http://blogs.nvidia.com/blog/2014/08/11/tegra-k1-denver-64-bit-for-android/
http://www.tiriasresearch.com/downloads/nvidia-charts-its-own-path-to-armv8/ - register to get whitepaper, it's free
So it's code morphing CPU with hardware ARM decoders, it searches for hot portions of code(heavy loops, etc) and optimises them, then it saves optimized translation to the memory to perform up to 7 native instructions per cycle for next iterations, the end result is quite amazing considering it's an in-order CPU
Some results:
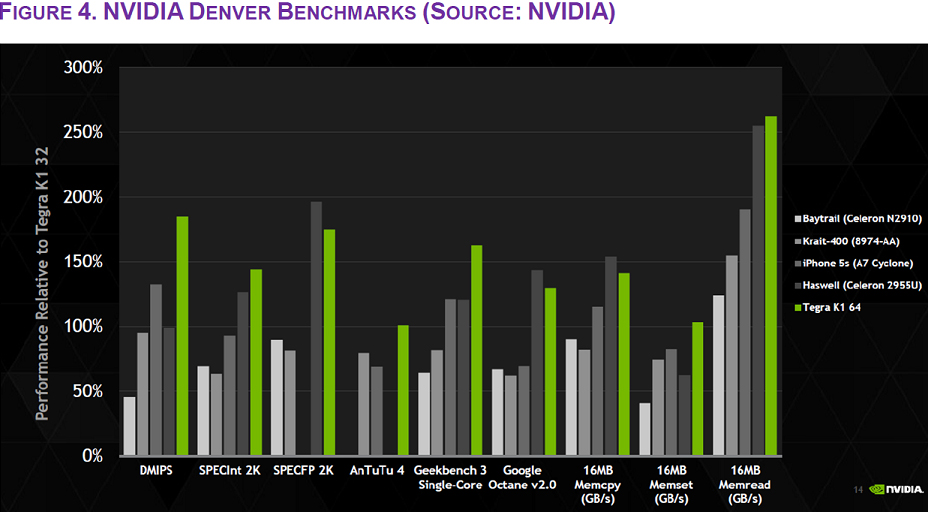
A7 results are amazing too
http://www.tiriasresearch.com/downloads/nvidia-charts-its-own-path-to-armv8/ - register to get whitepaper, it's free
So it's code morphing CPU with hardware ARM decoders, it searches for hot portions of code(heavy loops, etc) and optimises them, then it saves optimized translation to the memory to perform up to 7 native instructions per cycle for next iterations, the end result is quite amazing considering it's an in-order CPU
Some results:
A7 results are amazing too
Last edited by a moderator:
