And terrible results.
")
Amazing results actually -like you said- considering the early effort, and the non specialty of the AI model used, it's an old not so stable model called Runway Gen 3, most probably running on commercial level hardware. It's not Sora running on a supercluster of H100s or anything. It's also more successful with slow motion with less artifacts.
The original sentiment in this recent discussion was what would it take to achieve photorealism. Glitches and issues that are tolerable in computer games miss that target. So you could have a future where games are approaching photorealism in 5 years, say, but aren't confused with TV because of all the artifacts and issues.
Even after achieving photo-realsim, games will still be easily distinguishable from TV scenes, because photo-realism is not the same as physics-relaism, the way things move and interact (animation, particles, destruction, weight, ..etc) is an entirely different problem than the way things look. Sweeny's comment only refers to the way things look (photo-realism), however physics-relaism is an order of magnitude more difficult to solve.
So this whole (non distinguishable from TV) point doesn't really matter, we won't achieve it anyway until we solve physics-relaism, which needs even more hardware power and new algorithms.
You say they have things like hair physics and cloth physics, but these don't move right
They are more convincing though, especially vs the current gaming tech where they don't move at all or move in all the wrong ways.
How much effort will it be to create a ground truth for one game, let alone a model that can handle any and every game?
Why would the model handle every game? it's enough in the beginning to handle the situation in a game by game basis, until it accumulates enough data. We don't need every game to be AI enhanced, a select few titles with advanced visuals are enough in the beginning, just like Path Tracing now.
1) Your examples aren't realtime. Creating blobby pseudovideo with odd issues takes a lot of time and processing power. You need a massive improvement just to get these results in realtime.
I honestly think these videos don't take that many hours to render, the channels on YouTube are making dozens every week, they are most probably running on consumer level hardware as well, so using a specialized hardware will make things faster for sure.
I already gave an estimate on how things will progress regarding that point, maybe in 4 to 6 years GPUs will have more TOPs than FLOPS, and thus will be powerful enough to do 720p30, and upscale it using more advanced machine learning algorithms to the desired resolution and frame rate.
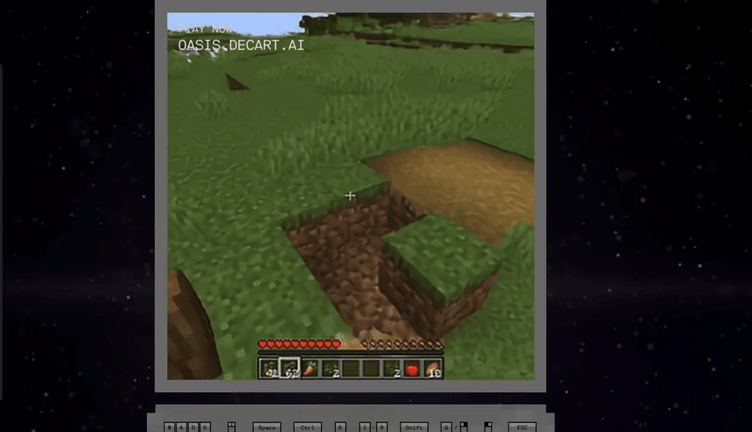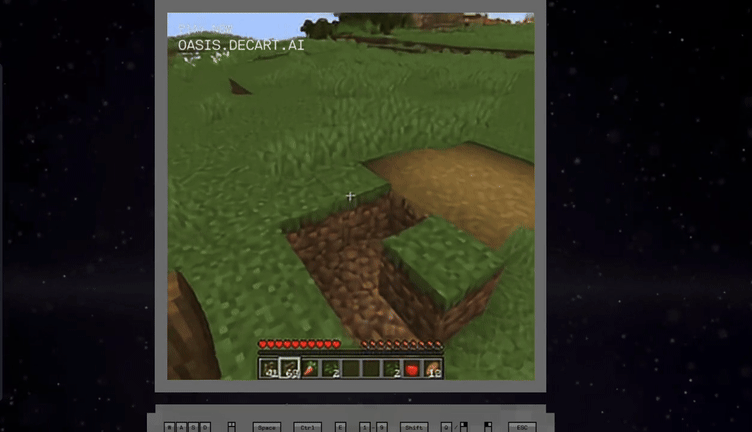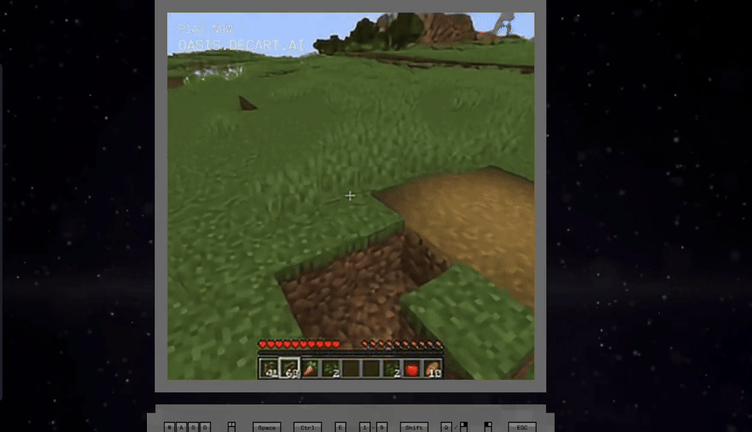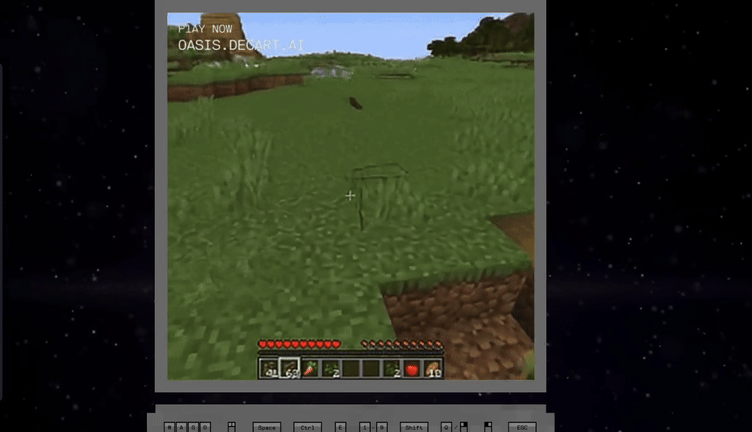
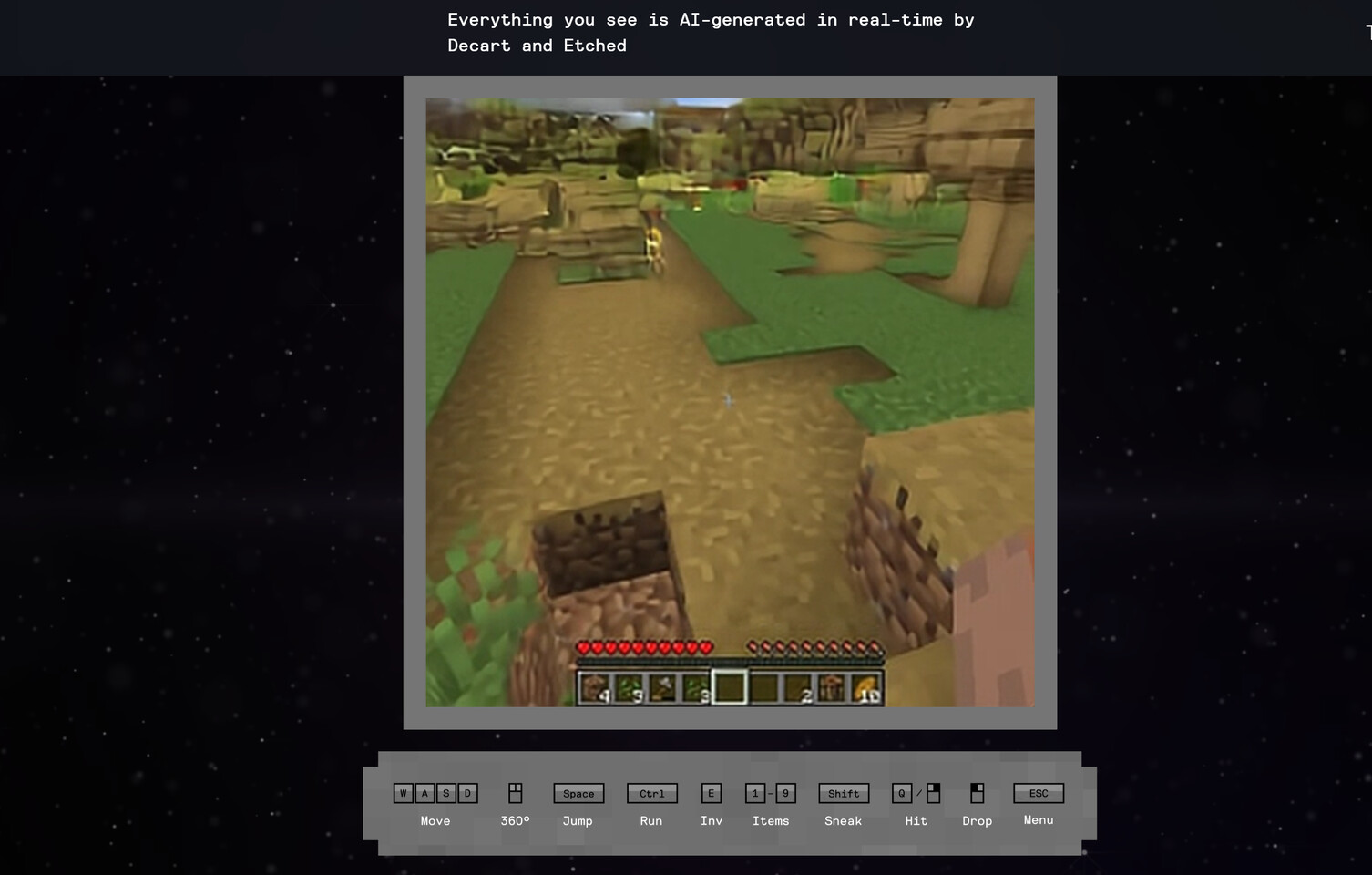
Oasis is the first playable, real-time, open-world AI model that takes users' input and generates real-time gameplay, including physics, game rules, and graphics.
See here, an AI model running on a single H100 rendered a Minecraft clone entirely using AI with a 720p20 fidelity in
realtime.
Play and create in real-time

www.tomsguide.com
Google also ran Doom with 20fps on a single TPU in realtime.
Dobos: “Why write rules for software by hand when AI can just think every pixel for you?”…

arstechnica.com
So things are advancing faster than we anticipate, in a single year models are often updated several times with new capabilities and faster processing, AI hardware is also released every 2 years now with often 2x to 3x more hardware power, unlike the traditional rendering where hardware speed and software advancements seems to have slowed down significantly. AI is advancing much much faster than traditional software.
This wonderful photorealistic future is by no means a certainty.
We won't get there immediately of course, we will have to go through baby steps first, explained below.
I think there are some areas ML would be very effective. My instinct is you could ML lighting on top of conventional geometry. You might also be able to ML enhance a game so lower rendering quality can be enhanced to Ultra quality, and you could train an ML on a better-than-realtime model to enhance the base model
I agree, but my premise is that we will start to with simpler things first like a post process technique to enhance hair, fur, fires, water, particles, clothes and other small screen elements .. etc, coupled with motion vectors and other game engines data, the results should be great and move in a convincing manner.
Enhancing textures is also a strong possibility, we already have a prototype of replacing textures in a game editor (RTX Remix) in real time, could be possible with further developments. Enhancing lighting is also another strong candidate in the beginning, just not the very beginning, maybe down the road a little.
And just like that, AI will be enhancing rendering one thing a time, bit by bit and piece by piece, until it's all enhanced in the end.
 forum.beyond3d.com
forum.beyond3d.com