DavidGraham
Veteran
I see , thanks for the heads up .Such a 32bit integer multiplication can be constructed from four 16 bit integer multiplies and a series of adds. I hoped 3 would be enough or it would be at least possible to get the full 64bits result with one VLIW instruction group (which should be possible if the adders are fast and wide enough).
Noted :smile: .(A+B) * (C+D) = A*C + A*D + B*C + B*D
When the multiplication is split into N parts, it needs N^2 partial multiplications.
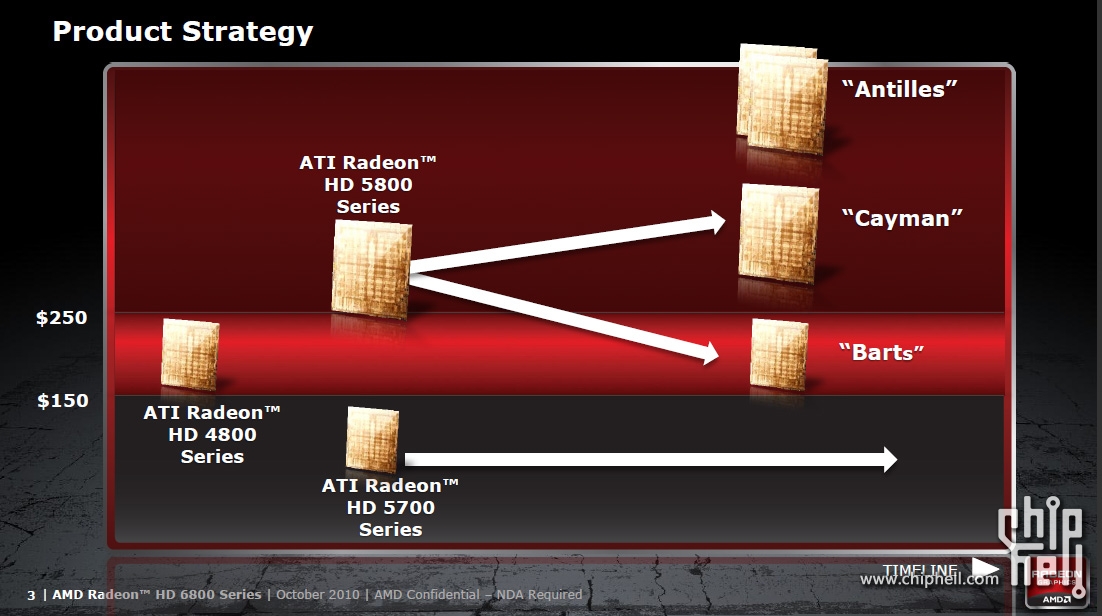
Nope , the good old fashioned 5D ALUs .Slides are out:
oh and 4D!
looks like no-X was right ..
And about the two rasterizers claim , I think this is the same as Cypress has 2 rasterizers .
Die size is 255mm , not 230 !
Last edited by a moderator: