This is kind of far-ranging, so I hope I can keep my thoughts organized. I will try to be clear when I get out of my depth past higher-level concepts and start speculating about more low-level details.
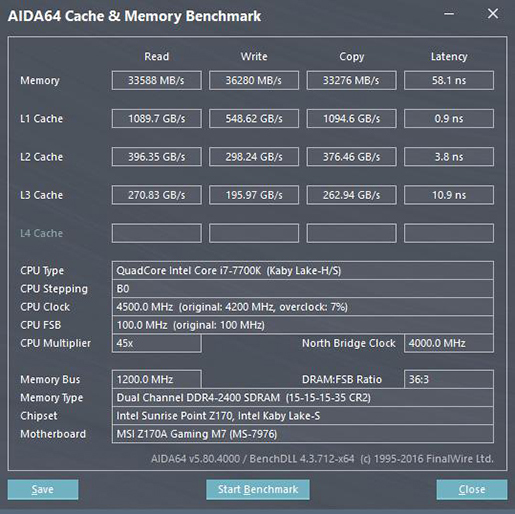
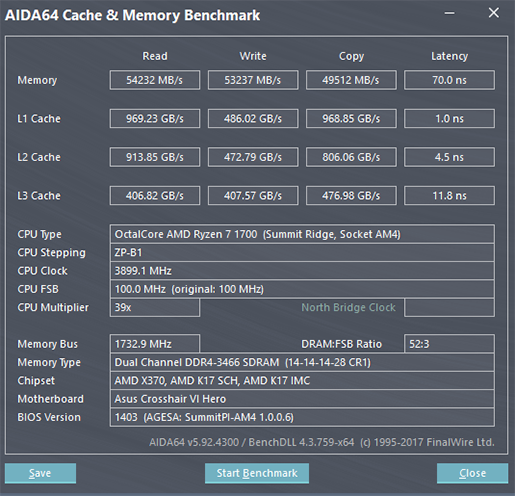
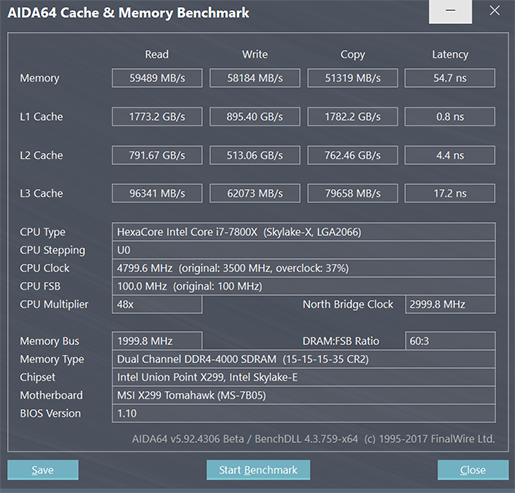
It would be interesting to know why AMDs L3 is so slow, because it only serves four cores. Does victim cache and cross-cluster traffic add significant latency (even when not needed)?.
One correlation of a sort for why AMD's L3 is slow for the number of clients it has is that AMD has seemingly always been conservative with its L3s, or perhaps more broadly not been as capable with caches as Intel has been.
Somewhat separate is the choice to not have a shared last-level cache, which may not entirely overlap with the decision to make the L3 a (mostly) exclusive victim cache.
The shadow tag macros that allow the L3 complex to handle intra-CCX snoops are a serializing step, which can take more than one iteration based on the rather simple 4-way banking and a two-stage early tag comparison. The L3 check appears be held until after that point.
Those add some amount of latency, and the clock and voltage behavior of the L3 and CPU domains is not as simple. The L3 matches the fastest core, and the individual cores and clients may be running at different per-core voltages and a subset of clock offsets, which would be crossing multiple domains and add synchronization latency.
The L3 and L2 arrays have their own voltage rail, which may be another domain crossing.
If Zen aggressively gates arrays off, there may be wakeup latency in it.
The L3 isn't fully exclusive, as there is some level of monitoring for sharing that might make it maintain lines, so it's not a straightforward exclusive cache.
AMD's cache is optimized for cache to cache transfers if there is data in other L2s, which I'm curious about. For certain situations, it may save some trips to the L3 if a line needs to be written out of one L2 and can move to the other without arbitrating an L3 allocation.
By comparison, the non-mesh Intel L3 can make a determination of line status, sharing, and potentially return a response from one hit to one specific location. AMD's is less centralized, and it's not clear that these overheads can be made to go away. The CCX doesn't know until it wends its way through all these checks, and since the shadow tag macros are supposed to be up to date copies of the L2 tags, there must be some kind of synchronization window to make sure they aren't stale while evaluating them. The nearest directory or filter beyond that is in or across the data fabric.
Of note is that Intel's L3 did have something of a latency bump after the ring bus and L3 were taken out of sync from the cores, which like AMD meant extra time could be taken in cycles missed for synchronization purposes.
Intel's mesh setup modified the interconnect and separated the snoop functionality from the L3 lines, so the conversion to a victim cache isn't the only possible source of latency.
Exactly. That was also my thinking, but IIRC cache coherency protocols become harder. Don't know the hardware details, but this could add latency. Also victim caches aren't used for data prefetching... but I haven't understood why this is a bad thing, since prefetched data is most often used right away on the core that caused the prefetch -> private L2 would be the best place to store it.
Could somebody with better HW understanding explain why victim caches tend to be slower and smaller.
One part of why victim caches can be slower and smaller is that they aren't required to be big enough to match the upper caches, and be fast enough to not hold them back. If an implementation could be big enough and fast enough, would a designer pick a victim cache?
There are two notable dimensions to the recent AMD and Intel L3s. One is how inclusive/exclusive they are, and the other is how broadly each level of cache is shared.
Intel's ring-bus and inclusive LLC effectively embeds a snoop filter into the L3. A hit in the L3 answers whether a snoop needs to be generated, and to which cores it should be sent. Having varying levels of inclusion in the upper caches allows them to avoid having to service snoops at speed, which can cause them to be unable to service tag checks or requires duplicate tags that can service snoops in parallel with normal operation.
I think the reduction in clients that need to worry about coherence may have some benefits in reducing the complexity of the implementation. At least conceptually, having a more local check with data and line status in one spot instead of querying distant and non-synchronous clients with various time windows of inconsistent state makes it easier to avoid hidden corner cases.
Bulldozer's many clients were such that I think it might have played a role in why Agner Fog's testing showed that L1 bandwidth went down if more than one core was active on-chip, and may have contributed to the TLB bug for Phenom. The TLB bug was an issue where line eviction from the L2 to L3 of a page table entry in the same period as that entry being modified by a TLB update might allow a separate core to snoop the stale copy from the L3.
I don't know if a more inclusive LLC and hierarchy could have prevented it, but it seems like there could be ways the design could reduce the number of transitory and physically separated states that could be missed in testing.
As far as prefetching goes, a victim cache can constrain how aggressive hardware prefetchers can be. Intel's L2 hardware prefetcher for the inclusive hierarchies would always move data into the L3, and usually into the L2. The "usual" modifier is a key point in that the cache pipeline may opt to quash prefetches if heavy demand fetches need line fill buffers.
The data prefetched may find use soon, but a burst of memory traffic could halt a prefetcher if all it has is the L2. The distributed L3 and the separate slice controllers can absorb more prefetched lines without thrashing, and could support more outstanding prefetcher transactions than the more in-demand local L2.
As a third way, the most recent IBM Power L3s are not exclusive, but are not fully shared as an LLC. The L3's larger size and resources per partition means it more heavily participates in prefetching. By having local partitions, the local 5-10 or so MB per core has low latency for an L3. There is some level of managed copying of lines to other partitions to get some of the benefits of a shared last-level cache. It doesn't come cheap across multiple dimensions, like complexity, actual cost, and power.
Yeah, always puzzled me why a victim cache would be slower than an inclusive one? I mean -in my understanding- it combines the best of both worlds, it stores evicted data (for later access) and maximizes cache capacity, so what gives?
Exclusivity allows more cache to be available at a given level, but some of the downsides are that it takes extra work to maintain. Strict exclusivity can cause a higher level of cache to load one line from the lower cache, causing the lower cache to invalidate its line. Inserting the new line in the higher cache would likely evict a line from there, which must now move to the lower cache since it is a victim line.
There is more communication and data movement needed in both directions, and while it would be nice to assume the lines could trade places, I'm not sure if the capacity is automatically available because that end of the transaction may be tens of nanoseconds out and the core needs to keep moving. These operations are occurring over an internal pipeline and may be arbitrating with other traffic and sharing cores before the operation is fully completed. It's possible further eviction activity could propagate down if the victim cache keeps to its own LRU policy and shuffles yet another dirty line out. That makes the cost of otherwise unremarkable movement of cache lines through the hierarchy less predictable and expensive in terms of implementation complexity and data movement.
For a fully inclusive cache, it's already known there's room allocated, since it's inclusive. Also, clean lines in the higher levels can be silently and quickly invalidated without significant bandwidth consumption or synchronization with other parts of the chip. It's generally predictable and skips work considered obligatory for the victim cache. There is one form of complication in the case of an inclusive LLC, if sufficient thrashing causes it to drop a line that is also higher in the hierarchy. Back-invalidation of shared lines is something that a fully exclusive hierarchy would by default not have to worry about, although if implemented like Intel's inclusive cache the in-use bits would indicate what cores need to have invalidations sent to them.
As process nodes advanced for single core and low-count systems, the utility of having every line in the hierarchy unique reduced. At the same time, the need for speed and power efficiency meant that the higher cache levels were constrained in size and timing budget for other reasons, making the bigger lower level of cache grow even more relative to them.
Higher core counts are what could raise the cost of the LLC to where it might be worth evaluating a victim cache.
Did you manually link to his profile? If you want to generate an alert for him to the post, you need to simply put @ in front of the username.
@3dilettante
Was that supposed to create an alert for me in the usual spot, or somewhere else? I don't recall seeing anything pop up for me.
On the other hand, I did wind up here, somehow...