You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Recent Radeon X1K Memory Controller Improvements in OpenGL with AA
- Thread starter Geo
- Start date
Rys said:Quick Doom3 numbers from the XT only. Yay for coffee breaks.
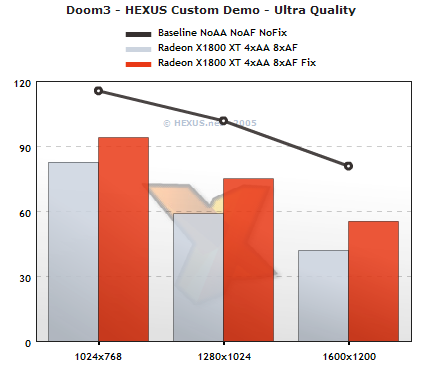
Impressive improvements... a 20-30% reduction in speed due to 4x AA and 8x AF is very nice indeed...
Nite_Hawk
Hellbinder
Banned
What about 4x AA and 16X AF?
And is that with HQ filtering? or performance filtering?
Is it reproducable in other OGL games? or Doom-III engine games?
And is that with HQ filtering? or performance filtering?
Is it reproducable in other OGL games? or Doom-III engine games?
Rys is promising Chronicles of Riddick testage to come on the Hexus page: http://www.hexus.net/content/item.php?item=3668
Hellbinder said:What about 4x AA and 16X AF?
And is that with HQ filtering? or performance filtering?
Is it reproducable in other OGL games? or Doom-III engine games?
Default Quality filtering, 16xAF. 6xAA and 2xAA show the same thing in D3 and yes, it's the same kind of stuff in Riddick too.
No IQ differences that I can see (difference output from same spot screenies). Not got the time to do much else today other than post Riddick numbers and some GTX comparo numbers later on. Maybe someone else will pick up the tool and run with it more than I can.
Snowed under with motherboards right now, joy of joys.
ATI laying the smack down across the board in OGL would be one of those "Get the umbrellas out, boys, the frogs will be coming from the sky any moment" kind of transitions.
Edit: Given their well-known "D3D first" strategy, I wonder if we'd be justified in thinking that on the D3D side this is already there, in at least as robust a way as this add for OGL? (still leaving room for the "room to improve", of course).
Edit: Given their well-known "D3D first" strategy, I wonder if we'd be justified in thinking that on the D3D side this is already there, in at least as robust a way as this add for OGL? (still leaving room for the "room to improve", of course).
thatdude90210
Regular
Try it on an X1800XL... just wondering if the performance increase come from optimizing the use of 512mb in the XT.
thatdude90210 said:Try it on an X1800XL... just wondering if the performance increase come from optimizing the use of 512mb in the XT.
Love to see it tested on XL, RV530, and RV515. On XL tho, the available bandwidth is a pretty big difference too, so I don't know you can come to definite conclusions about whether they might be doing some fun storage tricks with that extra 256mb on XT that somehow helps performance on AA beyond the shipping drivers (I'm not even sure what that would look like actually --what, they couldn't address the other 256mb in OGL?
") ) that XT was originally reviewed with. Tho obviously if XL shows the same increases it would indicate they aren't.
) that XT was originally reviewed with. Tho obviously if XL shows the same increases it would indicate they aren't.I'm feeling more comfortable with the ATI email upstream, which was a pretty flat statement on the matter, but I'm sure we'll be dissecting this for awhile.
This change is for the X1K family. The X1Ks have a new programmable memory controller and gfx subsystem mapping. A simple set of new memory controller programs gave a huge boost to memory BW limited cases, such as AA (need to test AF). We measured 36% performance improvements on D3 @ 4xAA/high res. This has nothing to do with the rendering (which is identical to before). X800's also have partially programmable MC's, so we might be able to do better there too (basically, discovering such a large jump, we want to revisit our previous decisions).
But It's still not optimal. The work space we have to optimize memory settings and gfx mappings is immense. It will take us some time to really get the performance closer to maximum. But that's why we designed a new programmable MC. We are only at the beginning of the tuning for the X1K's.
As well, we are determined to focus a lot more energy into OGL tuning in the coming year; shame on us for not doing it earlier.
But It's still not optimal. The work space we have to optimize memory settings and gfx mappings is immense. It will take us some time to really get the performance closer to maximum. But that's why we designed a new programmable MC. We are only at the beginning of the tuning for the X1K's.
As well, we are determined to focus a lot more energy into OGL tuning in the coming year; shame on us for not doing it earlier.
sireric said:As well, we are determined to focus a lot more energy into OGL tuning in the coming year; shame on us for not doing it earlier.
Well, hell of a nice way to announce the change in policy, at least! There are few more sincerely appreciated apologies than "here, have another 35%".
sireric said:This change is for the X1K family. The X1Ks have a new programmable memory controller and gfx subsystem mapping. A simple set of new memory controller programs gave a huge boost to memory BW limited cases, such as AA (need to test AF). We measured 36% performance improvements on D3 @ 4xAA/high res. This has nothing to do with the rendering (which is identical to before). X800's also have partially programmable MC's, so we might be able to do better there too (basically, discovering such a large jump, we want to revisit our previous decisions).
But It's still not optimal. The work space we have to optimize memory settings and gfx mappings is immense. It will take us some time to really get the performance closer to maximum. But that's why we designed a new programmable MC. We are only at the beginning of the tuning for the X1K's.
As well, we are determined to focus a lot more energy into OGL tuning in the coming year; shame on us for not doing it earlier.
That's great, but you should stop making me jealous, I got my 7800gtx for a good cause!
In whatever capacity you can answer, how do your mappings differ compared to what you did previously? ~36% improvements are dramatic, and if you are expecting more improvements that is remarkable. I'm not a memory guy really, but are these mostly dealing with latency or throughput improvements? Better data packing? re-ordering? compression? Caching? Inquiring minds want to know!
Oh, any chance for improvments in D3d as well?
Nite_Hawk
Jawed said:Does the boost in D3 relate to trade-offs in texturing memory accesses versus ROP/4xAA memory accesses? Or is the boost solely in terms of the effectiveness of ROP/4xAA accesses?
What about 6xAA?
Jawed
It's a mixture of Z and Blend. Not sure which one gained more. I haven't seen 6xAA tested (or can't remember), but it's probably better too. I'm hoping that within a few weeks, we can tune most of this to get much better in all AA & AF modes. Can't promise any performance deltas, but I think it's fair to say that there's more in there. Given the immense space of possibilities, tuning of the X1k products will take some time. We are just at the beginning...
Nite_Hawk said:That's great, but you should stop making me jealous, I got my 7800gtx for a good cause!
In whatever capacity you can answer, how do your mappings differ compared to what you did previously? ~36% improvements are dramatic, and if you are expecting more improvements that is remarkable. I'm not a memory guy really, but are these mostly dealing with latency or throughput improvements? Better data packing? re-ordering? compression? Caching? Inquiring minds want to know!
Oh, any chance for improvments in D3d as well?
Nite_Hawk
D3D already got some tuning for launch, but there's a lot to do there as well.
This specific change has to do more with throughput and data ordering. Though it's empirical in nature, so we need to go back and tune things with a better understanding.
sireric said:D3D already got some tuning for launch, but there's a lot to do there as well.
This specific change has to do more with throughput and data ordering. Though it's empirical in nature, so we need to go back and tune things with a better understanding.
So still in the "warmer" "colder" stage looking for the pattern. Yeah, that does suggest good things for the future unless you were inordinately lucky.
sireric said:D3D already got some tuning for launch, but there's a lot to do there as well.
This specific change has to do more with throughput and data ordering. Though it's empirical in nature, so we need to go back and tune things with a better understanding.
Wow, that's great... I'm still yearning to understand more about what data exactly you are re-ordering and how you are doing it to get that kind of an improvement, but I imagine that you probably can't publically say too much about it. (boo!)
Do you know if these changes will be roled into your linux drivers as well?
Nite_Hawk
geo said:So still in the "warmer" "colder" stage looking for the pattern. Yeah, that does suggest good things for the future unless you were inordinately lucky.
No luck at all. More like being dumb for not doing this earlier. It was very simple. It just required people to start looking into what is going on.
Nite_Hawk said:Wow, that's great... I'm still yearning to understand more about what data exactly you are re-ordering and how you are doing it to get that kind of an improvement, but I imagine that you probably can't publically say too much about it. (boo!)
Do you know if these changes will be roled into your linux drivers as well?
Nite_Hawk
There's some slides given to the press that explain some of what we do. Our new MC has a view of all the requests for all the clients over time. The "longer" the time view, the greater the latency the clients see but the higher the BW is (due to more efficient requests re-ordering). The MC also looks at the DRAM activity and settings, and since it can "look" into the future for all clients, it can be told different algorithms and parameters to help it decide how to best make use of the available BW. As well, the MC gets direct feedback from all clients as to their "urgency" level (which refers to different things for different client, but, simplifying, tells the MC how well they are doing and how much they need their data back), and adjusts things dynamically (following programmed algorithms) to deal with this. Get feedback from the DRAM interface to see how well it's doing too.
We are able to download new parameters and new programs to tell the MC how to service the requests, which clients's urgency is more important, basically how to arbitrate between over 50 clients to the dram requests. The amount of programming available is very high, and it will take us some time to tune things. In fact, we can see that per application (or groups of applications), we might want different algorithms and parameters. We can change these all in the driver updates. The idea is that we, generally, want to maximize BW from the DRAM and maximize shader usage. If we find an app that does not do that, we can change things.
You can imagine that AA, for example, changes significantly the pattern of access and the type of requests that the different clients make (for example, Z requests jump up drastically, so do rops). We need to re-tune for different configs. In this case, the OGL was just not tuning AA performance well at all. We did a simple fix (it's just a registry change) to improve this significantly. In future drivers, we will do a much more proper job.
Similar threads
- Locked
- Replies
- 2
- Views
- 2K
- Replies
- 157
- Views
- 31K
- Replies
- 126
- Views
- 47K