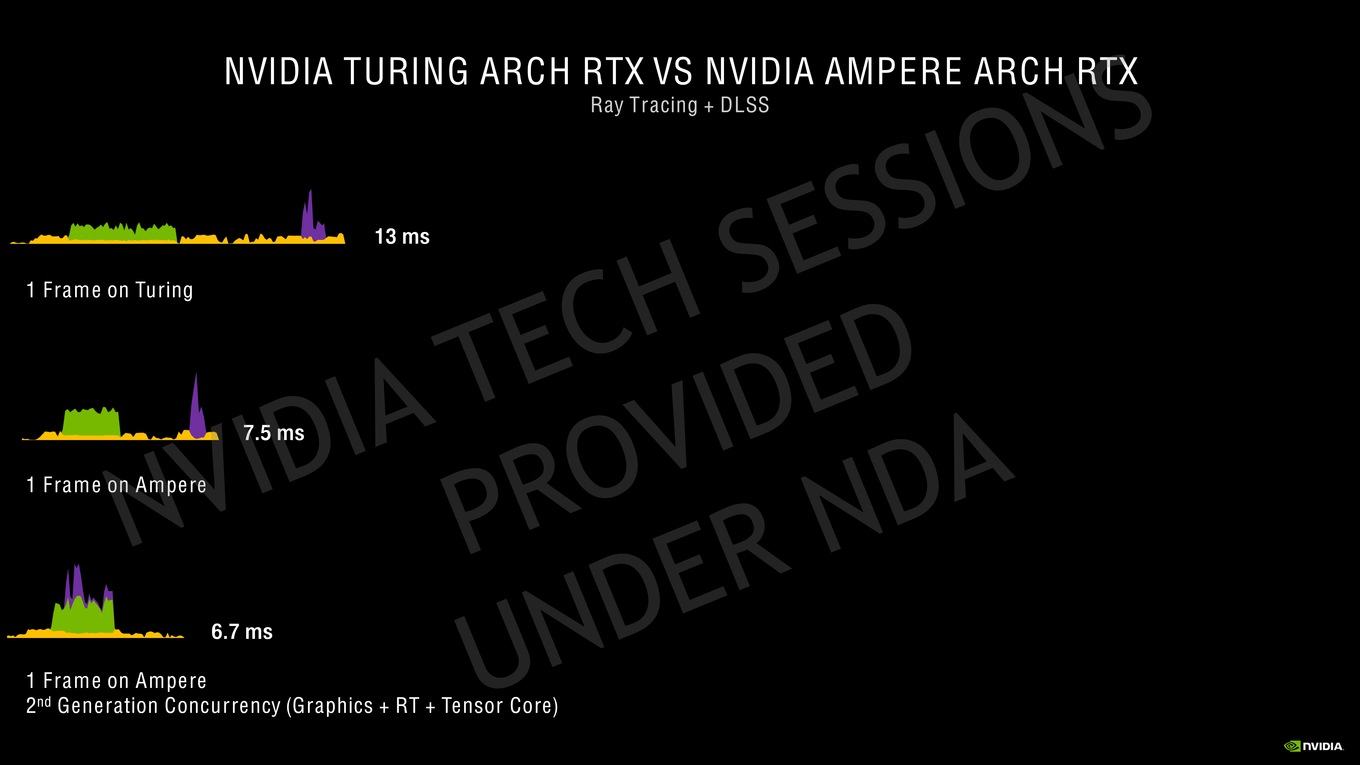
From the hothardware link:
"With Ampere,
NVIDIA wanted to be able to process Bounding Box and Triangle intersection rates in parallel. So, Ampere’s separate Bounding Box and Triangle resources can run in parallel, and as mentioned, Triangle Intersection rates are twice as fast.
A new Triangle Position Interpolation unit has also been added to Ampere to help create more accurate motion blur effects."
Sounds like pretty significant speedups to ray tracing. The triangle position interpolation is interesting. So frame to frame they can interpolate a new position and if it's outside the current triangle intersection then I guess they can go and test a new intersection. Different from having to test the bounding box and triangle intersection every frame.