Frenetic Pony
Veteran
BTW, what really confuses me are those x86 rumors: https://www.techpowerup.com/261125/7nm-intel-xe-gpus-codenamed-ponte-vecchio
Other sites already confirmed this, but guess they are misinformed. Likely they mean more C++ than x86? Otherwise i would remember Larrabee and think this is no real GPU at all, or not related to the expected Xe dGPU.
Are you trying to put me out of a job?!?!(Sometimes I wish there'd be a rumour wikipedia where all those tasty tidbits are collected instead of strewn out across message boards, blogs, and tech news sites.)
")
Why buy ImgTech when they have the glorious ghost of Larrabee for their tiled rendering needs? All hail Larrabee!
They have included elements of previous Gen-iGPU techTiled rendering yes, but not tiled deferred rendering. Don't compare the two, "'it's totally inappropriate. It's lewd, vesuvius, salacious, outrageous!"©
More seriously, do we know if they started from scratch (well, as close as possible in this area), or started from their igpu tech ?
IC: Is Xe anything like Gen at a fundamental level?
RK: At the heart of Xe, you will find many Gen features. A big part of our decision making as we move forward is that the industry underestimates how long it takes to write a compiler for a new architecture. The Gen compiler has been with us, and has been continually improved, for years and years, so there is plenty of knowledge in there. It is impressive how much performance there is in Gen, especially in performance density. So we preserved lots of the good elements of Gen, but we had to get an order of magnitude increase in performance. The key for us is to leverage decades of our software investment – compilers, drivers, libraries etc. So, we maintained Gen features that help on software.
Are you trying to put me out of a job?!?!
They have included elements of previous Gen-iGPU tech
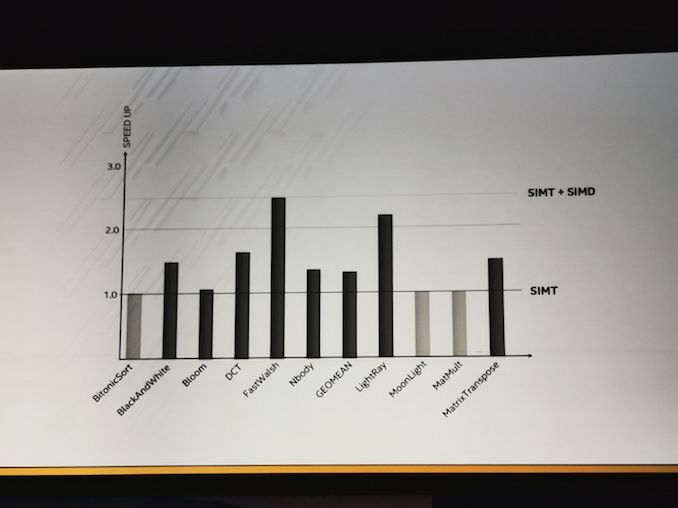
I'm unsure they mean it this way.IMO, "SIMT and SIMD units" = variable vector width ( SIMD8 / SIMD16 / SIMD32 ). It gives you (or the compiler) an option to trade TLP <-> DLP. Gen Graphics has this for years.
I'm unsure they mean it this way.
Could it be the SIMT unit sits on top the SIMD unit, meaning you could process say vec4 as a single SIMD data element, with a single instruction?
So you could divide your SIMT unit once into 8/16/32... threads like now, which then operate on any of 1,2,4,8... wide vector data elements as needed?
Though, sounds overkill. I did not understand this point very well.
They also mention they've got their own coding language, "Distributed Parallel C++", but I don't know what it's like. AFAIK the reason everyone likes CUDA is it's just so nice and clean, unlike the monster C++ has slowly become, so, I dunno there either.
How is CUDA better than modern C++? Also, if you use CUDA you are locked in to nVidea HW, which I do not think is something Intel desire...

