You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Nvidia's 3000 Series RTX GPU [3090s with different memory capacity]
- Thread starter Shortbread
- Start date
-
- Tags
- nvidia
DegustatoR
Legend
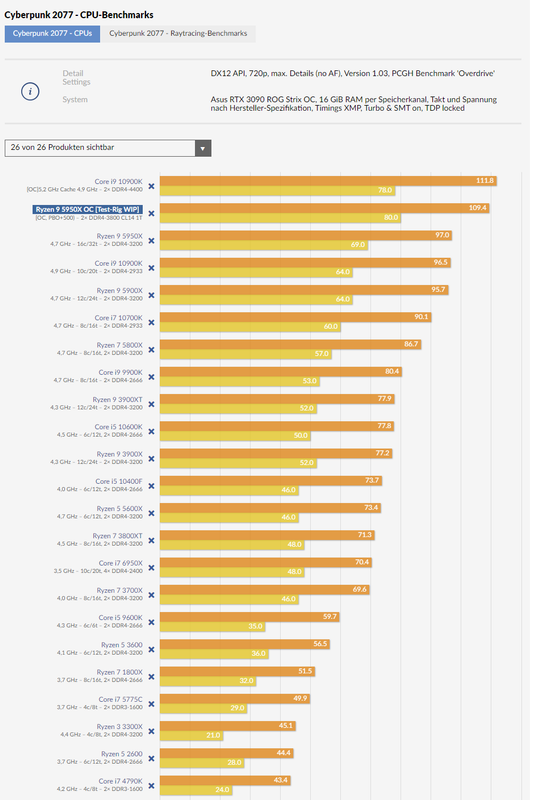
Note that the benchmark is done in 720p and while it shows the CPU scaling it's highly unlikely to be close to what you'll get out of these CPUs in 1080p and above - higher resolutions will be GPU limited mostly.ooofff my 3900x =(
Indeed! I just was blown away how fast CPUs moved since my purchase.Note that the benchmark is done in 720p and while it shows the CPU scaling it's highly unlikely to be close to what you'll get out of these CPUs in 1080p and above - higher resolutions will be GPU limited mostly.
arandomguy
Veteran
Some of those numbers don’t look right though. Why is a 10700k so much faster than a 9900k. They’re basically the same chip.
They aren't all using the same memory speed (and I guess latency, but timings are specified).
It looks like they are testing each CPU with "stock" memory speeds (maybe even "stock" JEDEC timings? Not specified.). Except at the top with the 2 OC results.
On a related note the slight scaling for the >8c/16t CPUs may not necessarily be due to core count but larger caches. Might need testing using "emulated" lower core counts which would maintain cache.
Since you are using the GPU codenames, it would be their 3rd GPU design at Samsung, accounting for the Pascal chips GP107 (GTX1050/Ti) and GP108 (GTX1030/MX150). It would be their 4th fab partner over the years.
Of course, your general point still stands. IIRC, the little Pascal chips were made at Samsung, right as Nvidia and Samsung settled their lawsuits. I always wondered if that was part of the lawsuit settlement or if Nvidia and Samsung's legal teams evaluated each other's IP and saw some opportunities to work with each other.
Also IIRC, AMD has used Samsung (directly) for Polaris, towards the end of the first major mining boom (the one where I purchased a GTX 1050Ti for ~$120, since it was an unique product that came from a non-traditional Nvidia partner, and I questioned if it was good value. One year later, it was almost twice that on the market, if one could even get one). So Samsung isn't totally unawares of how GPU designers work, either.
I always forgot the x08 GPU for some reason.
Also Nvidia might have another chip that was done at Samsung as well. It was never confirmed but Orin is speculated to use Samsung's 8nm automotive node.
Last edited:
CPU usage peaking at about 50% on 16 core 5950X
https://www.techspot.com/article/2164-cyberpunk-benchmarks/
“We're also keen to look at CPU performance as the game appears to be very demanding on that regard. For example, we saw up to 40% utilization with the 16-core Ryzen 9 5950X, and out of interest we quickly tried the 6-core Ryzen 5 3600 as that’s a very popular processor. We're happy to report gameplay was still smooth, though utilization was high with physical core utilization up around 80%.”
Coverage of RT and DLSS was reserved for a follow up article. At least HWUB is consistent
Last edited:
Moved Nvidia Review Sample Practices to thread BillSpencer created @ https://forum.beyond3d.com/threads/...les-to-reviewers-that-follow-procedure.62170/
Man from Atlantis
Veteran
Jawed
Legend
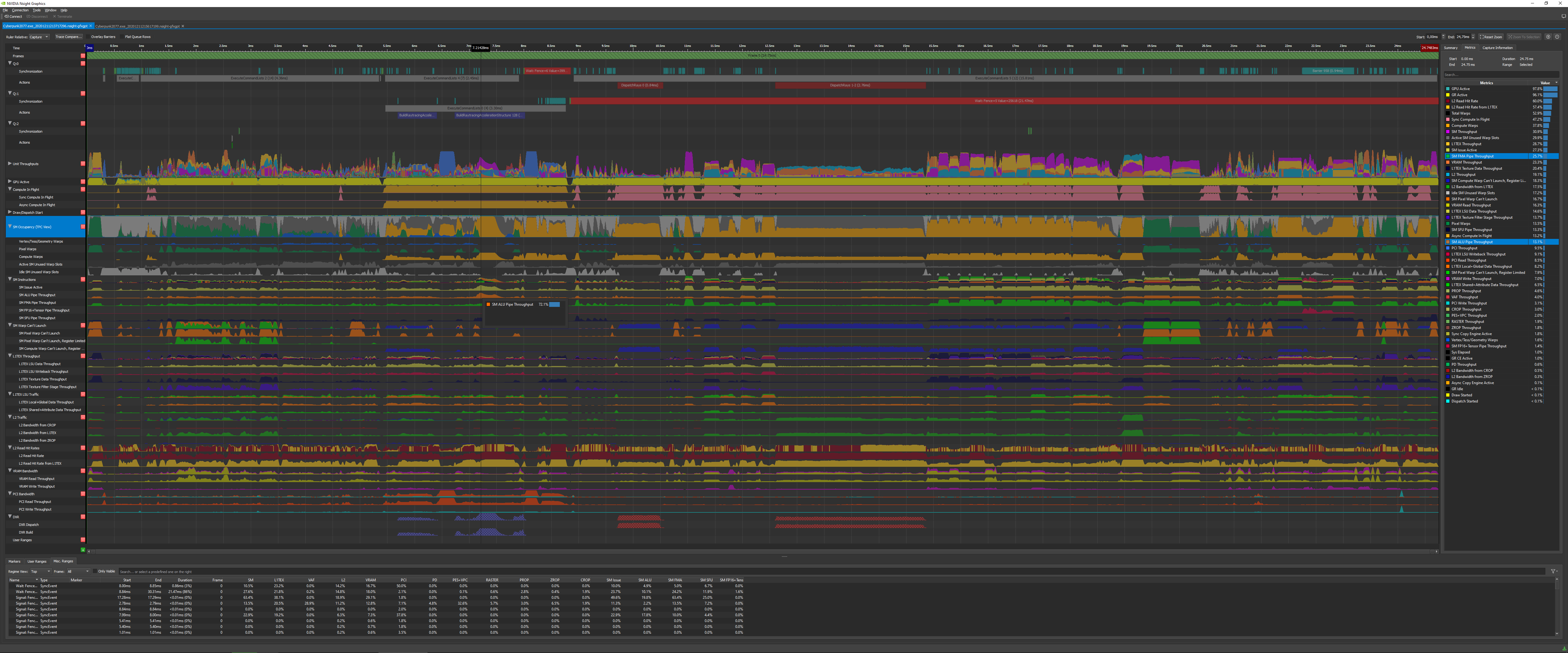
Looking at the highlighted "SM Occupancy" row, the "background" behind the mostly green and mustard areas is either dark or light grey. The key seems to imply that those areas are "Active SM unused warp slots" and "Idle SM unused warp slots". Is that the correct interpretation?
There's 3.6ms of "Dispatch Rays", which is about 14.5% of the frame time.
There's 3.6ms of "Dispatch Rays", which is about 14.5% of the frame time.
Man from Atlantis
Veteran
Looking at the highlighted "SM Occupancy" row, the "background" behind the mostly green and mustard areas is either dark or light grey. The key seems to imply that those areas are "Active SM unused warp slots" and "Idle SM unused warp slots". Is that the correct interpretation?
There's 3.6ms of "Dispatch Rays", which is about 14.5% of the frame time.
Yeah, it seems correct. Also BuildRaytracingAccelerationStructure takes 2.01ms which in total with dispatch RT takes 22.3% of the frame time. DLSS Quality (barrier 958) takes 0.94ms as well.
There's 3.6ms of "Dispatch Rays", which is about 14.5% of the frame time.
Im surprised at the relatively low memory activity during ray dispatch. VRAM is barely touched and L2 hit rates aren’t spectacular. A piece of the puzzle seems to be missing.
Edit: actually L2 rates look decent. I suppose that means the BVH doesn’t require that much space and can fit into the relatively small L2.
RE: Cyberpunk 2077 performance:
There's a fix/edit for those with Ryzen CPUs to increase minimum frames by around 10-15%:
tl;dr: there seems to be an issue with the game running a CPU check based on GPUOpen. It basically causes the game to assign non-Bulldozer AMD CPUs less schedulers threads. People suspected it was due to some kind of gimping due to ICC, but this is not the case.
Hopefully this'll be addressed in an upcoming patch.
There's a fix/edit for those with Ryzen CPUs to increase minimum frames by around 10-15%:
tl;dr: there seems to be an issue with the game running a CPU check based on GPUOpen. It basically causes the game to assign non-Bulldozer AMD CPUs less schedulers threads. People suspected it was due to some kind of gimping due to ICC, but this is not the case.
Hopefully this'll be addressed in an upcoming patch.
Jawed
Legend
If we were developers with the code at hand, I suppose we could go into more detailed profiling here, e.g. all of the different ray tracing settings, singly and combined, versus off, and various resolutions and DLSS settings.Yeah, it seems correct. Also BuildRaytracingAccelerationStructure takes 2.01ms which in total with dispatch RT takes 22.3% of the frame time. DLSS Quality (barrier 958) takes 0.94ms as well.
It would turn into quite a quagmire!
There are three "can't launch" metrics:
- 16.7% of SM Pixel Warp Can't Launch
- 7.9% of SM Pixel Warp Can't Launch, Register Limited
- 18.3% of SM Compute Warp Can't Launch, Register Limited
Jawed
Legend
Rys woz there:tl;dr: there seems to be an issue with the game running a CPU check based on GPUOpen. It basically causes the game to assign non-Bulldozer AMD CPUs less schedulers threads. People suspected it was due to some kind of gimping due to ICC, but this is not the case.
Updated getDefaultThreadCount() to better represent other vendor posi… · GPUOpen-LibrariesAndSDKs/cpu-core-counts@49a6e73 (github.com)
from 27 September 2017 (about half a year after Ryzen first launched). This commit inverts the behaviour on Intel CPUs (is that good, was that intentional?) and seems to knobble Ryzen in this game (isn't there a thread about Cyberpunk 2077 performance yet?). Maybe original Ryzen liked it this way?
At least developers can change the code.
Pull request has been opened:
Fix for incorrect thread count reporting on zen based processors by samklop · Pull Request #3 · GPUOpen-LibrariesAndSDKs/cpu-core-counts (github.com)
which references this page and slide deck:
CPU Core Count Detection on Windows® - GPUOpen
gdc_2018_sponsored_optimizing_for_ryzen.pdf (gpuopen.com)
with a justification: "But games often suffer from SMT contention on the main thread".
It's notable that "The sample code exists for Windows XP and Windows 7 now, with Windows 10 coming soon. The Windows 10 sample will take into account how CPU sets are used in Game Mode, a new feature released as part of the big Windows 10 Creators Update earlier this year."
No change for Windows 10 was ever made. There's no indication for the reason: not worthwhile or makes no difference... The commit:
Updated Readme to indicate Windows 10 support · GPUOpen-LibrariesAndSDKs/cpu-core-counts@7c2329a (github.com)
merely implies that Windows 10 is supported.
What the gpu or driver do when the "can't launch" event is happening ?
I believe the can’t launch numbers represent the difference between the number of active warps that have been launched and the theoretical max. It’s not necessarily a bad thing. You can have full utilization of the chip without launching the max number of warps possible though more is usually better to ensure you have a lot of memory requests in flight.
Note this only refers to the number of warps being tracked by the SMs. It doesn’t refer to instruction issue each clock which is the actual utilization of the chip.
Jawed
Legend
In theory the GPU and the driver can each notice these problems occurring and alter the way that the individual units of the GPU are being used. This might be as simple as changing the rules for priority. It's an extremely difficult subject, because the time intervals are miniscule: it might not be possible to change something quickly enough to get a useful improvement.What the gpu or driver do when the "can't launch" event is happening ?
You could argue that GPUs are "too brittle" and there are dozens of opportunities for bottlenecks to form due to the design of the hardware and the count of each type of unit (rasteriser, SM, ROP and all the little buffers). The picture posted earlier shows dozens of metrics. Most of those represent an opportunity for a bottleneck. There's so many little machines inside the "GPU machine", and any of those can cause serious bottlenecks.
This is why I was a big fan of Larrabee. The opportunities for bottlenecks are almost entirely, solely, software. Sure, you have limitations on clock speed, core count and cache sizes, but there's also a massive opportunity to work smarter not harder. Hardware, on the other hand, does some simple things extraordinarly efficiently and it's really hard to make software keep up and the opportunities for bugs and unexpected behaviour generally seem worse with software. Hardware is efficient partly because it forces a simplified usage model.
The original design late last century for triangle-based rendering was about a simplified usage model to make a few million transistors do something useful. As time goes by and there's more transistors to play with, it tends to make sense to build GPUs from pure compute (like Larrabee). We're still getting there...
This is similar to the "mesh shader" question. It's difficult for a developer to create mesh shaders that perform as well as the hardware's vertex shader functionality (and including tessellation and geometry shader stages). But if you're smart with your mesh shader design, instead of merely trying to directly replicate what the hardware units do, you can get substantial performance gains. A lot of developers won't want to write mesh shaders, so there needs to be a solution for them. AMD seems to be using "primitive shaders" at least some of the time for developers who don't want to write mesh shaders. Not forgetting that primitive shaders and mesh shaders are much newer designs than pretty much every game that's ever been released.
Similar threads
- Replies
- 357
- Views
- 28K
- Replies
- 3
- Views
- 384
- Locked
- Replies
- 10
- Views
- 861