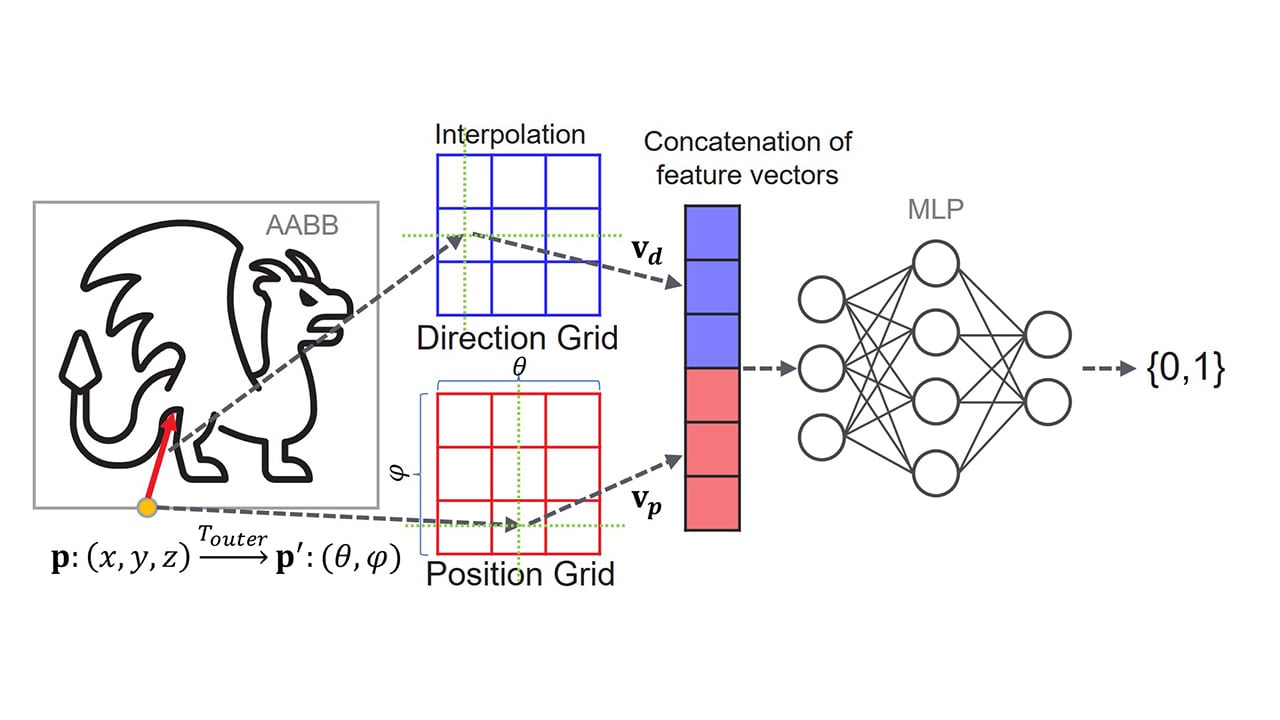
Introduction
Monte Carlo ray tracing is a cornerstone of physically based rendering, simulating the complex transport of light in 3D environments to achieve photorealistic imagery. Central to this process is ray casting which determines and computes intersections between rays and scene geometry. Due to the computational cost of these intersection tests, spatial acceleration structures such as bounding volume hierarchies (BVHs) are widely employed to reduce the number of candidate primitives a ray must test against.
Despite decades of research and optimization, BVH-based ray tracing still poses challenges on modern hardware, particularly on Single-Instruction Multiple-Thread (SIMT) architectures like GPUs. BVH traversal is inherently irregular: it involves divergent control flow and unpredictable memory access patterns. These characteristics make it difficult to fully utilize the parallel processing power of GPUs, which excel at executing uniform, data-parallel workloads. As a result, even with the addition of specialized ray tracing hardware, such as RT cores, the cost of BVH traversal remains a bottleneck in high-fidelity rendering workloads.
In contrast, neural networks, especially fully connected networks, offer a regular and predictable computational pattern, typically dominated by dense matrix multiplications. These operations map well to GPU hardware, making neural network inference highly efficient on SIMT platforms. This contrast between the irregularity of BVH traversal and the regularity of neural network computation raises an intriguing question: Can we replace the BVH traversal in ray casting with a neural network to better exploit the GPU’s architecture?
This idea is beginning to gain traction as researchers explore alternative spatial acceleration strategies that leverage learned models. In this post, we dive into the motivation behind this approach, examine the challenges and opportunities it presents, and explore how our invention, Neural Intersection Function, might reshape the future of real-time and offline ray tracing.