
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Will NVLINK finally allow better parallelization?
- Thread starter MfA
- Start date
What do you expect afr to be replaced with ?
MfA mentioned one possibility already: sort middle rendering. See http://www.cs.cmu.edu/afs/cs/academic/class/15869-f11/www/readings/molnar94_sorting.pdf for the details of what that is. But basically, your GPUs collaborate on a single frame at a time, reducing rendering latency. There is a work redistribution step between geometry processing and pixel processing, hence the name.
D
Deleted member 13524
Guest
Ever since (nVidia's) SLI first came out, we've all been hoping for unified memory pool between multi-GPUs and something like per-object rendering like Lucid's now defunct Hydra.
Basically the link only need to be fast enough for the two GPUs to share rendered results. Textures can be duplicated, and memory is cheap. So, basically the link only needs to be fast enough for sending the final rendered result (as current AFR implementation) and additionally the off-screen rendering results.
So, to understand how much bandwidth you need, basically you need to estimate how many off-screen renderings are needed, and that can be described as a factor: e.g. you need around 5 times of the on-screen resolution for off-screen rendering, then the factor is 5.
5x PCIe3 is ~ 5GB/s bi-directional. You need ~ 500MB/s for 1920x1080 @ 60 fps, so with that you can do around the factor of 9. However, for modern game engines it's probably a bit too tight. For example, if you do deferred rendering you'll need to render a depth buffer first (that's also has to be shared), which may have to be a higher resolution if you use some sort of multi-sampling AA, and this alone takes out a factor of 4 if you use 4X AA. However, if you only use morphological AA then maybe it's fine, but on the other hand 1920x1080 @ 60 fps is a little too low for a multi-GPU setup.
So, to understand how much bandwidth you need, basically you need to estimate how many off-screen renderings are needed, and that can be described as a factor: e.g. you need around 5 times of the on-screen resolution for off-screen rendering, then the factor is 5.
5x PCIe3 is ~ 5GB/s bi-directional. You need ~ 500MB/s for 1920x1080 @ 60 fps, so with that you can do around the factor of 9. However, for modern game engines it's probably a bit too tight. For example, if you do deferred rendering you'll need to render a depth buffer first (that's also has to be shared), which may have to be a higher resolution if you use some sort of multi-sampling AA, and this alone takes out a factor of 4 if you use 4X AA. However, if you only use morphological AA then maybe it's fine, but on the other hand 1920x1080 @ 60 fps is a little too low for a multi-GPU setup.
That's only true if there is geometry level tiling and the GPU can't do that on it's own ... the only practical way is to assign tiles to GPUs but just divide geometry/vertex shading evenly and sort in the middle, the geometry takes bandwidth in addition to the replication of all rendertargets (which includes can include intermediary stuff like shadow maps).Basically the link only need to be fast enough for the two GPUs to share rendered results. Textures can be duplicated, and memory is cheap. So, basically the link only needs to be fast enough for sending the final rendered result (as current AFR implementation) and additionally the off-screen rendering results.
Blazkowicz
Legend
5x PCIe 3, if that means five times the bandwith of PCIe 16x 3.0, would be about 80GB/s bi-directionnal.
That's only true if there is geometry level tiling and the GPU can't do that on it's own ... the only practical way is to assign tiles to GPUs but just divide geometry/vertex shading evenly and sort in the middle, the geometry takes bandwidth in addition to the replication of all rendertargets (which includes can include intermediary stuff like shadow maps).
Yeah, I forgot about geometry shaders. However, to my understanding geometry shaders tend to be not as computation/bandwidth intensive as pixel rendering. So in order to avoid possible pipeline bubbles it might be faster to just replicate the works on both GPU.
5x PCIe 3, if that means five times the bandwith of PCIe 16x 3.0, would be about 80GB/s bi-directionnal.
Yeah, for HPC applications it's probably more likely to be the case.
If we can have this bandwidth on normal PC based multi-GPU set up then it could be a game changer.
When I read about it I first though of the implications for the CPU side of things. Nvidia has stated that they wanted to have denver cores in every GPU mid term, they need a bus to connect coherently multiple SoCs.
It may help with multi GPU in a gaming rig, I don't know but I guess the primary purpose is more on the compute side of things, like selling "all Nvidia" CUDA stations without Intel or AMD CPUs being required.
It may help with multi GPU in a gaming rig, I don't know but I guess the primary purpose is more on the compute side of things, like selling "all Nvidia" CUDA stations without Intel or AMD CPUs being required.
Actually as I said a decade ago, it might make more sense to copy on demand chunks of the dynamic textures since a given tile in screen space will generally only require a small part of an environment/shadow/etc map.replication of all rendertargets
Can we finally say goodbye to AFR with NVLINK or will the misery continue?
I'm sceptical 5xPCIe3 is going to be enough for sort middle parallelization but lets hope I'm wrong.
It *might* be enough for sort middle tiled parallelization.
AMD/NV will never implement sort middle GPUs. Their current architectures are too optimized for sort last.
A more hopeful scenario is that we see multiple graphics queues on a chip, doing sort first parallelization for opaque geometry/g buffer etc.
Internally they already are in some ways because of the ROPs.AMD/NV will never implement sort middle GPUs.
Internally they already are in some ways because of the ROPs.
How so? ROPs make them sort last, not sort middle.
You could make the argument that the triangle setup/raster parallelization introduced with Fermi makes them sort middle to a degree, but that is miles away from sort middle tiled. At realistic triangle rates in desktop, I am doubtful any realistic off chip multi-gpu interconnect wouldn't prove to be a latency and bandwidth bottleneck.
Multi-socket interconnects like QPI etc. *might* work, but they don't seem to be anywhere on the rodmap for multi-gpu systems.
As long as there's longer fps bars in benchmark to be had with any method (in this case AFR), this is gonna stay a wet dream. Remember what/how Multi-GPU launched with (AFR, SFR/Scissoring, Tiling) and to what it evolved today.Can we finally say goodbye to AFR with NVLINK or will the misery continue?
Except, that on latest generation multi-GPU setups, people will rather likely be using higher resolutions - e.g. 3840 x 2160 or multi-mon configurations.5x PCIe3 is ~ 5GB/s bi-directional. You need ~ 500MB/s for 1920x1080 @ 60 fps, so with that you can do around the factor of 9. However, for modern game engines it's probably a bit too tight. For example, if you do deferred rendering you'll need to render a depth buffer first (that's also has to be shared), which may have to be a higher resolution if you use some sort of multi-sampling AA, and this alone takes out a factor of 4 if you use 4X AA. However, if you only use morphological AA then maybe it's fine, but on the other hand 1920x1080 @ 60 fps is a little too low for a multi-GPU setup.
Mintmaster
Veteran
I don't see how sort middle has any hope of becoming reality now that we're way past the single tri per clock era. It could have been done before, but now there's too much data at that stage.Can we finally say goodbye to AFR with NVLINK or will the misery continue?
I'm sceptical 5xPCIe3 is going to be enough for sort middle parallelization but lets hope I'm wrong.
I think object level sorting is the only route to getting rid of AFR, and if XBox 360 wasn't enough impetus to encourage that kind of coarse tiling, then it's a lost cause. The number of gamers who have an SLI system and would buy one game over another because it used an alternative to AFR (likely at lower frame rates) is miniscule.
This design, which Nvidia calls IndeX, allows for scaling of one to n-clusters, and basically makes the solution a function of the checkbook of the researchers.
The IndeX software infrastructure contains scalable computing algorithms that run on a separate workstation or, more likely, a dedicated GPU-compute cluster.
Essentially, IndeX brings together compute cycles and rendering cycles in a single interactive system.
Well, now you can with a GPU-to-GPU inter-linking connection that is called NVlinks. With NVlinks you get scaling of GPUs in a cluster, and scaling of clusters. Just image the bitcoin farming you could do — it boggles the mind.
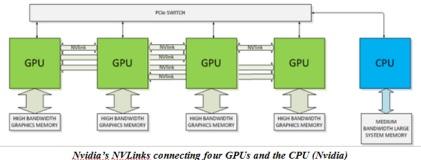
Pascal (the subject of a separate discussion/article) has many interesting features, not the least of which is build-in, or rather I should say, built-on, memory. Pascal will have memory stacked on top of the GPU. That not only makes a tidier package, more importantly it will give the GPU 4x higher bandwidth (~1 TB/s), 3x larger capacity, and 4x more energy efficient per bit.
NVLink addresses this problem by providing a more energy-efficient; high-bandwidth path between the GPU and the CPU at data rates 5 to 12 times that of the current PCIe Gen3. NVLink will provide between 80 GB/s and 200 GB/s of bandwidth.
http://www.eetimes.com/author.asp?section_id=36&doc_id=1321693&page_number=1The numbers are astronomical, and they need to be because the data sizes and rates aren't slowing down and are also astronomical. And, just to make a pun, this now improves astrophysics and astronomy research too. (Nvidia's GPU-compute systems are being used to tease out the beginning of the big bang -- now that's truly BIG data).
Last edited by a moderator:
Similar threads
- Replies
- 32
- Views
- 4K
- Replies
- 21
- Views
- 1K
- Replies
- 22
- Views
- 1K
D