DavidGraham
Veteran
Stand outs:
In direct comparisons with previous-generation models, the RTX 5090 shows 30-40% performance increase without DLSS 4
With DLSS on, gamers not only enjoy improved frame rates but also reduced latency, when considering absolute milliseconds
Usage statistics indicate that over 80% of RTX players enable DLSS during gameplay, with a cumulative total of 3 billion hours of DLSS-enabled gaming
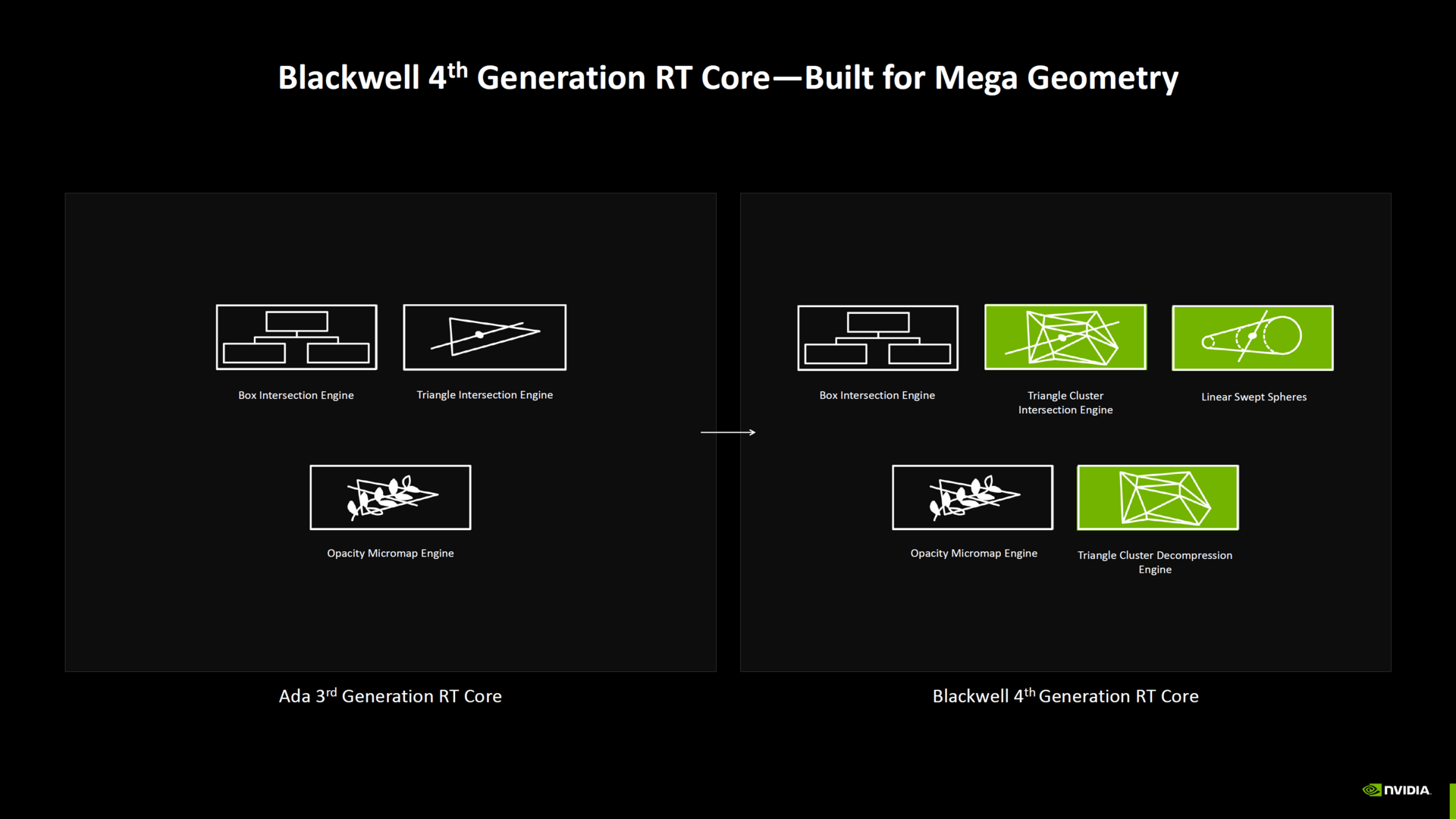
Double RT throughput on ray tracing units
The Shader Executive Reordering introduced with Ada Lovelace is now intended to be done twice as fast at Blackwell as quickly as with the predecessor
cores include a triangle cluster intersection engine designed specifically for handling mega geometry
Ray Tracing on Blackwell is expected to require 25 percent less graphics card memory than Ada Lovelace