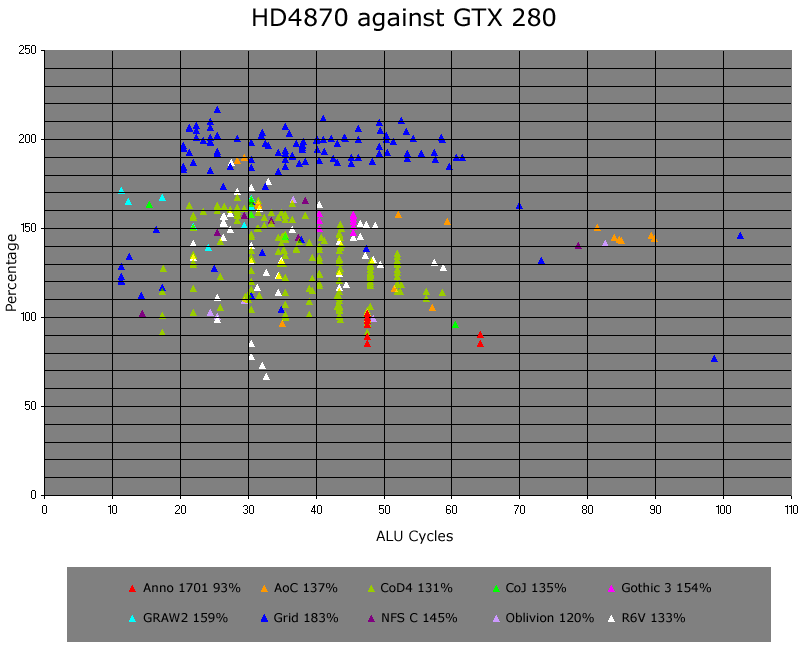
Jawed
Legend
Some NVidia comparisons, too:
So the scaling for GT200 is pretty close to theoretical. GT200 v G80 is all over the place, so I guess the prodigal MUL could be doing something...
Jawed
Code:
GTX280 faster than GTX260 8800U
GRAW 2 95% 114%
Rainbow Six: Vegas 97% 97%
Call of Duty 4 98% 112%
Gothic 3 99% 107%
Anno 1701 97% 112%
Test Drive Unlimited 97% 96%
Call of Juarez 98% 104%
Race Driver Grid 97% 112%
Oblivion 97% 105%
Stalker 97% 98%
Age of Conan 97% 110%
NfS Most Wanted 97% 104%
NfS Carbon 96% 106%
Average 97% 105%So the scaling for GT200 is pretty close to theoretical. GT200 v G80 is all over the place, so I guess the prodigal MUL could be doing something...
Jawed