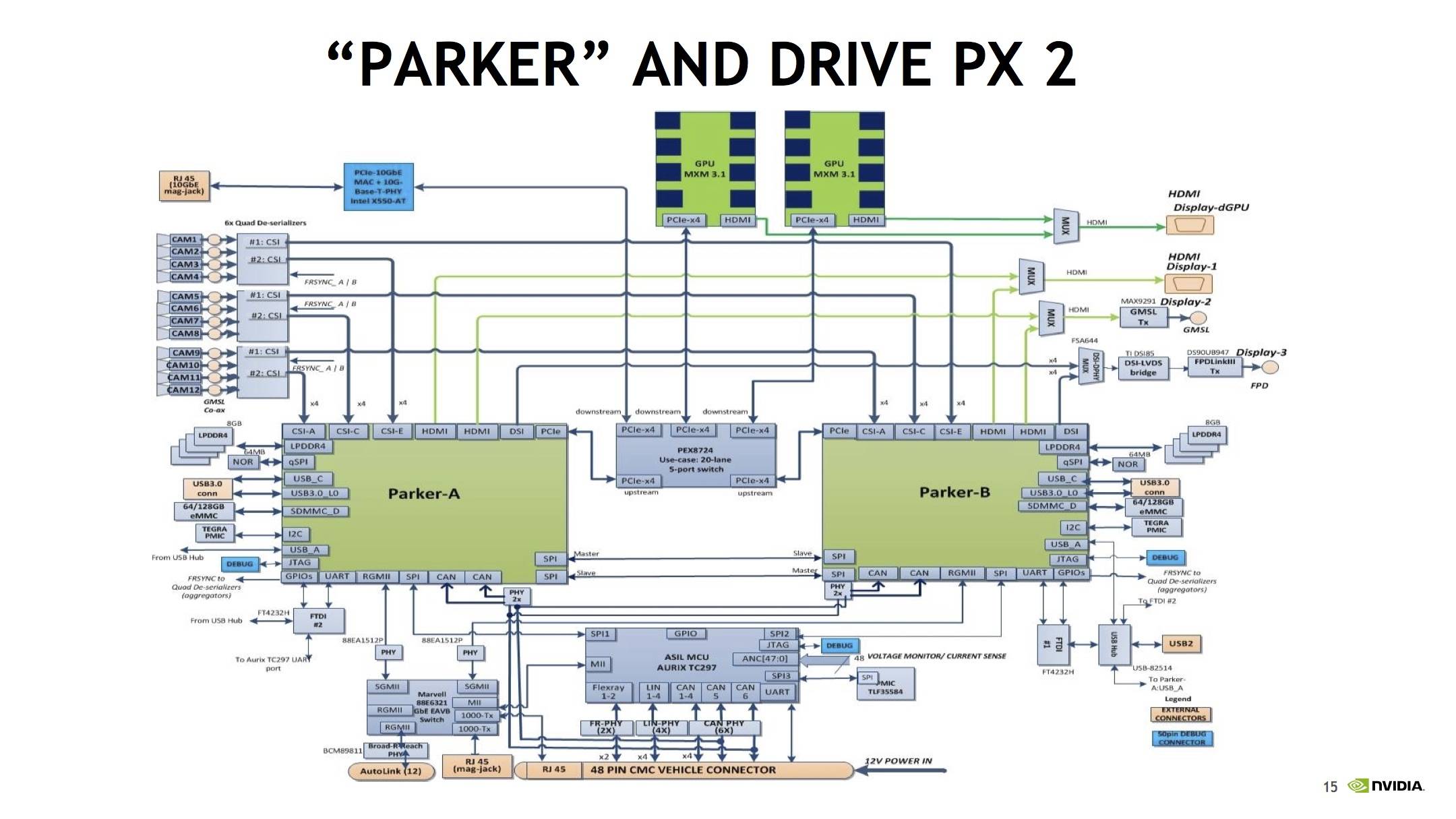
Why didn't they roll with A72's? Or is that just a marketing thing.
My guess is that there was faster time to integration because they could leverage past work done on X1. They could have tacked on the A57s relatively late, when they realized they weren't winning enough benchmarks anymore with the Denver cores alone.