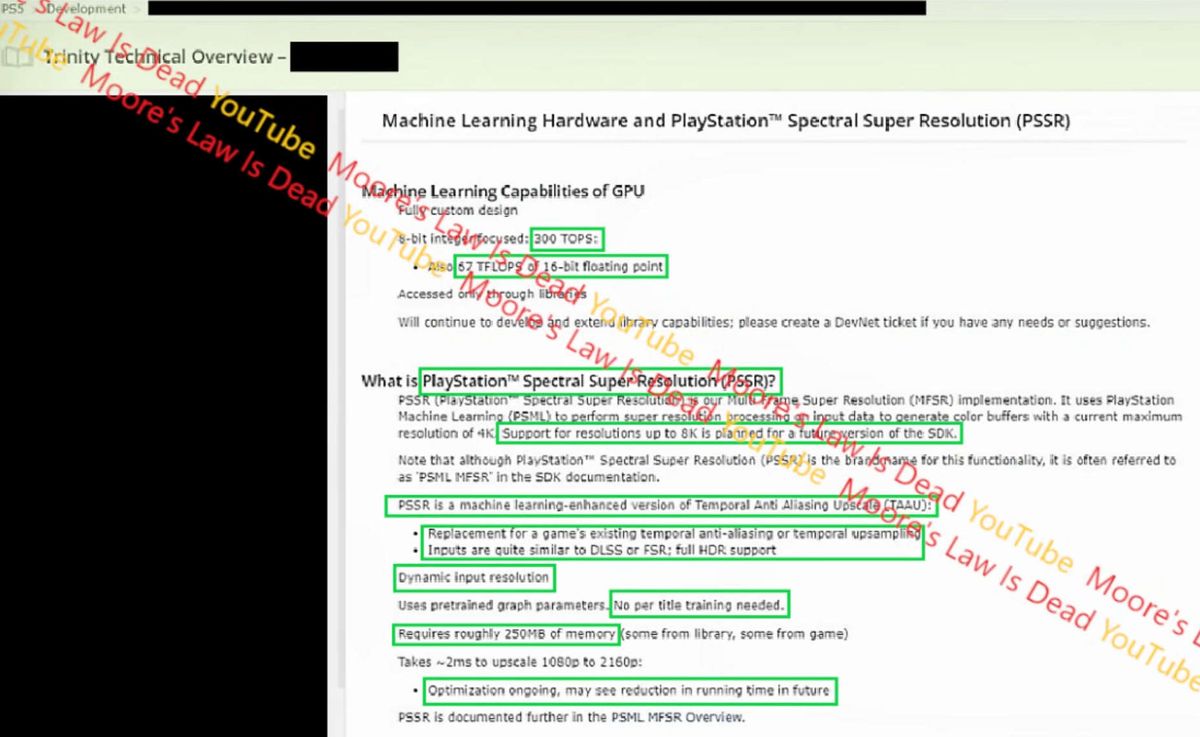
It's likely a result as of a lack of available bandwidth and not necessarily compute.
NN silicon require large caches to go significantly faster, and that's typical to find with Tensor Core style silicon (a 4070 has 36MB of L2, PS5 has 4MB, and XSX has 5MB respectively, 5Pro likely has 4MB of L2 as they kept their 256bit bus). In this case, if it's not available as the cost of building that type of cache into CUs would be costly, then you'd be hitting memory a lot more, overall reducing the available bandwidth available for both CPU + GPU. So once you have higher frame rate, combined with more trips to memory via RT and PSSR, what may be happening is a reduction of resolution in order for their to be sufficient bandwidth to keep the frame rate up.
I don't think it's a compute issue here for 5Pro. There's plenty of compute available, bandwidth is another issue, it's only marginally more bandwidth than PS5 and more or less the same bandwidth as XSX.
")