Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
GPU Ray Tracing Performance Comparisons [2021-2022]
- Thread starter DavidGraham
- Start date
Inline RT doesn't disable anything when it's done via API (SER way) or manually.Yes. Inline disables any reordering or material sorting in HW, so we should use it only with care.
The UberShader name speaks for itself - it's just a big shader. Inlining produces big shaders.UberShader seems weakly defined here maybe
Quake RTX has SW materials sorting, UE 4 and 5 have it and all other major engines with RT support have it too, so there is no single-threaded anything, it's up to programmer whether he wants to sort something or not (api doesn't impose restrictions on that and many devs do sorting in SW), which will obviously depend on programers skills as well as runtime stats (sorting itself must be fast, perf hit w/o sorting must be bad enough to compensate for sorting overhead).Looking at the Quake RTX code back then, i definitively had this impression of classical RT, and simplicity > performance. The whole approach just ignores how GPUs work. They are not single threaded, and treating them as such performs poor.
SER just makes it way easier for devs to implement such features and get good performance out of them.
Last edited:
As i understand it, inline RT means tracing rays from any shader, likely compute. It returns the result immideatly to the same thread, so there is no more way HW could implement any reordering or material binning.Inline RT doesn't disable anything when it's done via API (SER way) or manually.
Contrary, if we use generation and hit shaders, the HW can shuffle rays around in arbitrary ways between those shader stages. Either to group hits by material, or to enable in traversal reordering in the future.
What's the benefit of SER in the scenario of inline tracing? I assume it has no effect at all. Am i wrong with that?
SER is just an API (that exploits Ada HW capabilities) that you can use in any Inline RT shader type to sort something by "key", you can sort hits by materials IDs or you can sort basically anything else with it. API does allow that, you can read here how it's done.What's the benefit of SER in the scenario of inline tracing? I assume it has no effect at all. Am i wrong with that?
TopSpoiler
Regular
The ReorderThread function only available in the raygeneration shader. I have no idea if it could be callable from the arbitrary material shaders.
'Big shader' does not tell much, so that's no definition of what it means.The UberShader name speaks for itself - it's just a big shader. Inlining produces big shaders.
Afaik, the term came up with deferred shading. The goal was to have just one shader handling all materials. That's a definition. But it's not meant to be big, but as small as possible while still handling variety.
Now it could also mean stuffing many material shaders into one, selecting with a jump per thread. Not sharing common code paths, no goal of generalization, minimized parallel execution.
So which definition would you associate with uber shaders? You can not just say it speaks for itself, because it doesn't.
I don't agree inline tracing causes big shaders in general. It simply depends on how much code you type around your traceRay call. For short range AO, inline would be fine for example. Because SER or reordering is pointless, and shader stages only add overhead.
Ok, missed this form looking at the code if so. Maybe they added it later, or i was wondering about some other things.Quake RTX has SW materials sorting
How? Idk what SER exactly is. NVAPI seems not public.SER just makes it way easier for devs to implement such features and get good performance out of them.
I assume it does internal binning so hit shaders have more active threads. But idk what's the granulary. I assume the feature is restricted to a single SM.
Thus, a global binning in SW might still make sense in cases. But SER won't help me with that. It only gives me the option of not doing this, in case SER does better.
But that's just guessing based on marketing slides.
How? Idk what SER exactly is. NVAPI seems not public.
The SER API is public, you can download the SER SDK and use it right away:
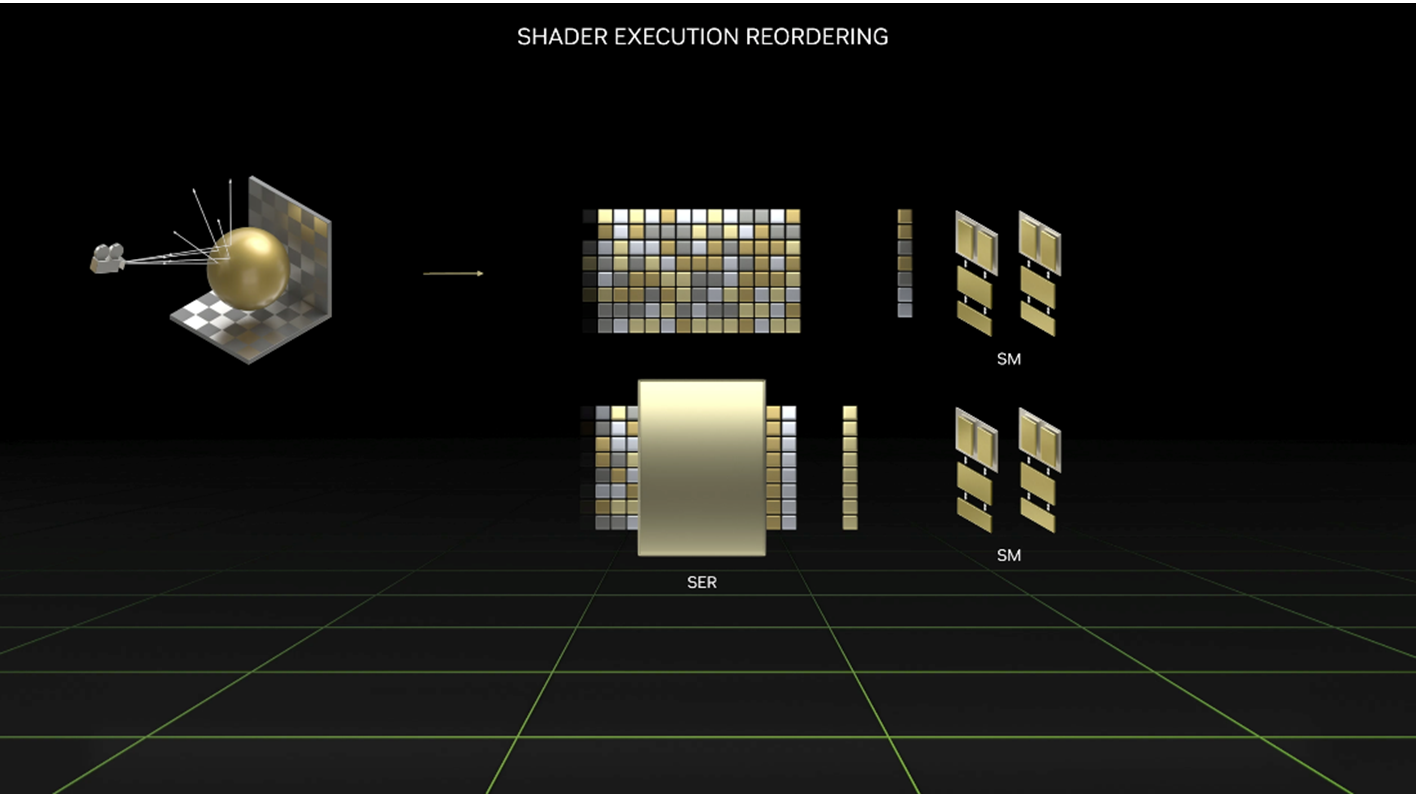
Improve Shader Performance and In-Game Frame Rates with Shader Execution Reordering | NVIDIA Technical Blog
Learn about Shader Execution Reordering (SER), a performance optimization that unlocks the potential for better ray and memory coherency in ray tracing shaders.
 developer.nvidia.com
developer.nvidia.com
SER in-depth whitepaper:
Very interesting - missed this before, thanks!SER is just an API (that exploits Ada HW capabilities) that you can use in any Inline RT shader type to sort something by "key", you can sort hits by materials IDs or you can sort basically anything else with it. API does allow that, you can read here how it's done.
I see my assumptions are pretty right but it can do more than just that. Good stuff.
Question about granularity is still open. Is the reordering happening across the whole chip or local to a SM?
Is there something out on DMM as well?The SER API is public, you can download the SER SDK and use it right away:
I have filled out the form to get API infos, but nothing yet.
TopSpoiler
Regular
FYI, RTX Remix uses Primary Surface Replacement for mirror reflection and refraction. For the diffuse reflection, it's done through secondary bounces sampling of the GI pass.That is one thing that is enjoyable in Portal RTX from my perspective: things in reflections have visually the similar quality as things in primary view. GI, material responses, reflections in their own right... I cannot wait to see more games getting to that level.

It is nice to see after playing Fortnite where reflections are... not very good looking in the base set up they have. I really wish Epic allowed hitlighting in Fortnite as an option.
Very interesting - missed this before, thanks!
I see my assumptions are pretty right but it can do more than just that. Good stuff.
Question about granularity is still open. Is the reordering happening across the whole chip or local to a SM?
The white paper is a little vague on that point. There are a few references to sorting and moving thread context “across the GPU” but that can mean anything. If I had to make I wild guess the sorting may be localized to a GPC as a single SM doesn’t have enough active threads to make sorting useful.
gamervivek
Regular
intel could use some tuning as well since it doesn't even start on 770.
Portal RTX not launching with ARC a770
Hi I downloaded Portal RTX today it's a free DLC for steam but that game won't launch with the ARC a770 there are some other post's out on the internet from people with the same problem. Is there a workaround on this issue?
community.intel.com
Whitepaper suggest setting up a ray tracing pipeline for games with Ray Queries as an easy path to integrate SER (not sure what the hard path would be), this can be just a raygen ubershader without indexing into shader table for closest hit shaders as far as I understand.The ReorderThread function only available in the raygeneration shader. I have no idea if it could be callable from the arbitrary material shaders.
Makes sense. SM is not enough, whole chip would probably already diminish the wins, even more so if their is a chiplet future for NV too.The white paper is a little vague on that point. There are a few references to sorting and moving thread context “across the GPU” but that can mean anything. If I had to make I wild guess the sorting may be localized to a GPC as a single SM doesn’t have enough active threads to make sorting useful.
I always wanted some HW accelerated binning / sorting. SER is an interesting solution. As with mesh shader tasks, it would be nice if such features could become exposed to compute at some point. It's useful in general.
More register and L1 cache and you can get 3080 level performance in Portal RTX with a 7900XT(X): https://www.comptoir-hardware.com/a...-radeon-rx-7900-xt-a-rx-7900-xtx.html?start=7
/edit: Explains the huge difference between Turing and Ampere, too. Ampere has 50% more L1 cache per ComputeUnit.
/edit: Explains the huge difference between Turing and Ampere, too. Ampere has 50% more L1 cache per ComputeUnit.
BTW: Computerbase has Raytracing numbers from the Callisto Protocol: https://www.computerbase.de/2022-12...bschnitt_rdna_3_in_aktuellen_neuerscheinungen
A 4090 loses 100FPS in 4K and it performs worse than Cyberpunk with Pyscho RT settings on a 4090...
A 4090 loses 100FPS in 4K and it performs worse than Cyberpunk with Pyscho RT settings on a 4090...
BTW: Computerbase has Raytracing numbers from the Callisto Protocol: https://www.computerbase.de/2022-12...bschnitt_rdna_3_in_aktuellen_neuerscheinungen
A 4090 loses 100FPS in 4K and it performs worse than Cyberpunk with Pyscho RT settings on a 4090...
yeah, that game with RT is double broken. Broken in general regarding performance and another set of broken on nvidia cards. Losing 3 times the performance on nvidia cards for some shadows ... It only loses a little over double the performance on the new XTX
DavidGraham
Veteran
It's a single threaded RT implementation, it's limited by the CPU on NVIDIA GPUs, not by the GPU, as the utilization of NVIDIA GPUs is sub 80%. The CPU overhead on NVIDIA GPUs is much larger than AMD GPUs in this game.Computerbase has Raytracing numbers from the Callisto Protocol: https://www.computerbase.de/2022-12...bschnitt_rdna_3_in_aktuellen_neuerscheinungen
A 4090 loses 100FPS in 4K and it performs worse than Cyberpunk with Pyscho RT settings on a 4090...
Getting a big lol about how the RX 6800 XT is just behind the 3090 Ti in a game with 3 ray tracing effects. Truly, the signs of a very representative title in ray tracing.BTW: Computerbase has Raytracing numbers from the Callisto Protocol: https://www.computerbase.de/2022-12...bschnitt_rdna_3_in_aktuellen_neuerscheinungen
A 4090 loses 100FPS in 4K and it performs worse than Cyberpunk with Pyscho RT settings on a 4090...
Similar threads
- Replies
- 3
- Views
- 797
- Replies
- 3
- Views
- 443
- Replies
- 7
- Views
- 2K
- Locked
- Replies
- 10
- Views
- 2K
- Replies
- 0
- Views
- 802