Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Speaking about Benchmarking V100 - someone has done it on LuxMark
Interesting. It's doing very good in almost all combinations, but it seems to have some multi-GPU scaling issues in the heavy scene? There are not many results, and most are unfortunately not really comparable, but I have the feeling it looks like the heavier the workload gets on multiple GPUs, the lower the advantage gets over other devices.
D
Deleted member 2197
Guest
Top LuxMark (LuxBall HDR) Scores.
http://www.luxmark.info/top_results/LuxBall HDR/OpenCL/GPU/1
Top Hotel results.
http://www.luxmark.info/top_results/Hotel/OpenCL/GPU/1
http://www.luxmark.info/top_results/LuxBall HDR/OpenCL/GPU/1
Top Hotel results.
http://www.luxmark.info/top_results/Hotel/OpenCL/GPU/1
Last edited by a moderator:
Ext3h
Regular
What you mean? The top 2 results look fishy - "gfx900" ??? - and the the array of 4x V100 was only beaten by a setup with 7 Pascal + 2 Maxwell cards.
Bondrewd
Veteran
That's Vega."gfx900"
Dayman1225
Newcomer
According to the man who ran them it was 190w
What you mean? The top 2 results look fishy - "gfx900" ??? - and the the array of 4x V100 was only beaten by a setup with 7 Pascal + 2 Maxwell cards.
That's the question. The same user has LuxBall HDR (simple scene) results at place 9 and 10 with 4x Vega, less than half of Anaconda's 4xV100. On Hotel (complex scene) it's 1 and 2 for 4x Vega, and that's 1.5x more than Anaconda's results. So I guess something is wrong with the V100 results, the question is: what?
Ahh, the two very good results seem to be using ROCm 1.6.4, the other are under Windows.
Last edited by a moderator:
D
Deleted member 2197
Guest
NVIDIA DGX Station Upgraded to Tesla V100
October 28, 2017
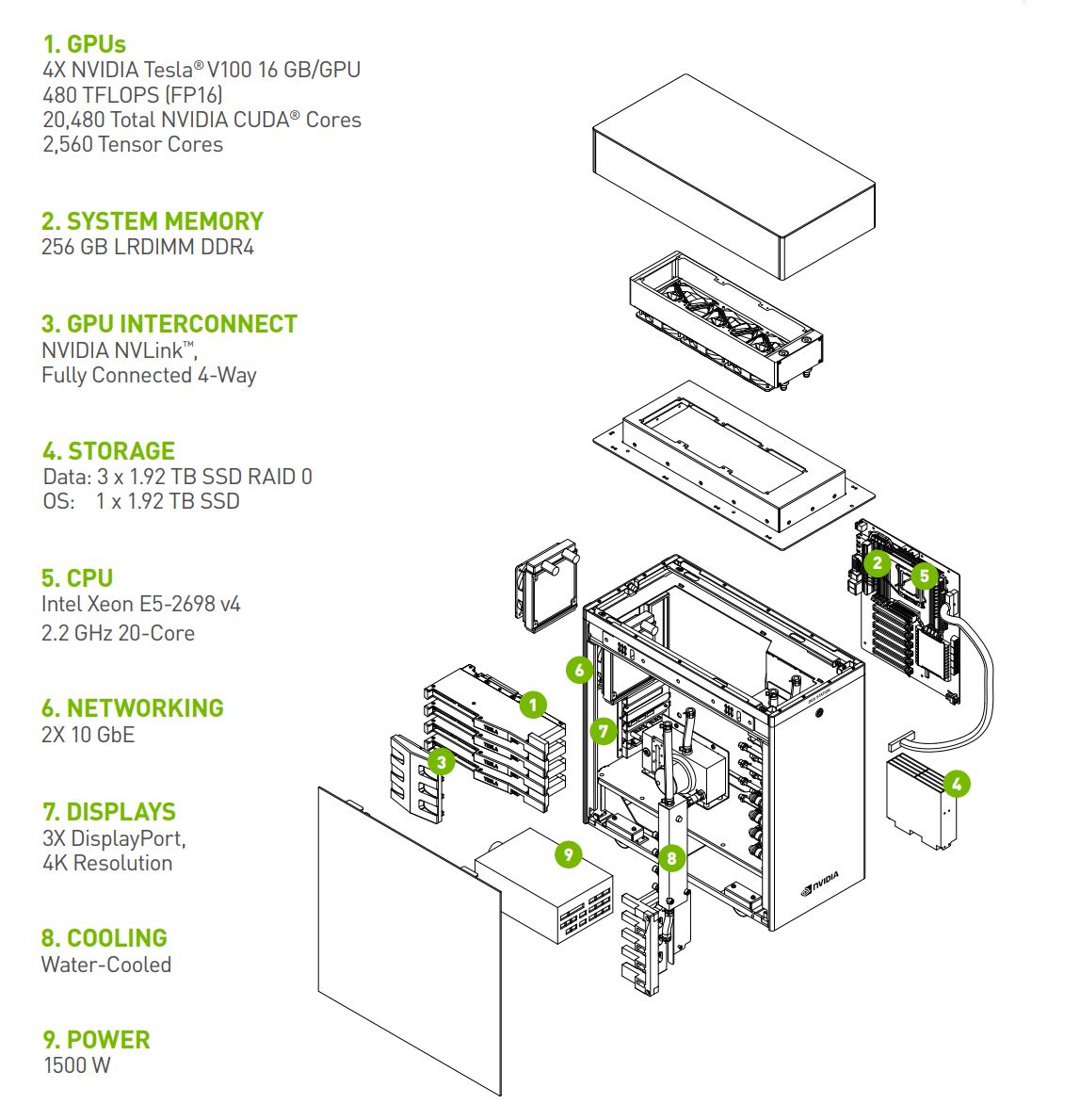
October 28, 2017
At launch, it was powered by four NVIDIA Tesla P100 GPUs but it is now powered by four NVIDIA Tesla V100 GPUs. Here are the key specs of the updated machine.
https://www.servethehome.com/nvidia-dgx-station-upgraded-tesla-v100/Sporting the new NVIDIA Tesla V100 with Tensor Core technology for $69,000 you can own a dedicated system for about the same price as 1-year of cloud instance pricing. For example, an AWS p3.8xlarge instance with all up-front pricing is $68301 for 1-year.
Last edited by a moderator:
D
Deleted member 87499
Guest
V100 being ready this early is such a great achievement.
Bondrewd
Veteran
Why?V100 being ready this early is such a great achievement.
It's an 815mm GPU, 33% larger than anything I've heard of being mass producedWhy?
Bondrewd
Veteran
They kindly asked TSMC to push the reticle limit forward.It's an 815mm GPU, 33% larger than anything I've heard of being mass produced
Thats nothing groundbreaking or anything. The node is very mature so the yields must be in >1.7% range.
D
Deleted member 87499
Guest
Is ahead of the two year cadence that Nvidia updates the architecture.
Bondrewd
Veteran
They need to do something before various ML/DL ASICs flood the market. V100 kinda works. Not the most cost effective solution, but it'll do.Is ahead of the two year cadence that Nvidia updates the architecture.
$NVDA is one hell of a bubble fueled by meme learning and they will do anything to not let it pop.
They kindly asked TSMC to push the reticle limit forward.
Thats nothing groundbreaking or anything. The node is very mature so the yields must be in >1.7% range.
Any data to back up this yield number?
If you include other critical factors such as HPC/AI large scale power requirements/power budget then it is a pretty important product for many out there or look at those that do DP scientific modelling where no other product touches this.They need to do something before various ML/DL ASICs flood the market. V100 kinda works. Not the most cost effective solution, but it'll do.
$NVDA is one hell of a bubble fueled by meme learning and they will do anything to not let it pop.
The closest general AI product to compare would be Google TPU2, and that does not necessarily match performance/efficiency of the V100 that combines a mixed-precision product with AI capability - been covered in the past by a few others here.
There is also the half height V100 which is more stripped down.
Also one pretty important consideration will be V102, just look at how the GP102 outperformed the GP100 in more common situations.
The one product that could cause a ripple for Nvidia is from Intel (beyond Xeon Phi), but depends how long it takes to really get everything aligned (HW arch more broadly and software) with their Nervana techi.
Last edited:
He's being cheeky. 1.7% would be 1 GV100 per wafer.Any data to back up this yield number?
Bondrewd
Veteran
Charlie would've liked it. :^)1.7% would be 1 GV100 per wafer.
The V100 results show the expected perfect scaling, with the 4x number being exactly 4x the performance of the 1x.That's the question. The same user has LuxBall HDR (simple scene) results at place 9 and 10 with 4x Vega, less than half of Anaconda's 4xV100. On Hotel (complex scene) it's 1 and 2 for 4x Vega, and that's 1.5x more than Anaconda's results. So I guess something is wrong with the V100 results, the question is: what?
Ahh, the two very good results seem to be using ROCm 1.6.4, the other are under Windows.
The V100 single GPU score for Hotel is 12770. Which is “only” about 20% or so faster than a GP100 after correcting for cores and BW. A very good result, but not unexpected or terribly surprising if you look at the general architectural improvements.
The best single GPU score for gfx900 is 6526. It uses OpenCL 2.0 AMD-APP (2482.4). That number more or less matches a 1080Ti, which makes sense given that they have roughly the same amount of TFLOPS and BW.
The 4x score for gfx900 is 77530, or a whopping 19382 per unit, using OpenCL 2.0 AMD-APP (2508.0).
So one way or the other, AMD manages to triple the performance of its OpenCL drivers, way beyond what could reasonably be expected from the amount of TFLOPS and BW.
Or the alternative: those results are completely bogus.
")
Similar threads
- Replies
- 135
- Views
- 6K
- Replies
- 67
- Views
- 12K
- Replies
- 209
- Views
- 14K
- Locked
- Replies
- 10
- Views
- 1K