dedicated to be the CPU slave, be it from graphics or other tasks while still having a GPU dedicated to graphics.
And if we go 3D displays we may get graphics worse than this gen!Well there's certainly the target resolution versus diminishing returns vs audience to consider too. 1080p isn't exactly cheap compared to 720p.
itsmydamnation
Veteran
clocks could offset that assuming that its SOI and SOI gives the GPU part a clock boost over Bulk
clocks could offset that assuming that its SOI and SOI gives the GPU part a clock boost over Bulk
Bigger dies tend to clock lower though. Being next to a large CPU and cache probably won't help (or vice versa, sticking a hot GPU next to a CPU could be a problem for the CPU).
Joshua my feel is that to achieve better look/graphics developers and hardware has to move from the slave/master relation.
Propus is 170mm² @ 45nm with some "eyeballing" a fusion chip with the same number of array as the die shot above would be somewhere around 350mm². They implement it properly and we have a ~210mm² chip @32nm.
Say 200mm² => two cores + 16 SIMD arrays => GPU part takes ~3/4 of the die size.
16 SIMD array 150 mm², adding 100mm² it's 250mm² for the GPU die size it's about 26 SIMD arrays.
The chip will use better process, say they run the CPU part @2.6GHz and the GPU one @1GHZ.
So the chip achieve a theorical peak figure of: 26 ( SIMD) * 16 (quad per simd) * 4 (putting SP transcendental unit aside) * 2 (Flops per cycle) *1 (clock speed) = 3.3 TFLOPS
Now I remove 15% it's 2.8 TFLOPS
Say the "pure" GPU using another process as the same Flops/mm² density (more dense but clocked lower) it would have throughput of 3.3/250x300 4 TFLOPS. it's a 40% raw performance advantage but to achieve what the other chip does you need a bigger CPU (running the simulation) a bus fast enough, with really low latency , ensuring memory coherency. You would also want to keep the UMA => extra latency for the CPU to deal with when accessing/writing the RAM (mem controller mostly likely on the GPU). It's still not sure that the system can do what the other system does, it's less flexible.
In regard to cost (aiming at the same overall peak figure) it would be a CPU X mm² + 200 mm² GPU (250mm² -15% is 210 say the chip is tinier and can clock higher) with two cooling solution, a more complex mobo vs a 300 mm² chip with simple mob and one cooling solution.
I'm more and more sold on the idea
If I apply to the above fusion CPU (ie four cores overall 4MB of L2 and 8 SIMD array unknow clock speed). Eyeballing you may have 2 cores and +16 SIMD array (actually the CPU takes a bit more than a half of the die). Actually I considered upgrading my PC lately so I watch some Propus/athlon X4 620 review, the thing does pretty great with only 512KB of L2 per core (especially it should be even better with directx 11 threading model but that another story). So you may end with even more simd or use two better cores bulldozer.Repi said:In his presentation Repi at some point to take an example (sorry I can't copy paste)
2015 => 50TFLOPs
80% graphics
15% simulation
4% misc
1% game logic/glue
Then he says:
OOE cpus more efficient for the majority of their game code:
but for the vast majority of our FLOPs these are fully irrelevant
can evolve to a small dot in a sea of DP cores
In other word "no need for separate CPU and GPU
Propus is 170mm² @ 45nm with some "eyeballing" a fusion chip with the same number of array as the die shot above would be somewhere around 350mm². They implement it properly and we have a ~210mm² chip @32nm.
Say 200mm² => two cores + 16 SIMD arrays => GPU part takes ~3/4 of the die size.
16 SIMD array 150 mm², adding 100mm² it's 250mm² for the GPU die size it's about 26 SIMD arrays.
The chip will use better process, say they run the CPU part @2.6GHz and the GPU one @1GHZ.
So the chip achieve a theorical peak figure of: 26 ( SIMD) * 16 (quad per simd) * 4 (putting SP transcendental unit aside) * 2 (Flops per cycle) *1 (clock speed) = 3.3 TFLOPS
Now I remove 15% it's 2.8 TFLOPS
Say the "pure" GPU using another process as the same Flops/mm² density (more dense but clocked lower) it would have throughput of 3.3/250x300 4 TFLOPS. it's a 40% raw performance advantage but to achieve what the other chip does you need a bigger CPU (running the simulation) a bus fast enough, with really low latency , ensuring memory coherency. You would also want to keep the UMA => extra latency for the CPU to deal with when accessing/writing the RAM (mem controller mostly likely on the GPU). It's still not sure that the system can do what the other system does, it's less flexible.
In regard to cost (aiming at the same overall peak figure) it would be a CPU X mm² + 200 mm² GPU (250mm² -15% is 210 say the chip is tinier and can clock higher) with two cooling solution, a more complex mobo vs a 300 mm² chip with simple mob and one cooling solution.
I'm more and more sold on the idea
Similar threads
- Replies
- 43
- Views
- 8K
- Replies
- 34
- Views
- 3K
- Replies
- 223
- Views
- 20K