onanie said:
I may be mistaken, but instead of being on the GPU, the stuff you need is just on the edram instead. Perhaps being on a separate die means some cost savings as you suggest.
With eDRAM and the very high bandwidth bus there, there's no need to compress anything. So everything is done uncompressed between daughter logic and eDRAM. Memory controller almost certainly would be significantly more complex to handle such a task as color and z.
Besides, there should be significant advantages to entirely removing the read-modify-write of color and z + blending from main RAM. Turnaround times aren't supposed to be the friendliest, nor (in all likelihood) efficient things in the world.
Having more bandwidth for the GPU by providing the CPU with its own, I imagine, was to achieve the same goal, but perhaps not to the same degree. This is the first time I have heard of redundancy in the edram daughter die.
Redundancy in memory is extremely easy to do. For the most part, where it is doesn't matter so much as a sufficient quantity is there. And without so much specialization, it's easy to add in some redundancy for yields. Logic wouldn't benefit nearly as much without higher prices to be paid.
Perhaps there are more ways to skin a cat. What kind of visual effects does dynamic branching allow exclusively?
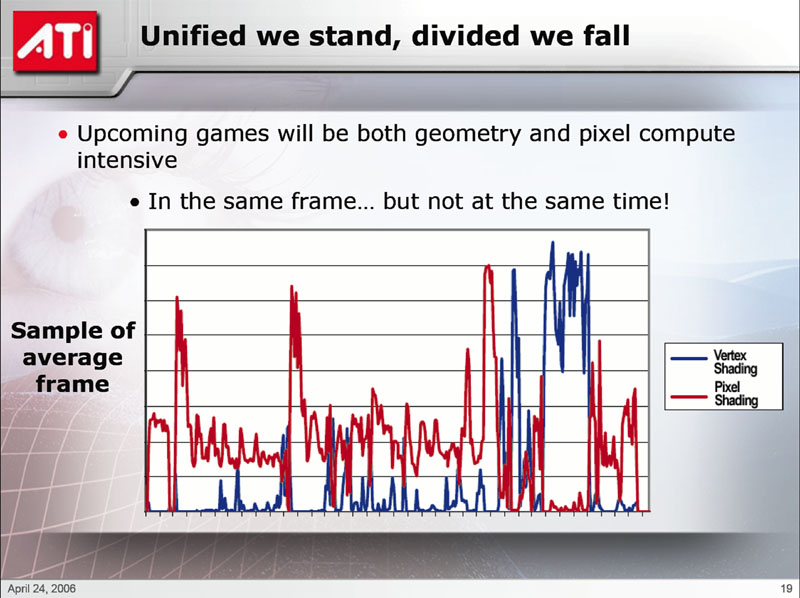
What good can shaders do? What could developers possibly use these multiple render targets for. Why do we need higher instruction limits, we're good enough right here.
To provide argument for a conventional architecture, it is anticipated that the bulk of the work will be in pixel shading, thus the ratio that they have. Certainly, i imagine they have allowed for (what they feel is) enough vertex shaders to avoid pixel shaders stalling in most situations that they have envisioned. It should have a more predictable effect than anticipating how a unified architecture is going to organise itself every instant. The power is there, and in a closed box it can be exploited predictably as the developer sees fit. If more vertex work is required than anticipated momentarily, would it constitute a significant proportion of the total work for an entire scene?
Sure, they might put in enough vertex shaders to "do well enough" but still not cover the worst situation. For example, shadow mapping I'd imagine
could gain some significant speed ups, if you retrieve and write data fast enough outside the vertex shaders to feed them. And no pixel shaders being executed there. I could be talking out my ass though, since I've never had my hands on anything to test something like that. In any case, looking at stuff such as what Jawed posted implies that "matching to the hardware," relative to the ratio of vertex and pixel shaders is, in practice, impossible. Not only do you have the changes from frame to frame, but from part of a frame to part of a frame.
That doesn't mean USA suddenly gets a 40% boost or anything. But there are going to be gains.
However, this doesn't take into account all the numerous situations where the VS load is very high and PS load low. The argument presented that "we haven't seen it before" isn't very good. That's like saying "well, the hardware is absolutely terrible at it, yet we haven't seen it in games, thus there must be no use for it." It's because it hasn't been an option that we dont' see it, not that there aren't uses. That's applicable to the other things that haven't been mentioned. And I think it's things like this that far outweight the "efficiency" gains of Xenos. It certainly seems that many of the things the chip does have are "overlooked" because too many people get caught up in the efficiency hype and ignore the
feature set it brings to the table. Why work harder when you can work smarter. And sometimes you might not need tons of vertices, but maybe you need "smarter" ones whilst at the same time not needing very complex pixel shaders.
I am unconvinced that the RSX ALUs spend all their time texturing. Certainly not what the engineers would have thought, hence their desire to kill two birds with a stone. It is a cost saving measure, but my own view is that if they didn't use a texture lookup unit as a fragment ALU, there would be less ALUs for pixel work. While it is not texturing, then we have a full complement of pixel ALUs (I may be wrong).
Indeed. A generation or a couple generations down the line, I wouldn't expect there to be many different units covering for TMUs, ALUs, and ROPs. NV has a patent, IIRC, where even more of those are consolidated into single units.
If one were to consider the total number of ALUs on both designs, they are comparable. Yet the transistor count is roughly 250 mil (?) for Xenos' primary die, and 300 mil for PS3. What is missing in the Xenos pixel shaders?
Well, for one, you have to consider how they count transistors. There are going to be uncertainties due to the inherently flawed nature of how they're counted (look at a couple examples to find an average # of transistors per gate, look at total number of gates was it?). And then pray that one company doesn't totally ignore certain types of transistors (i.e., look at die sizes between ATI and NV. It makes it seem credible that ATI in fact ignores memory transistors all together. Which could be tens of millions that aren't mentioned for their chips).
predicate said:
So I think to say 'this type of code will run faster on Xenos' is a misleading statement, because developers would never run the same code on RSX.
If that code that runs faster on Xenos performs better than the option available on the other card, why not use it. If Xenos can do the same for less, even if another card uses different techniques and resources, there's the chance you're gaining speed ups relative to that one. Should developers ignore feature advantages, or lack of certain bottlenecks in Xenos because it doesn't run well on the other hardware? Program to each card's strengths. And don't ignore Xenos' strengths for some random reason.
") )?
)?