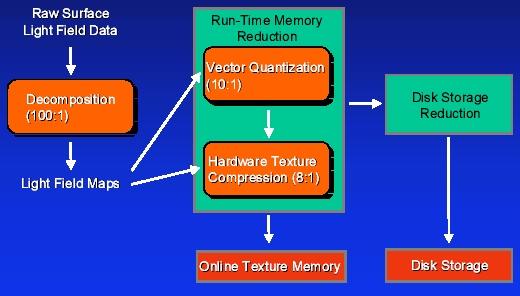
Dave B(TotalVR) said:
Personally I think VQ compression is great, sure comrpessing the textures in an overnight job which is an ass but you get so much better compression ratio's than with S3TC, especially as the texture gets larger. You can also read and decompress a VQ compressed texture quicker than you can read an uncompressed texture which is stunning if u ask me.
You can get about twice the compression ratio of DXTC (for colour-only images), but the difference between 2bpp and 4bpp is not really of much interest in the video card market. Smaller than 4bpp is of interest mainly in areas where memory is at a huge premium (handheld devices etc). As far as video cards go if VQ's higher compression ratio couldn't win the day back when it was first introduced (when devices might typically have only about 8-16 MB of onboard RAM) then it is hardly likely to be a convincing argument now.
In the consumer 3D space the most interesting aspect of compression is increasing the efficiency of texturing, and DXTC solves that problem just fine - the added benefits of dropping to 2bpp vs. 4bpp in overall texturing efficiency are generally pretty marginal (considering you've already dropped from 24bpp->4bpp, and effectively from 32bpp->4 bpp, since most 3D hardware does not use packed texel formats).
Whether the image quality of VQ at 2bpp is equivalent to DXTC at 4bpp is a long and involved discussion in and of itself, but in most typical cases I believe it to be somewhat lower quality overall (although in the same ballpark). Of course each compression method has different strong and weak points in terms of IQ, and therefore the exact situation varies from image to image. I know that Simon had a comparison of some aspects of this on his homepage where he made some interesting observations on quality/bit.
VQ compression is also not great for hardware, as Simon has touched upon, since you need to hide an additional indirection. Also, for properly orthogonal support you have to be able to use N different sets of VQ palettes, where N is the number of simultaneous textures you support.
")