You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
3D Technology & Architecture
- Thread starter Frank
- Start date
Anarchist4000
Veteran
Because bus width is only part of the amount of bandwidth. A 32 bit bus can be faster than a 512 bit bus if you clock it high enough. AMD has been using relatively slow memory on the 2900 compared to faster memory being used on the 8800's.
Because bus width is only part of the amount of bandwidth. A 32 bit bus can be faster than a 512 bit bus if you clock it high enough. AMD has been using relatively slow memory on the 2900 compared to faster memory being used on the 8800's.
but GTS's memory clock is 1,6GHZ and 2900's is 1,65GHZ
I didn't get it
Memory bandwidth is only one factor out of many that affects graphics performance.
If given code that is limited by other factors, such as filtering or fill rate, then all the bandwidth in the world won't change anything.
R600's bandwidth may well be overkill in most situations, since competing boards do so well with less.
Since AMD is rather tight-lipped about the exact reason that R600 falls so short of peak in so many cases, it may be speculated that if it weren't for the excess bandwidth, it would be doing even worse.
If given code that is limited by other factors, such as filtering or fill rate, then all the bandwidth in the world won't change anything.
R600's bandwidth may well be overkill in most situations, since competing boards do so well with less.
Since AMD is rather tight-lipped about the exact reason that R600 falls so short of peak in so many cases, it may be speculated that if it weren't for the excess bandwidth, it would be doing even worse.
Last edited by a moderator:
chavvdarrr
Veteran
Since AMD is rather tight-lipped about the exact reason that R600 falls so short of peak in so many cases, it may be speculated that if it weren't for the excess bandwidth, it would be doing even worse.
yes, and Julidz asks "Why?"
So far afaik, tehre are the teories of "not enough tmu-power" and "ineffective due to non-scalar design" PS utilization, right?
Maybe also ineffective usage of highly hiped ring bus? Problems transfering between nodes? Ring bus so far looks unimpressive... I mean all ATi/AMD chips with ring bus were late to the market, and failed on price/performance/size vs NV ones.
Its suspicious - how come that after introducing this ring-bus all chips are postponed and postponed? Coincidense?
Because 320-bit is enough. It wouldn't help R600 even if it had a 1024-bit interface. The bottleneck is elsewhere.why isn't the 512bits from HD2900XT making the difference against 320bits from 8800GTS ?
That being said, I believe large caches will make a significant difference in the near future. Good cache hit ratios not only reduce bandwidth, it lowers texture filtering latency. This allows a more efficient use of the register file.
Does anyone know the sizes of R600's and G80's caches and register files?
That being said, I believe large caches will make a significant difference in the near future. Good cache hit ratios not only reduce bandwidth, it lowers texture filtering latency. This allows a more efficient use of the register file.
I don't believe this is going to happen: caches are generally a very inefficient scheme to reduce latency if you have ways to increase the number of outstanding transactions. It will never help to reduce latency for stuff that's not already in there, so for fresh data you'll always have bubbles. This is not the case with latency hiding FIFO's, where you have a linear trade-off between area and latency reduction. A cache is much more useful to reduce external bandwidth, but once you have decent hit rate, performance increase will be much less than linear.
Looking at CPUs, caches reduce latency by a factor of 100. Yes it's another context and yes CPU caches take a huge amount of die space, but reducing latency by a factor 100 sounds very efficient to me.I don't believe this is going to happen: caches are generally a very inefficient scheme to reduce latency...
True.It will never help to reduce latency for stuff that's not already in there...
Not true (in context). Prefetching significantly reduces the number of cold misses....so for fresh data you'll always have bubbles.
For every clock cycle you have to wait for a memory access, you need registers to store all temporary results. Yes it's a linear trade-off but one that rises very fast. With caches, every decrease in cache miss ratio increases the chances of being able to keep the ALUs busy. Correct me if I'm wrong, but as far as I know caches have a larger density than register files.This is not the case with latency hiding FIFO's, where you have a linear trade-off between area and latency reduction.
Anyway, I really don't know whether R600 is bottlenecked by this, or whether G80 is particularly efficient in this area...
Ok, I initially pointed this out, but then removed it because it's too obvious.Looking at CPUs, caches reduce latency by a factor of 100. Yes it's another context and yes CPU caches take a huge amount of die space, but reducing latency by a factor 100 sounds very efficient to me.
")
Come on, you know better than that: if there is no way to increase the number of fetching threads per core, a cache is the only option available, despite its inefficiency.
You can not prefetch what you don't know.Not true (in context). Prefetching significantly reduces the number of cold misses.
Let's guestimate a bunch of numbers.For every clock cycle you have to wait for a memory access, you need registers to store all temporary results. Yes it's a linear trade-off but one that rises very fast. With caches, every decrease in cache miss ratio increases the chances of being able to keep the ALUs busy.
Cache miss rate: 20%
Cache fetch latency: 5 cycles
Memory fetch latency: 100 cycles
Cache size: 16KB
-> Average latency: 24 cycles
You need 24 outstanding request to operate your engine at full speed. How much state do you have per thread? 16 32fp registers? That's 64 bytes per thread or 1536 for all threads.
If you double your cache, you can reasonably expect the miss rate to halve, so your average latency will become 14 cycles.
Cost: 16KB additional cache memory.
Savings: 608 bytes.
Given your Transgaming experience, I'm sure you can come up with more reasonable numbers wrt number of registers required etc, so feel free to adjust the numbers to your advantage.
But the general rule about all memory architectures is that caches are a terrible way to solve latency if other solutions are possible.
Yes, for multi-megabit caches. Hardly, for the little stuff we're talking about here.Correct me if I'm wrong, but as far as I know caches have a larger density than register files.
Last edited by a moderator:
Yes you can. Just guess the next address by looking at the access pattern history.You can not prefetch what you don't know.
Let's look at the chip as a whole. R600 can probably keep 1024 threads in flight with 16 scalars each? That's a 64 kB register file. Its L2 cache is 256 kB in total if I'm not mistaken.That's 64 bytes per thread or 1536 for all threads.
I'm not sure if that's true for the semi-ordered texture access pattern... unless with prefetching.If you double your cache, you can reasonably expect the miss rate to halve...
Why? If your data set fits in the cache then no RAM bandwidth is wasted and you need very little temporary registers. And with a well predictable access pattern using prefetching allows larger data sets while still only requiring minimal bandwidth and temporary registers.But the general rule about all memory architectures is that caches are a terrible way to solve latency if other solutions are possible.
The register file has three read ports and one write port, which makes it fairly complex as far as I know. The cache only needs just one read port. Furthermore with static CMOS a register is 10 transistors while SRAM is 6 transistors. And finally, cache cells are typically optimized for size with full custom design.Yes, for multi-megabit caches. Hardly, for the little stuff we're talking about here.
But please correct me if got some stuff wrong. I'm here to learn.
Jawed
Legend
Yep. Look at ATI's most recent texturing patent and you'll see it's explicitly designed to work in concert with rasterisation, i.e. "maximising prefetch" whilst also optimising memory access patterns (by organising cache in a 3-dimensional way). Sure that's a generalisation for what all texturing systems do, but they've spent yet more transistors making it work "better".Yes you can. Just guess the next address by looking at the access pattern history.
Woah! Way off.Let's look at the chip as a whole. R600 can probably keep 1024 threads in flight with 16 scalars each? That's a 64 kB register file.
In ATI terminology, R600 has "thousands of threads" in flight (sigh, maybe it's just 1001 threads, eh?) where each thread has 64 pixels (or vertices or primitives). So, call it 2048 threads, that's 131,072 pixels in flight. If there are 2 vec4 fp32 registers assigned per pixel, that's 16 bytes * 2 registers * 128000 pixels = 4MB of register file. I have to guess at 2 registers per pixel, it's not documented anywhere that I know of. It could be 1 or it could be more...
R580 can support 24,576 pixels in flight (512 threads, 48 pixels per thread), so for 2 vec4 fp32s, that's 16 bytes * 2 registers * 24576 = 1.5MB of register file for pixel shading (vertex shading is separate). Again, I'm guessing at there being support for 2 registers.
In both GPUs the register files are localised, so there's 4 separate main register files, one per SIMD.
That's just L2 for texturing. There's two distinct L1s, one for 2D texturing and one for vertex data (1D), both of which are backed by the 256KB of L2. Note L2 is prolly split 4 ways, one quarter per SIMD (where each SIMD has 1/4 of the 16 TMUs, i.e. 4). But to be honest I don't know of any confirmation of this.Its L2 cache is 256 kB in total if I'm not mistaken.
I'm not aware of any specific info for the organisation of R600's register files. Logically it needs the 3+1 organisation you describe because that's what a MAD is. But if you consider that R600 can co-issue a vec4 MAD and a SF, e.g. RCP, then it's a bit more fiddlesome. ARGH.The register file has three read ports and one write port, which makes it fairly complex as far as I know.
We know there's 32KB of "read/write cache" (split into four separate units, one per SIMD) that is somehow used to "re-order" register file reads and writes. But 8KB of cache is very small, per SIMD. A thread of 64 pixels, where each operand is vec4 fp32, consumes 4KB in 3 read operands and 1 written result.
http://forum.beyond3d.com/showpost.php?p=1006332&postcount=564
Ignore the last two paragraphs I wrote there.
This follow-up might help:
http://forum.beyond3d.com/showpost.php?p=1006344&postcount=567
You can also compare and contrast with G80's register file. That is documented as 512KB in size (split 16 ways) and note that operand and result register file bandwidth is not guaranteed by multi-porting:
http://forum.beyond3d.com/showpost.php?p=1012431&postcount=111
so it seems some slow-downs can only be explained by register file "conflicts".
Jawed
If the L2 is distributed in like manner as the TMUs, then 1/4 of each SIMD can access 1/4 of the L2, since 1/4 of each SIMD is tied to one of the 4 sampler units.That's just L2 for texturing. There's two distinct L1s, one for 2D texturing and one for vertex data (1D), both of which are backed by the 256KB of L2. Note L2 is prolly split 4 ways, one quarter per SIMD (where each SIMD has 1/4 of the 16 TMUs, i.e. 4). But to be honest I don't know of any confirmation of this.
A prefetcher after a cache tries to predict the next access based on previous miss. This works well enough for a linear case, where you can basically just overfetch, and in some cases you're even able to detected linked lists, but that's considered to be already really advanced stuff, yet it's still a 1D data structure.Yes you can. Just guess the next address by looking at the access pattern history.
A texture pattern is pretty much 3 dimensional: s,t and lod. Maybe you can come up with fancy storage patterns that allow you to fetch multiple directions in one go, but it won't be easy. And then there's tri-linear interpolation and AF.
And no matter what, speculative prefetches are, well, speculative. So when you're wrong, you've just wasted really valuable bandwidth.
Yes, sorry, my calculation above was just a general example with one executing engine, not really GPU tailored. When you have n parallel engines, you have to multiply the register size accordingly. This introduces a one time scaling of n in favor of a cache, but it also increase the chance of a cache hit when threads are grouped as quads. Good, because the 20% cache miss rate was too charitable for the cache case.Let's look at the chip as a whole. R600 can probably keep 1024 threads in flight with 16 scalars each? That's a 64 kB register file. Its L2 cache is 256 kB in total if I'm not mistaken.
Counter intuitively, higher hit rates favor the latency hiding fifo case, because they reduce the delta between the number of cycles for the average latency when you increase the cache. (See difference between avg. latency below)Just fill it in to a spreadsheet:
Code:
Miss Rate 5% 2.5% Delta
Cache latency 5 5
Mem latency 100 100
Cache Size 16384 32768 16384
Thread size 64 64
Avg latency 9.75 7.375
RF per engine 624 472
Nr of engines 64 64
Register file 39936 30208 -9728For a CPU, it generally is, until your core set of data basically fits the cache and your long term locality is fairly constant, as is the case for a CPU. There must be some different characteristics for textures, but it's probably a good enough approximation.I'm not sure if that's true for the semi-ordered texture access pattern... unless with prefetching.
But please correct me if got some stuff wrong. I'm here to learn.
You're fighting Amdahls law with a technique that scales exponentially in size. I'm doing it with a linear one.
The better you get at increasing hit rates, the tougher it becomes. When you increase shader clock speeds, memory latency will increase too and you'll need an even larger cache with only a statistical promise that your hit rate will improve and a guarantee that misses will always incur a latency hit. I just have to increase a FIFO and a register file and I'm guaranteed to solve the problem under all circumstances.
Just recreate the spreadsheet and play with it. I was surprised myself to see that the difference was so clear.
As for the implementation difference: the register files of R600 are a mystery. But since they have a cache, it's fair to assume that the main register file does not have 3 read ports and 1 write ports? Maybe they have been split up in multiple banks?
Jawed
Legend
In this diagram each L2 acts as an L3 for other L2s in the GPU:If the L2 is distributed in like manner as the TMUs, then 1/4 of each SIMD can access 1/4 of the L2, since 1/4 of each SIMD is tied to one of the 4 sampler units.
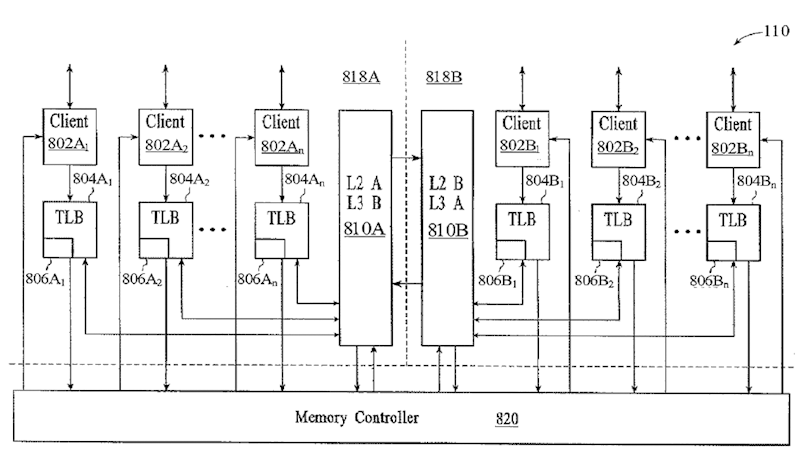
I don't know if this is how R600 works, but it seems likely if L2 is distributed 4 ways.
Jawed
Jawed
Legend
3-D rendering texture caching schemeA texture pattern is pretty much 3 dimensional: s,t and lod. Maybe you can come up with fancy storage patterns that allow you to fetch multiple directions in one go, but it won't be easy. And then there's tri-linear interpolation and AF.
A 3D rendering texture caching scheme that minimizes external bandwidth requirements for texture and increases the rate at which textured pixels are available. The texture caching scheme efficiently pre-fetches data at the main memory access granularity and stores it in cache memory. The data in the main memory and texture cache memory is organized in a manner to achieve large reuse of texels with a minimum of cache memory to minimize cache misses. The texture main memory stores a two dimensional array of texels, each texel having an address and one of N identifiers. The texture cache memory has addresses partitioned into N banks, each bank containing texels transferred from the main memory that have the corresponding identifier. A cache controller determines which texels need to be transferred from the texture main memory to the texture cache memory and which texels are currently in the cache using a least most recently used algorithm. By labeling the texture map blocks (double quad words), a partitioning scheme is developed which allow the cache controller structure to be very modular and easily realized. The texture cache arbiter is used for scheduling and controlling the actual transfer of texels from the texture main memory into the texture cache memory and controlling the outputting of texels for each pixel to an interpolating filter from the cache memory.
But in GPUs speculative should be a big win because texture data is highly regimented. Additionally it's possible to hide complex memory layouts for texture data, so whatever hare-brained scheme the GPU designers invent for the "tiling" of textures in GPU memory, the programmer doesn't have to mess about with this stuff to optimise cache line usage or whatever.And no matter what, speculative prefetches are, well, speculative. So when you're wrong, you've just wasted really valuable bandwidth.
Or, erm, put another way, this problem is abstracted for the programmer, they need to think in terms of being careful where they use high-quality texture filtering - e.g. not using anisotropic on ambient lighting textures (I think).
Jawed
Ok, so prefetching is doable. Good.
Anyway, I'm not saying caches aren't useful: they're excellent for bandwidth reduction and it makes perfect sense to have an L2 cache when you have separate texture units with their own non-linked L1 caches.
But for latency they're no good...
Just look at the numbers: I'm going from 9.8 to 7.4 cycles. Not really spectacular.
I'm a bit surprised by your number about the total numbers of threads in a GPU: this indicates that the number of threads required for texture fetch latency hiding is actually quite low relative to the total number of live threads (and makes the whole thead cost issue even more irrelevant).
Any idea why the other threads are needed? Trying to cover instruction dependencies would be one thing, of course. Anything else?
You're fighting Amdahls law with a technique that scales exponentially in size. I'm doing it with a linear one.
Preface: I agree that caching as a latency-hiding exercise is somewhat limited in GPU cases, but not without use.
However:
Your technique makes a point of not addressing Amdahl's law.
Amdahl's law specifically addresses the issue where greater parallel throughput results in diminishing returns as inherently serial execution takes up a larger proportion of the time.
To combat this, single-threaded performance must rise to deal with the serial portion.
Your technique maximizes parallel throughput at the cost of 1/n of serial performance.
You multiply the effect of any serial code by the length of the FIFO, which means in all but embarassingly parallel problems, the cost of serial code rises to offset any gains made by parallel latency hiding.
For a 24-cycle latency hiding, you made any serial dependency 24 times worse.
For graphics, this currently is likely a rare enough case that they do sift through threads regularly to hide latency.
This is no general solution, however.
Except in the case of synchronization or inter-thread dependencies.I just have to increase a FIFO and a register file and I'm guaranteed to solve the problem under all circumstances.
It's also not necessarily a win if power output and pinout is a concern. Any off-chip traffic that inevitably rises with additional threads costs power, and it increases the amount of bandwidth required for a given level of throughput.
My math may be off, but for R600, 4 sampler units*20 fp32 values*742 MHZ = 237,440,000,000 bytes per second.
That's twice what its expansive memory bus can supply.
To make up for this, R600's caching must be capable of hitting at least 50% of the time in order to make sustained performance possible in bandwidth-limited situations.
A FIFO without adequate caching as a general solution will wind up hitting other constraints. Too many independent threads can hurt locality, and can also run afoul of DRAM banking and other practical limitations.
If a design is not balanced, the consequences of too many poorly-serviced threads can favor a design that uses cache to limit the amount of time the chip stalls on dependencies and minimizes off-chip traffic. Texture fetches and filtering alone could balloon memory traffic to impossible levels without adequate caching.
Jawed
Legend
Yeah, but GPUs have never had texture cache for latency reduction - it's always been about bandwidth efficiency. When a texel is fetched its lifetime, per frame, is almost certainly over within a few clock cycles of it appearing in the texture mapping pipeline.But for latency they're no good...
Though the out of order threading model that Xenos, R5xx, R6xx and G8x use does sorta "muddle" things there somewhat.
Please note that "threads" here may not mean what you think: ATI defines a thread as a group of pixels, e.g. 64 in R600 (a batch, effectively). NVidia defines a thread as a pixel (or vertex or primitive).I'm a bit surprised by your number about the total numbers of threads in a GPU: this indicates that the number of threads required for texture fetch latency hiding is actually quite low relative to the total number of live threads (and makes the whole thead cost issue even more irrelevant).
With that said, it has now become clear that Xenos has a register file of ~300KB. I'll have a rummage to see if I can find where I saw this...
2 vec4s, as I described, is not enough for anything but the most trivial DX8 shader (as far as I can tell). Normal shader programs might have 4 or 12 or more vec4 registers defined. When you increase the register payload per pixel, you proportionally decrease the number of 64-pixel batches (threads in ATI terminology) that can occupy the full 4MB, say, of register file. A 12-register shader is 6x more registers than the example I gave, so that means 1/6th of the pixels can exist concurrently in the register file. So, 131,072 pixels in flight gets reduced to ~21,000. That's ~340 64-pixel batches. Split that 4 ways (for each SIMD) and that's ~85 batches. Each batch consumes 4 core clocks per instruction, so that's ~340 clocks of worst-case latency hiding. It's overkill.Any idea why the other threads are needed? Trying to cover instruction dependencies would be one thing, of course. Anything else?
But 12 registers isn't that many. SM3 requires a GPU to support 32 vec4s per pixel. SM4 requires 4096.
Also, you have other sources of latency in D3D10 GPUs, specifically constant fetches (it's not possible to hold all constants in on-die memory) and branching. Then you also have vertex data fetching.
And then you have the ebb and flow of workload across vertex shaders, geometry shaders and pixel shaders - the GPU needs to be able to hide "blips" in those queues.
So, all in all, you want the GPU to be tolerant of lots of unpredictable latency, whether it comes from DDR memory fetches, coding (branches + register bandwidth?) or peculiar workloads such as heavy duty geometry shading that generates a huge quantity of new vertices (bearing in mind that the GPU may not be able to consume vertices at the peak creation rate).
Jawed
Jawed
Legend
Lecture 12 here:[...] this indicates that the number of threads required for texture fetch latency hiding is actually quite low relative to the total number of live threads (and makes the whole thead cost issue even more irrelevant).
http://courses.ece.uiuc.edu/ece498/al/Syllabus.html
by Mike Shebanow elucidates very nicely on the topic of texture fetch latency hiding.
Jawed
Nick said:Looking at CPUs, caches reduce latency by a factor of 100. Yes it's another context and yes CPU caches take a huge amount of die space, but reducing latency by a factor 100 sounds very efficient to me.
How much cache do said CPU need to reduce latency by a factor of 100? Now consider that this number is only for a single thread. Is building a cache 100-1000000x larger to scale it up by the number of threads in flight on a GPU really worthwhile?
Similar threads
- Replies
- 66
- Views
- 3K
- Replies
- 34
- Views
- 4K
- Replies
- 21
- Views
- 2K
- Replies
- 21
- Views
- 3K