DegustatoR
Legend
Not really. "Low frequency AD102" implies that it's not a 4090 but a low clocked 4090.Seems the "Easy 2x" is 4090.
But anyway all these "leakers" are fairly clueless right now.
Not really. "Low frequency AD102" implies that it's not a 4090 but a low clocked 4090.Seems the "Easy 2x" is 4090.
You are looking at up to 384 ROPs on the next-gen flagship versus just 112 on the fastest Ampere GPU, the RTX 3090 Ti. There are also going to be the latest 4th Generation Tensor and 3rd Generation RT (Raytracing) cores infused on the Ada Lovelace GPUs which will help boost DLSS & Raytracing performance to the next level. Overall, the Ada Lovelace AD102 GPU will offer:
Do note that clock speeds, which are said to be between the 2-3 GHz range, aren't taken into the equation so they will also play a major role in improving the per-core performance versus Ampere. The NVIDIA GeForce RTX 40 series graphics cards featuring the next-gen Ada Lovelace gaming GPUs are expected to launch in the second half of 2022 & are said to utilize the same TSMC 4N process node as the Hopper H100 GPU.
- 2x GPCs (Versus Ampere)
- 50% More Cores (Versus Ampere)
- 50% More L1 Cache (Versus Ampere)
- 16x More L2 Cache (Versus Ampere)
- Double The ROPs (Versus Ampere)
- 4th Gen Tensor & 3rd Gen RT Cores

kopite thinks that ada will now have 32 ROPs/GPC so 384 ROPs in total. is that really realistic?
Hypotetical, can you have more "simpler/smaller" rops, so you have a better utilisation, maybe some performances gain, without taking more die space or something like that ?
The way Nvidia and AMD count ROPs it’s one ROP = one pixel. So you can’t really go any smaller than that.
Ampere has 16 ROPs per GPC but it doesn’t tell us much about the granularity of their operation. A global memory transaction on Nvidia hardware is 32 bytes which is enough for 8xINT8 pixels or 4xFP16 pixels. I’ve always assumed ROPs operated on quad granularity. So those 16 ROPs can work on 4 independent pixel quads instead of one contiguous tile of 16 adjacent pixels. This is just an assumption though as I couldn’t find any evidence to support it.
Did Nvidia ever move to full speed FP16 fill rate? The most recent numbers I could find are from Pascal which was still half speed.
https://www.hardware.fr/articles/948-9/performances-theoriques-pixels.html
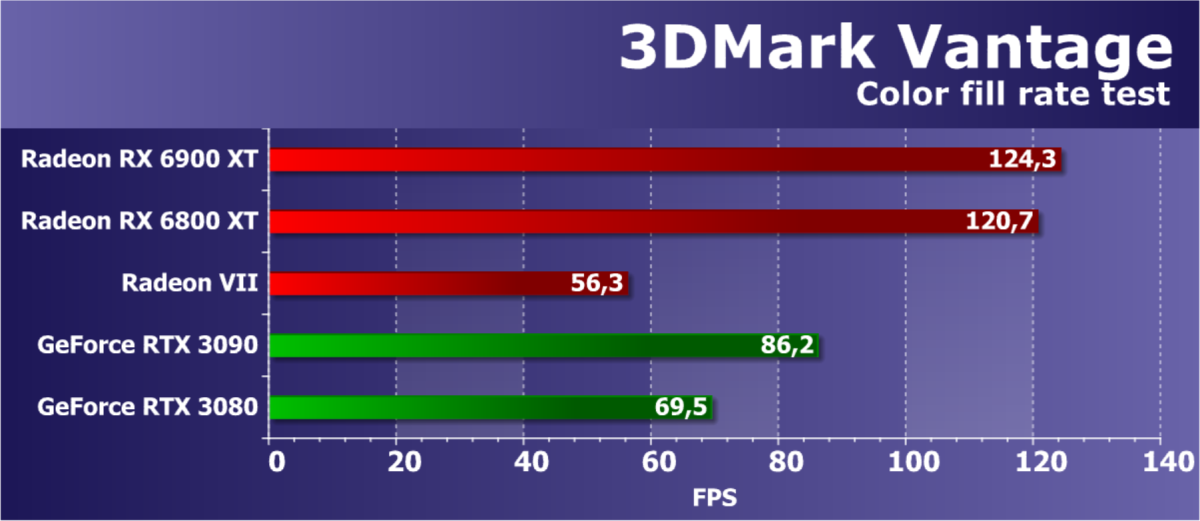
https://www.ixbt.com/3dv/amd-radeon-rx-6900xt-review.htmlFeature Test 2: Color Fill
The second task is the fill rate test. It uses a very simple pixel shader that does not limit performance. The interpolated color value is written to an offscreen buffer (render target) using alpha blending. It uses a 16-bit FP16 off-screen buffer, the most commonly used in games that use HDR rendering, so this test is quite modern.
The numbers from the second subtest of 3DMark Vantage usually show the performance of the ROP units, without taking into account the amount of video memory bandwidth, and the test usually measures the performance of the ROP subsystem
Feeding three 32 wide SIMDs with one 32 thread dispatch port is what completely unrealistic in this picture.
kopite thinks that ada will now have 32 ROPs/GPC so 384 ROPs in total. is that really realistic?
Along the same lines, but I suppose "bigger", isn't this what happened with RDNA 2 versus RDNA 1? For VRS the colour rate was doubled, but other rates left alone, I guess. RB+Hypotetical, can you have more "simpler/smaller" rops, so you have a better utilisation, maybe some performances gain, without taking more die space or something like that ?

Yes and more things that they don't disclosure in public. The obvious one is the usage of their Selene supercomputer for intensive algorithm/RTL/floor plan verification. Nvidia spend much more time than before in simulation and their silicon verification lab is now a huge department in order to shorten tape out to HVM time. For small dies like GA106-107, tape out to HVM was less than 5 months and it should be even less for Ada
RT was a given. Compute too given the direction in architecture Nvidia started with Ampere.Today got a surprising comment from my usual source about AD102 vs Navi31:
"Easy win in RT and Compute"
(for green team)
Did Navi31 perf leak? Jetbait game?
No idea but it's spicy!
What else is there?RT was a given. Compute too given the direction in architecture Nvidia started with Ampere.
Who expected them to be the leader? The expectation was that they may win in "rasterization" in the highest pricing tier.wonder what amd messed up. We were expecting them to be the leader and nvidia scrambling to match them. How did this do a complete 180 ?
Jetbait
What else is there?
We were expecting them to be the leader and nvidia scrambling to match them.
they may win in "rasterization" in the highest pricing tier