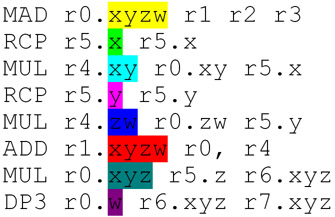
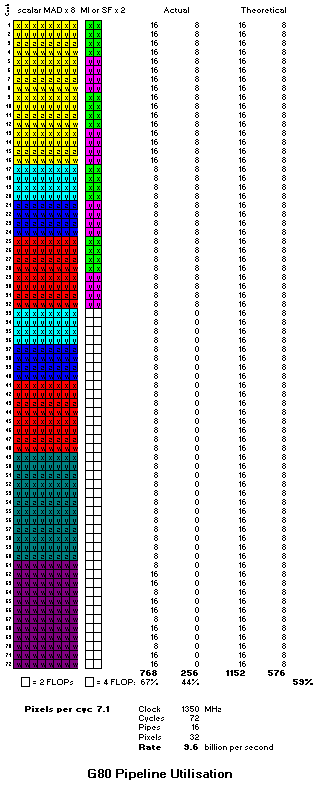
"Fully scalar" would be a single execution pipeline that handles every instruction, with repeats for vector instructions.
Not sure I follow you there...why can't you have a dual-issuable scalar ALU?
As far as I can tell G80 can serialise its instruction issues in a disjoint fashion:
vec2 for 16 pixels
scalar for 32 pixels
vec2 for 16 pixels
where lines 1 and 3 are the same instruction in the program. Each of those 3 lines results in 4 clocks being consumed (the ALU is 8 pixels wide), i.e., each instruction is issued four times. That example doesn't show it, but I believe this is the mechanism by which it can optimise SF/interpolation, which would otherwise cause bubbles in the MAD ALU.
Don't follow this either (sensing a trend here
 ). How would this help with SF scheduling?
). How would this help with SF scheduling?