On this test on the XL it appears to make no different in 6x FSAA and a slightly detrimental performance in 2x.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Recent Radeon X1K Memory Controller Improvements in OpenGL with AA
- Thread starter Geo
- Start date
Dave Baumann said:On this test on the XL it appears to make no different in 6x FSAA and a slightly detrimental performance in 2x.
NO different means:
1. The same performance INCREASE.
or
2. No INCREASE at all (improvements at 4xAA only?)
Jawed
Legend
One feature that hasn't got much attention so far is the Color Buffer Cache (buffer and cache?).sireric said:The MC requires the clients to have lots of latency tolerance so that it can establish a huge number of outstanding requests and pick and chose the best ones to maximize memory bandwidth (massive simplification).
Presumably the render back-end has its own scheduler built-in, to take a list of incoming colour/z/stencil values and render them into the back-buffer. I'm guessing that this scheduler will gather the writes into "blocks" and then ask the MC to retrieve the corresponding areas of frame-buffer into CBC, so that the RBE only directly accesses the CBC - it never directly accesses VRAM.
Whilst the RBE is waiting for the MC to deliver the requested block into CBC, it should have received other blocks and be able to perform colour-writes/AA compares etc.
Similarly, presumably, the scheduler also has task types associated with z and stencil queries, again requiring "blocks" of back-buffer to be read into the CBC. Although the diagram for R520 implies that z/stencil (buffer cache) are outside of the RBE - but nevertheless are utilised by RBE.
Finally, of course, the scheduler must deal with purging CBC back into VRAM to make way for other blocks.
Is it right to assume that each of R520's "pixel units" integrates the texture and shader engines with the RBE, so that there are four separate RBE's in X1800XT? Each with a localised CBC?
It seems to me that if the GPU splits the back-buffer into "screen tiles", e.g. of 16x16 pixels, then each RBE has guaranteed ownership of "blocks" in the back-buffer - so avoiding any risk of contention by multiple RBEs over individual pixels in the back-buffer.
The only remaining problem is to ensure that colour-write operations that are dependent on write order are processed in write order - so the scheduler needs to be able to differentiate between un-ordered writes and in-order writes, when it schedules RBE tasks.
Jawed
Wow excellent thread! Its great to read so much of low level info about the gpus straight from the guys involved in making it.
A low level API would be really great to use instead of abusing the graphics api for non-graphics tasks. Right now the GPUs are evolving at a great pace so would it not be reasonable to not enforce backward compatibility of thelow level API. So the GPU architecture is free to evolve in whatever way it wants, each time supplying a changing API. If the guys doing non-graphics things want their code to run unmodified on the new architecture too then they should only stick to abusing the graphics API, possibly trading off some performance and features. If more APIs are to be provided at all, they should be implemented as libraries on top of the low level APIs.
But I am very happy just to learn that you are atleast thinking of doing something about it.
sireric said:I'm not saying replace the gfx APIs -- Just trying to limit to prolification of new ones. What if the physics API doesn't allow for all physical phenomena to be done? Do you create a new API for that? What if signal processing wants to be done and you only have collision hooks?
At the end, I fear the same thing regarding low level of detail. But I fear the extreme work in having lots of new specialized APIs too. I'd like a reasonably low level API that allows more "to the metal" performance, but that abstracts some of the quirks of programming a given architecture. I don't really know the answer either. It's a new place were we are continuing to explore, but we are listening and talking to that community.
A low level API would be really great to use instead of abusing the graphics api for non-graphics tasks. Right now the GPUs are evolving at a great pace so would it not be reasonable to not enforce backward compatibility of thelow level API. So the GPU architecture is free to evolve in whatever way it wants, each time supplying a changing API. If the guys doing non-graphics things want their code to run unmodified on the new architecture too then they should only stick to abusing the graphics API, possibly trading off some performance and features. If more APIs are to be provided at all, they should be implemented as libraries on top of the low level APIs.
But I am very happy just to learn that you are atleast thinking of doing something about it.
Well, the problem is that how do you maintain a low-level API along with vendor-agnostic interfaces?
Edit:
Actually, now that I think about it, it might be quite nice to have a low-level API as an intermediate step between a higher-level API or language and the hardware. This would allow the implementation of compilers and API's without having to go through the graphics pipeline and also without IHV's having to write drivers for the specific API's. It would then be up to the API/compiler vendors to support the various types of hardware.
Edit:
Actually, now that I think about it, it might be quite nice to have a low-level API as an intermediate step between a higher-level API or language and the hardware. This would allow the implementation of compilers and API's without having to go through the graphics pipeline and also without IHV's having to write drivers for the specific API's. It would then be up to the API/compiler vendors to support the various types of hardware.
Chalnoth said:Well, the problem is that how do you maintain a low-level API along with vendor-agnostic interfaces?
Edit:
Actually, now that I think about it, it might be quite nice to have a low-level API as an intermediate step between a higher-level API or language and the hardware. This would allow the implementation of compilers and API's without having to go through the graphics pipeline and also without IHV's having to write drivers for the specific API's.
That's actually exactly what I was thinking. What I *really* want, is public APIs at multiple levels, so that we have the option of coding closer to the metal or at a higher level abstraction. We want vendor agnostic high level APIs and vendor specific low level apis. Cross platform too.
")
Nite_Hawk
Hehe, yep I was thinking along the same lines (if I understood you right). The other APIs would be implemented ontop of the vendor specific low level API. Also for GPGPU, you could have libraries implemented on top of the low level API that are specific to a certain domain. But if you really want just the performance and features, just code to the low level API.
Nite_Hawk said:We want vendor agnostic high level APIs and vendor specific low level apis. Cross platform too.
Nite_Hawk
Exactly what I wanted to say
'Cache' inside graphics chips has three uses, not all of which may be familiar if you're only used to the term 'cache' in the way that CPU's use it.Nite_Hawk said:Why exactly is the color buffer cache needed?
1. Cache avoids going to memory when an item of data is frequently accessed in a short period of time. This is important in some places in graphics chips (vertex accesses, texture filtering, small triangles) but it's not always the main raison d'etre. It's what I thought cache was until I had the other two uses explained to me...
2. Caching to increase burst lengths - speculative reads and holding write data for more items to come into the same cache line and so improve memory efficiency. This is absolutely essential for graphics as most data items are much smaller than the amounts that it is efficient to get from memory in one go.
3. Caching for efficient pipelining; when you find out you are going to need a particular cache line further down the pipe you can issue the request to fill that cache line immediately, and then later in the pipeline the data is already present in the cache by the time it's needed to be used.
So while the colour buffer cache may not always need much of function 1, function 2 is absolutely essential and function 3 allows for more efficient design.
Dave Baumann said:On this test on the XL it appears to make no different in 6x FSAA and a slightly detrimental performance in 2x.
What I get out of that is separate settings are required for all three. What I get out of sireric's posts is that they will provide those separate settings by the time this hits a released driver.
Kombatant
Regular
To be honest I am not that fond of low level APIs; I would prefer a solution (a gcc-like compiler, like ATI said in one of its presentations) that was built on top of OpenGL (or Direct3D, but OGL is not bound to a certain platform), so that it could use not only ATI cards, but nV cards as well. Of course you have the problem that a) graphics APIs are not really designed to do general programming stuff, so you are bound to miss certain general-purpose functions that must be created somehow b) API built on top of API equals lost speed and efficiency.krychek said:Hehe, yep I was thinking along the same lines (if I understood you right). The other APIs would be implemented ontop of the vendor specific low level API. Also for GPGPU, you could have libraries implemented on top of the low level API that are specific to a certain domain. But if you really want just the performance and features, just code to the low level API.
Eric, do you have any idea whether nVidia has any plans to head where ATI is now headed with its GPGPU involvement? [wishful thinking]It would be nice if there were an nVidia employee around here to answer that question[/wishful thinking]
Jawed
Legend
I'm hypothesising that RBE is just another "latency-tolerant" client of the MC.Nite_Hawk said:I'm still trying to process everything in your post... Why exactly is the color buffer cache needed? Couldn't the RBE directly request blocks from the MC and remove the CBC layer?
In order to be latency-tolerant it, presumably, runs render tasks in a disjoint fashion. One way to do this is to implement a really long pipeline, so that by the time the data-sensitive portion of the RBE task occurs, the data is all in place (latency has run its course).
But in typical RBE tasks, I don't know what you'd fill the pipeline with. It's pixel colour data with an address in the back-buffer. There's not very much you can do with that data until you have access to the relevant portion of back-buffer.
So an alternative to this is to "batch-up" RBE tasks. Instead of working on a single quad of pixels (e.g. writing four pixels' colour values into the back-buffer), it makes sense to work in blocks. A block might be 8 pixels. Or 64 pixels. I don't know. Increasing the size makes each access to memory more efficient. But it also costs more in terms of on-die CBC space.
Then you also have to bear in mind that the shader/texture pipelines produce colour-writes out of order (or at least I presume they do, since the threads are themselves able to execute out of order).
So the RBE has to take care to write order-sensitive pixels in the correct order.
So the RBE would seem to have to be able to re-order incoming tasks, and block them up into memory-efficient packets.
I should point out that the "Xenos" AA EDRAM patent covers similar ground.
http://patft.uspto.gov/netacgi/nph-Parser?patentnumber=6873323
But the concepts I'm discussing aren't the main focus of that patent.
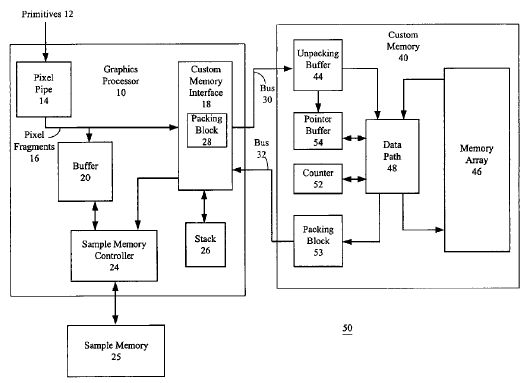
Instead, notice the use of Packing and Unpacking units. It's a tenuous link, but I think something similar is prolly happening in relation to CBC.
I'm suggesting that each CBC is owned by a single RBE. And each RBE solely owns screen-tiles. The net effect being that a given pixel is always the property of a single RBE. This increases parallelism in the GPU, without creating intra-GPU dependencies.I think the missing peice of information for me is how often the same data gets requested from the CBC over again. If we have 4 RBEs, do each of them only contact one CBC? If so I could see why this is important...
There is no need to enforce cache-coherency in the CBCs, if the RBEs are screen-tile bound.
In general, rendering into the back-buffer is an incoherent process. Even within a screen-tile of 16x16 pixels I expect you'll find that each pixel is only written once or twice in each "visit" that a screen-tile makes into CBC.
In the natural progress of rendering triangles ("walking them" one quad at a time), the pixel colour data for triangles will tend to arrive in the RBE in bursts. So there is a level of coherency within a screen-tile (or a CBC block, if it's smaller than a screen-tile).
Jawed
Meh. I think the point that was _trying_ to be made (before it got lost in all the posturing and nit-picking) was that ATI's design philosophy tends to go for a more flexible and general-purpose design (programmable AA, programmable MC, push for unified shaders), wheras nVidia tend to go for hardwiring in specific features. At an abstract level each approach has its own pros and cons; flexible designs tend to cope with future developments well and allow tuning to deal with future software, but at the expense of transistor count and thus speed in specific design-target functions, wheras hardwired designs tend to give good speed in design-target functions for a smaller transistor count at the expense of the possibility of hardware-utilisation efficiency boosts in the future and the ability to deal well with usage patterns outside design parameters.
That's not to say that either company is the perfect embodiment of either philosophy or that design quality in various areas are the same on either side or anything like that; it's just to say that generally ATI go in one direction and nVidia go in the other. ATI wants unified shaders, nVidia wants to keep them seperate, ATI has programmable this and that, nVidia gives boost in Z/stencil ops or whatever (terminology goes over my head - talking D3 shadows etc) for specific gains in specific circumstances. Both companies show general trends towards design philosophies in different directions. Some prefer the focus on hardwired speed, some prefer the focus on flexibility.
Also, anyone who thinks philosophy has nothing to do with reality has no idea what they're talking about and shouldn't be commenting on the subject.
That's not to say that either company is the perfect embodiment of either philosophy or that design quality in various areas are the same on either side or anything like that; it's just to say that generally ATI go in one direction and nVidia go in the other. ATI wants unified shaders, nVidia wants to keep them seperate, ATI has programmable this and that, nVidia gives boost in Z/stencil ops or whatever (terminology goes over my head - talking D3 shadows etc) for specific gains in specific circumstances. Both companies show general trends towards design philosophies in different directions. Some prefer the focus on hardwired speed, some prefer the focus on flexibility.
Also, anyone who thinks philosophy has nothing to do with reality has no idea what they're talking about and shouldn't be commenting on the subject.
Dio said:'Cache' inside graphics chips has three uses, not all of which may be familiar if you're only used to the term 'cache' in the way that CPU's use it.
1. Cache avoids going to memory when an item of data is frequently accessed in a short period of time. This is important in some places in graphics chips (vertex accesses, texture filtering, small triangles) but it's not always the main raison d'etre. It's what I thought cache was until I had the other two uses explained to me...
Ah ha. Is this the answer to my question upstream re the hardware elements of the low-hit (relatively) of the performance cost of rotation independent AF vs optimized AF? The large texture cache increase in R5xx?
Dio said:'Cache' inside graphics chips has three uses, not all of which may be familiar if you're only used to the term 'cache' in the way that CPU's use it.
1. Cache avoids going to memory when an item of data is frequently accessed in a short period of time. This is important in some places in graphics chips (vertex accesses, texture filtering, small triangles) but it's not always the main raison d'etre. It's what I thought cache was until I had the other two uses explained to me...
2. Caching to increase burst lengths - speculative reads and holding write data for more items to come into the same cache line and so improve memory efficiency. This is absolutely essential for graphics as most data items are much smaller than the amounts that it is efficient to get from memory in one go.
3. Caching for efficient pipelining; when you find out you are going to need a particular cache line further down the pipe you can issue the request to fill that cache line immediately, and then later in the pipeline the data is already present in the cache by the time it's needed to be used.
So while the colour buffer cache may not always need much of function 1, function 2 is absolutely essential and function 3 allows for more efficient design.
Hi Dio,
Thank you much for the explanation! From Sireric's posts, it really sounds like #2 and #3 are the areas in which they are focusing improvements in the memory controller. Specifically when Sireric mentions data-reordering it makes me think that they are perhaps reordering speculative data (or data that is not immediately needed) to better fill data packets when doing memory reads (sorry, I think of all of this in terms of networking protocols).
Jawed said:I'm hypothesising that RBE is just another "latency-tolerant" client of the MC.
In order to be latency-tolerant it, presumably, runs render tasks in a disjoint fashion. One way to do this is to implement a really long pipeline, so that by the time the data-sensitive portion of the RBE task occurs, the data is all in place (latency has run its course).
But in typical RBE tasks, I don't know what you'd fill the pipeline with. It's pixel colour data with an address in the back-buffer. There's not very much you can do with that data until you have access to the relevant portion of back-buffer.
So an alternative to this is to "batch-up" RBE tasks. Instead of working on a single quad of pixels (e.g. writing four pixels' colour values into the back-buffer), it makes sense to work in blocks. A block might be 8 pixels. Or 64 pixels. I don't know. Increasing the size makes each access to memory more efficient. But it also costs more in terms of on-die CBC space.
Then you also have to bear in mind that the shader/texture pipelines produce colour-writes out of order (or at least I presume they do, since the threads are themselves able to execute out of order).
So the RBE has to take care to write order-sensitive pixels in the correct order.
So the RBE would seem to have to be able to re-order incoming tasks, and block them up into memory-efficient packets.
I should point out that the "Xenos" AA EDRAM patent covers similar ground.
http://patft.uspto.gov/netacgi/nph-P...number=6873323
But the concepts I'm discussing aren't the main focus of that patent.
Instead, notice the use of Packing and Unpacking units. It's a tenuous link, but I think something similar is prolly happening in relation to CBC.
Ah, thank you for the explanation! That makes a lot of sense. I would expect that you are probably correct in your hypothesis about the packing/unpacking units in relation to the CBC. It seems like it would be basically necessary if you have larger batch sizes. I imagine that the savings you get would far outweigh the die space needed for implementation, though I suppose it depends on what kind of latency you are willing to accept.
Nite_Hawk
Jawed
Legend
Since ATI's older GPUs couldn't execute pixel shader threads out of order, packing colour writes in the RBE would have been easier, I guess.
The packing would match up well with the triangle walk, I expect. Though prolly not perfectly (since triangles aren't memory-tile sized).
I doubt the CBC is entirely new in R520 - but I expect the scope of RBE operation has evolved so much in R520 that CBC has had to grow significantly, both in terms of size and functionality. I dare say in much the same way that texture caches have evolved.
Jawed
The packing would match up well with the triangle walk, I expect. Though prolly not perfectly (since triangles aren't memory-tile sized).
I doubt the CBC is entirely new in R520 - but I expect the scope of RBE operation has evolved so much in R520 that CBC has had to grow significantly, both in terms of size and functionality. I dare say in much the same way that texture caches have evolved.
Jawed
Kombatant said:To be honest I am not that fond of low level APIs; I would prefer a solution (a gcc-like compiler, like ATI said in one of its presentations) that was built on top of OpenGL (or Direct3D, but OGL is not bound to a certain platform), so that it could use not only ATI cards, but nV cards as well. Of course you have the problem that a) graphics APIs are not really designed to do general programming stuff, so you are bound to miss certain general-purpose functions that must be created somehow b) API built on top of API equals lost speed and efficiency.
There has been some work already on having a gpgpu friendly libs built on top of the graphics APIs. (Brook, Sh ) But this only makes the gpgpu programmer's job easy - they don't expose any special features of a particular chip (as you mentioned). Once the functionalities of a GPU become almost fixed then we could definitely do with a high level non-graphics API. But until then, I don't see how a common API can be designed that can offer all the capabilities of NV and ATI. Now ATI's gpu has support for scatter for this generation but NV's does not, how will this be handled? An extension? This will just slow down the API/ dumb down the API. OGL doesn't change fast enough because it has to be backward compatible and hence only really consistent extensions make it into the core.
The reason for the low level APIs is to immediately provide the low level access for an architecture and not care about backward compatibility. This takes the burden off the IHVs too and its upto the community/academia to come up with any API on top of this that is hardware architecture independent. In this scenario, there is no room for IHVs to disagree with each other or worry about any backward compatibility (other than the graphics APIs) and they can just focus on the hardware.
If it happens that all IHVs agree on the architecture then obviously we would ask for a high level vendor agnostic API
.This whole thread makes me go ^3
Not even in wilder dreams I would have expected people from the GPU world being so open about their hardware implementations. At least not a couple of years ago when I started with the simulator. In fact, part of the reason I started it was because there was little information and I like to gather and speculate about topics with little or not very available information. That's why my master thesis was just a large boring document where I tried to explain how to write a computer system emulator (aka console or arcade emulator) as most normal information sources for the topic were very fragmented or lacking key methods. At end it was must about CPU emulation than anything else because lack of time and I still wonder if someone will ever compile something about how all those sprite and tile based graphic systems are emulated (M.A.M.E. IS NOT DOCUMENTATION!). And the other part was ... that I like to emulate hardware in software ...
Being a bit more on topic. If ATI is really commited to become the DEC of the GPU industry (they were releasing almost every bit about their implementations), which I doubt (it's more likely they go the Intel/AMD way), there is going to be an even larger BOOM! in GPU/GPGPU related research. Which I don't like much as I was precissely trying to run from the massification of yet another branch predictor or, at the time I started my PhD, another SMT technique, that computer architecture research was looking like (at least where I am) ... so please don't release information
On another matter, Jawed seems to be trying to explain that if you assign work on a framebuffer tile basis to completely separated quad pixel pipelines you have some interesting benefits. The first one being no need for cache coherence between each of the pipelines as each pipeline never ever touches a single bit from a framebuffer region from another pipeline. Then you could assign the ROP in a pipeline to a MC, if you had enough of them, providing something like semi dedicated bw per pipeline, which may be or not a good idea. Each pipeline ROP would be accessing their own separated portion of memory, and mostly (at least related only to the ROPs) having their own separated share of bw, reducing conflicts and similar stuff. One possible problem would be work unbalancing if the queues around the pipeline aren't large enough or if someone with a very bad bad intention only renders to the regions assigned to a single pipeline (but what is the point of chess-like rendering?).
The current implementation of the simulator implements that kind of work partition at the ROP level (but not necessarily at the shader and upper levels) but with our very simple MC and memory simulation we don't even bother to garantee that each ROP pipe goes to a single MC. With tile size set at 8x8 (ATI is 16x16 it seems) basically because I like so and our cache lines are, for a number of bad reasons, of that absurd size.
^3Not even in wilder dreams I would have expected people from the GPU world being so open about their hardware implementations. At least not a couple of years ago when I started with the simulator. In fact, part of the reason I started it was because there was little information and I like to gather and speculate about topics with little or not very available information. That's why my master thesis was just a large boring document where I tried to explain how to write a computer system emulator (aka console or arcade emulator) as most normal information sources for the topic were very fragmented or lacking key methods. At end it was must about CPU emulation than anything else because lack of time and I still wonder if someone will ever compile something about how all those sprite and tile based graphic systems are emulated (M.A.M.E. IS NOT DOCUMENTATION!). And the other part was ... that I like to emulate hardware in software ...
Being a bit more on topic. If ATI is really commited to become the DEC of the GPU industry (they were releasing almost every bit about their implementations), which I doubt (it's more likely they go the Intel/AMD way), there is going to be an even larger BOOM! in GPU/GPGPU related research. Which I don't like much as I was precissely trying to run from the massification of yet another branch predictor or, at the time I started my PhD, another SMT technique, that computer architecture research was looking like (at least where I am) ... so please don't release information
On another matter, Jawed seems to be trying to explain that if you assign work on a framebuffer tile basis to completely separated quad pixel pipelines you have some interesting benefits. The first one being no need for cache coherence between each of the pipelines as each pipeline never ever touches a single bit from a framebuffer region from another pipeline. Then you could assign the ROP in a pipeline to a MC, if you had enough of them, providing something like semi dedicated bw per pipeline, which may be or not a good idea. Each pipeline ROP would be accessing their own separated portion of memory, and mostly (at least related only to the ROPs) having their own separated share of bw, reducing conflicts and similar stuff. One possible problem would be work unbalancing if the queues around the pipeline aren't large enough or if someone with a very bad bad intention only renders to the regions assigned to a single pipeline
(but what is the point of chess-like rendering?).The current implementation of the simulator implements that kind of work partition at the ROP level (but not necessarily at the shader and upper levels) but with our very simple MC and memory simulation we don't even bother to garantee that each ROP pipe goes to a single MC. With tile size set at 8x8 (ATI is 16x16 it seems) basically because I like so and our cache lines are, for a number of bad reasons, of that absurd size.
Jawed said:Since ATI's older GPUs couldn't execute pixel shader threads out of order, packing colour writes in the RBE would have been easier, I guess.
The packing would match up well with the triangle walk, I expect. Though prolly not perfectly (since triangles aren't memory-tile sized).
I doubt the CBC is entirely new in R520 - but I expect the scope of RBE operation has evolved so much in R520 that CBC has had to grow significantly, both in terms of size and functionality. I dare say in much the same way that texture caches have evolved.
Jawed
In my opinion (and I don't really know much about rasterization and I had more than enough pain implementing it on the simulator) only Triangle Setup, if anything, may be shared for all the quad pipes in ATI designs. As they have explained a number of times they bin triangles to each pipe based on their tile distribution algorithm and then they seem to implement a fragment generator (I wonder if it would be better named as tile generator, what do they send to HZ test? fragments or a single tile that later may be further divided into quads?) per pipeline. So they have N rasterizers 'walking' each their own assigned triangles.
Similar threads
- Locked
- Replies
- 2
- Views
- 2K
- Replies
- 157
- Views
- 31K
- Replies
- 126
- Views
- 47K