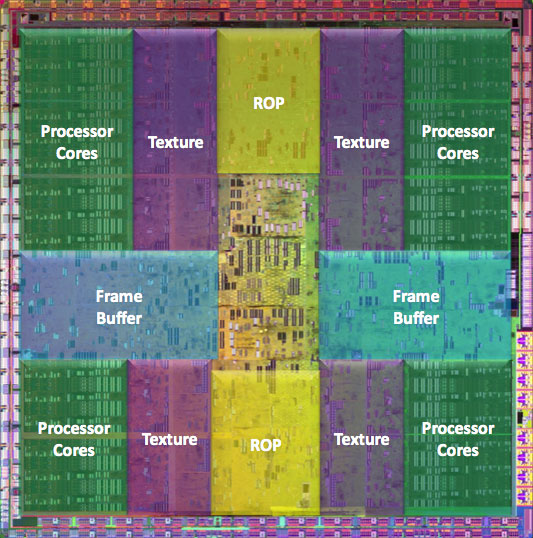
What you've marked doesn't add up to an entire cluster. Could be general control or it could be TMU. Dunno.
Its oddly marked, that's for sure, but there's obviously 10x(3x+1) instances.
For the die shot linked to, I don't believe the areas marked 'SIMD' should cover the area that they do. Each SIMD block does seem to represent 3x of something, but the piece attached to it (which I'm saying shouldn't be part of it) isn't a duplicate on each of the different blocks. It might be a routing issue that's making them look different (and they're only instanced on lower metal layers), but I kinda doubt that.
I don't think that what that person has labeled as the same thing on the lower and left hand edges are actually the same thing.
What I see is
4x(3x)--what's mark SIMD
8x --what's marked octo-dunnos
8x --what's marked QTU on the left
4x --what's marked QROP of the left
8x --what's marked QTU on the bottom
4x --what's marked QROP on the bottom
I'd gather that there are 4 functional units, each composed of:
3x something (SIMD)
2x something (QROP of the left)
2x something (QROP of the bottom)
2x something (OCTO on teh top)
1x something (QTU on the left)
1x something (QTU on the bottom)

 yep!
yep!