We all know ATI/AMD use a VLIW architecture since R600, but I can't find anywhere what type of architecture is using NVIDIA since G80.
I know that G80 is a 16-way SIMD within an 8-way MIMD and that it's a superscalar architecture, but not a single word on the Internet of the exact acronym of the specific architecture type.
Anyone?
There's a list here, BTW
http://en.wikipedia.org/wiki/Instruction_set#Categories_of_ISA
Update of 31/01/2011:
Ok, so far I learned that G80 is a SIMD architecture and there is no MIMD at all, is that right?
But I'm not yet sure about how many SIMD arrays are there exactly. Shouldn't one of them be an entire cluster like the ones laser-cutted on the GF100 cards?
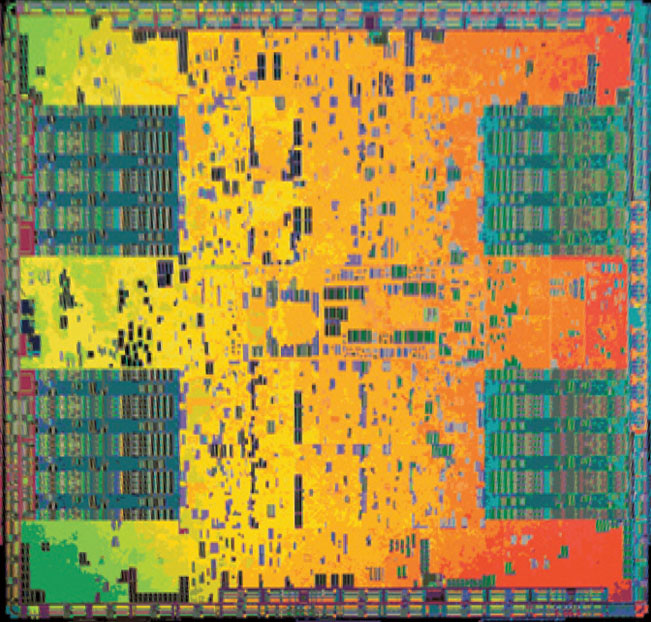
Anyway I posted a picture of the die along with a simple scheme of it and I'm actually seing 4 SIMD clusters.
In case I'm wrong, could any of you modify the die shot to draw the actual SIMD units?
G80 die shot:
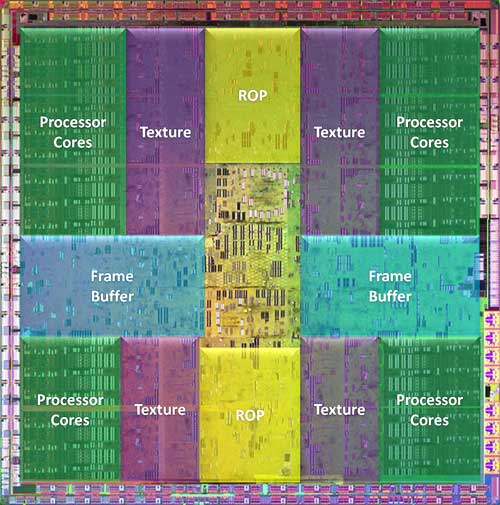
G80 die scheme:

Here is a GT200 die shot with schematics:
And GF100 die shot:

I know that G80 is a 16-way SIMD within an 8-way MIMD and that it's a superscalar architecture, but not a single word on the Internet of the exact acronym of the specific architecture type.
Anyone?
There's a list here, BTW
http://en.wikipedia.org/wiki/Instruction_set#Categories_of_ISA
Update of 31/01/2011:
Ok, so far I learned that G80 is a SIMD architecture and there is no MIMD at all, is that right?
But I'm not yet sure about how many SIMD arrays are there exactly. Shouldn't one of them be an entire cluster like the ones laser-cutted on the GF100 cards?
Anyway I posted a picture of the die along with a simple scheme of it and I'm actually seing 4 SIMD clusters.
In case I'm wrong, could any of you modify the die shot to draw the actual SIMD units?
G80 die shot:
G80 die scheme:
Here is a GT200 die shot with schematics:
And GF100 die shot:
Last edited by a moderator:
