
in some gaming scenarios
I think what most ment was this comment.
but if you're actually interested in truth, then the RTX 3008 is not a 30 TFLOP GPU
The 3080 for example is a 30TF GPU. If one is intrested in the truth, one could dig a little deeper then just saying 'its not the truth, its a lie, we are being misled etc'.
The post i linked to in my previous comment seems to sum things up quite well. No TF dont mean everything, theres more to it obviously, but that doesnt say they dont mean anything either.
https://www.gamespot.com/forums/sys...zealous-33515692/?page=1#js-message-356853198
From user 04dcarraher
''... FLOPS mean nothing when your comparing totally unrelated different gpu architectures..... Now if you were to compare say GCN 1.0 vs GCN 1.4 based gpu's then I would say "maybe" since they are still based on the same core design.
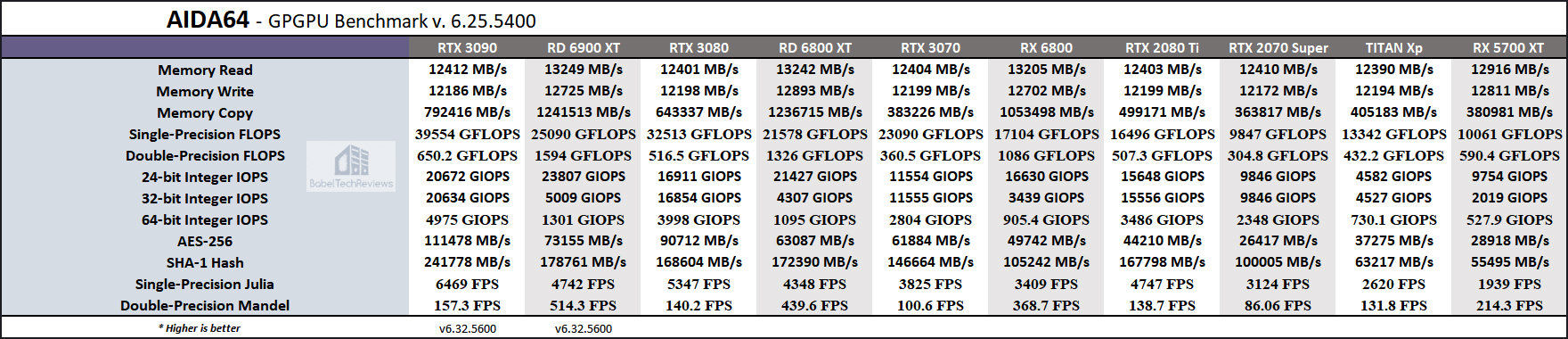
RX 6800xt (20 TFLOPS) has a pixel rate is 288 GPixel/s, texture rate of 648.0 GTexel/s
The RTX 2080ti(13.45 TFLOPS) has a pixel rate of 136.0 GPixel/s and a texture rate of 420.2 GTexel/s. Yet it still beats the 6800xt in RT but loses to the 6800xt in normal rasterization rendering performance.
While the RTX 3080( 29.77 TFLOPS) has a pixel rate of 164.2 GPixel/s and a texture rate of 465.1 GTexel/s. and beats the 6800xt overall and has much much better RT performance. The TFLOP increase is because of the 128 core per SM design vs Turing's 64 core design. Hence the 2x potential of math crunching. However half of the 64 cores of the 128 is allocated for INT and or more types of FP ie 8/16/32 etc base on the type of job. Making the gpu more flexible.
RX 6800 series is a great performing gpu when it comes to normal rasterization rendering. But falls flat on its face when it has to do it all, with RT and or high resolutions. The way the RDNAv2 does alot of its RT work is by using its free TMU(texture mapping units) "what gives the gpu its texture rate". So the higher the texture/pixel resolution and the amount of RT is used eats into the RDNA's TMU resources hurting performance.
While the design might be more flexible where you "could" allocate more TMU's for RT,adjusting the amount while Nvidia RTX design is a fixed amount of dedicated RT processors. But the fact that AMD is using a gpu's TMU's was a short cut for them to check mark "the does it have RT" box.''


")