Blazkowicz
Legend
you mean compositing render targets from different GPUs? that would be awesome but we would need some kind of a industry wide standard.
Think of a new X11, supporting the same kind of transparency. Your rendered window may come from your IGP, your other GPU, from software or from another GPU on the network.
VirtualGL allows a remote OpenGL Unix, application to run, with rendering done on the server's GPU. (frames are sent done the network with MJPEG compression, with near real-time or real-time performance)
That software appears to be doing pretty much what you're proposing!, but in the unix/OpenGL/X11 realm.
http://www.virtualgl.org/About/Introduction
(with OpenGL and X11, you can run a remote application, but it results in 3D rendering commands sent over the network and rendered locally in software mode. ugh!)
I guess it can be hacked to run your scenario.
Think of a new X11, supporting the same kind of transparency. Your rendered window may come from your IGP, your other GPU, from software or from another GPU on the network.
VirtualGL allows a remote OpenGL Unix, application to run, with rendering done on the server's GPU. (frames are sent done the network with MJPEG compression, with near real-time or real-time performance)
That software appears to be doing pretty much what you're proposing!, but in the unix/OpenGL/X11 realm.
http://www.virtualgl.org/About/Introduction
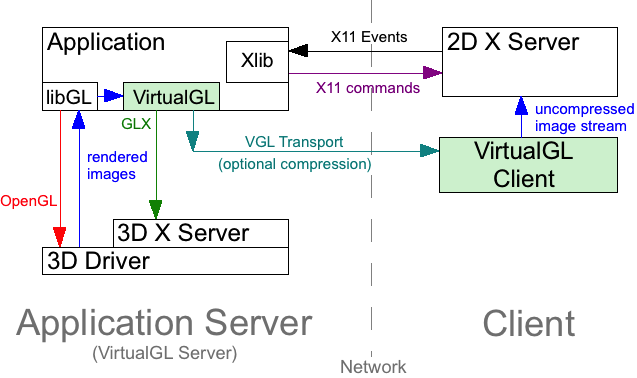
Normally, a Unix OpenGL application would send all of its drawing commands and data, both 2D and 3D, to an X-Windows server, which may be located across the network from the application server. VirtualGL, however, employs a technique called "split rendering" to force the 3D commands from the application to go to a 3D graphics card in the application server. VGL accomplishes this by pre-loading a dynamic shared object (DSO) into the application at run time. This DSO intercepts a handful of GLX, OpenGL, and X11 commands necessary to perform split rendering. Whenever a window is created by the application, VirtualGL creates a corresponding 3D pixel buffer ("Pbuffer") on a 3D graphics card in the application server. Whenever the application requests that an OpenGL rendering context be created for the window, VirtualGL intercepts the request and creates the context on the corresponding Pbuffer instead. Whenever the application swaps or flushes the drawing buffer to indicate that it has finished rendering a frame, VirtualGL reads back the Pbuffer and sends the rendered 3D image to the client.
(with OpenGL and X11, you can run a remote application, but it results in 3D rendering commands sent over the network and rendered locally in software mode. ugh!)
I guess it can be hacked to run your scenario.
