
This image should be used for a particular example. Every Quad is a Texel, the red dot a specific sample position. Well, trilinear filtering is a linear interpolation of 2 bilinear samples.
The first bilinear sample is calculated by putting a kernel with side length = 1 texel around the sample. In this case, only 2 texels are used. (The hardware filters 4 texels for every sample, the 2 unused texels are weighted with 0, the other texels with 0.5.)
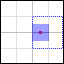
The other sample is from a mip map 1 level higher. To create this mip map, in most cases a simple 2x2-blockfilter is used. To underline this effect, I emphases this blocks with stronger lines.
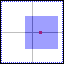
We got an effect of a "displacement-error". The new kernel is still centered arount the sample. But at the left hand are more contributing texels than on the right hand. This results from the pre-filtering of the mip-map.
Its evident, that a 4x4-Filter can filter trilinear from one mip-map (look at the image above.)
The question is, is a 4x4-Filter limited to common trilinear quality, or can an even "better" (more realistic) pixel color produced?
