Hi Guys!
I have been a regular Beyond3D follower since nearly 4 years but this is the first time that i have thought of posting.
Especially with all the multi chip talk for the ATI r680 and r700.I thought it was high time a thread was started.
So heres what i think would be a nice idea, or may be some thing ATI already has up its sleeve in the RV670") .
.
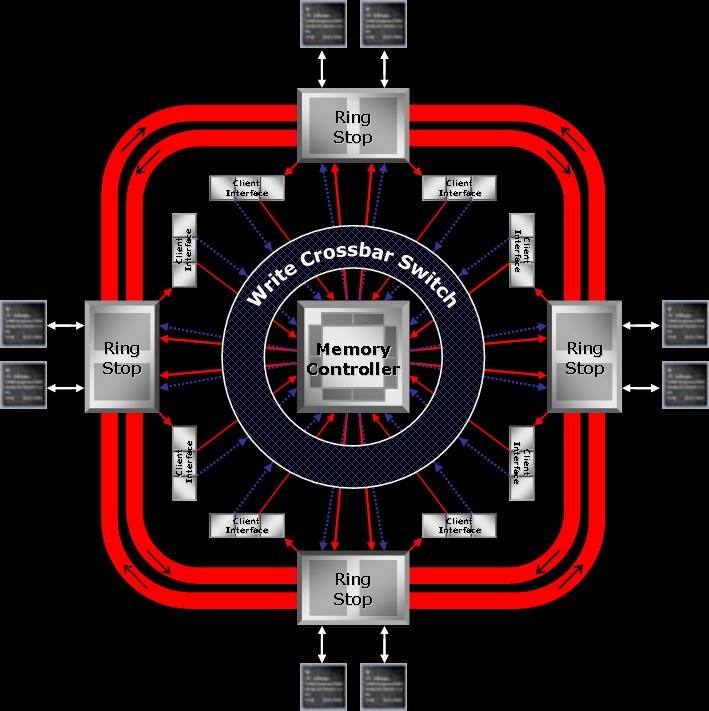
As we all know the R600 is a 1024 bit ring bus internally with 8x64 bit controllers and interfaces to a 512 bit external bus and the R520 had a 512 bit internal 8x32 organisation interfacing to a 256 bit external bus.
NOTE: In addition to these memory controllors there is an additional controller for PCI and video interfacing.
I am speculating that RV670 will have 4x64 bit controllers( 2 full duplex dual channel 64 bit memory controllers) in lieu of the 8x32 bit ones(4 full duplex dual channel 32bit memory controllers) and a Hypertransport interface for the controller sending requests to the ring stops on the bus.
This way with a sufficiently wide and fast hypertransport bus the multi chip module will have two RV670 die interfaced with a hypertransport interface and the package will have a 2x(2x64bit) controllers forming a 512 bit external interface.The ring bus width though could be the limitation, depending on a whether a bi directional 256bit or 512bit implementation is used.
The beauty of this design is that hypertransport interfaces easily with AMD processors for reusability for a multichip fusion design.
What do you guys think? Is it a viable design that can be expected in AMD designs or is it flawed?
I would really appreciate if you guys could point out flaws and present your ideas and opinions on multichip architectures for GPU's .
I have been a regular Beyond3D follower since nearly 4 years but this is the first time that i have thought of posting.
Especially with all the multi chip talk for the ATI r680 and r700.I thought it was high time a thread was started.
So heres what i think would be a nice idea, or may be some thing ATI already has up its sleeve in the RV670
.As we all know the R600 is a 1024 bit ring bus internally with 8x64 bit controllers and interfaces to a 512 bit external bus and the R520 had a 512 bit internal 8x32 organisation interfacing to a 256 bit external bus.
NOTE: In addition to these memory controllors there is an additional controller for PCI and video interfacing.
I am speculating that RV670 will have 4x64 bit controllers( 2 full duplex dual channel 64 bit memory controllers) in lieu of the 8x32 bit ones(4 full duplex dual channel 32bit memory controllers) and a Hypertransport interface for the controller sending requests to the ring stops on the bus.
This way with a sufficiently wide and fast hypertransport bus the multi chip module will have two RV670 die interfaced with a hypertransport interface and the package will have a 2x(2x64bit) controllers forming a 512 bit external interface.The ring bus width though could be the limitation, depending on a whether a bi directional 256bit or 512bit implementation is used.
The beauty of this design is that hypertransport interfaces easily with AMD processors for reusability for a multichip fusion design.
What do you guys think? Is it a viable design that can be expected in AMD designs or is it flawed?
I would really appreciate if you guys could point out flaws and present your ideas and opinions on multichip architectures for GPU's .