Story so far:
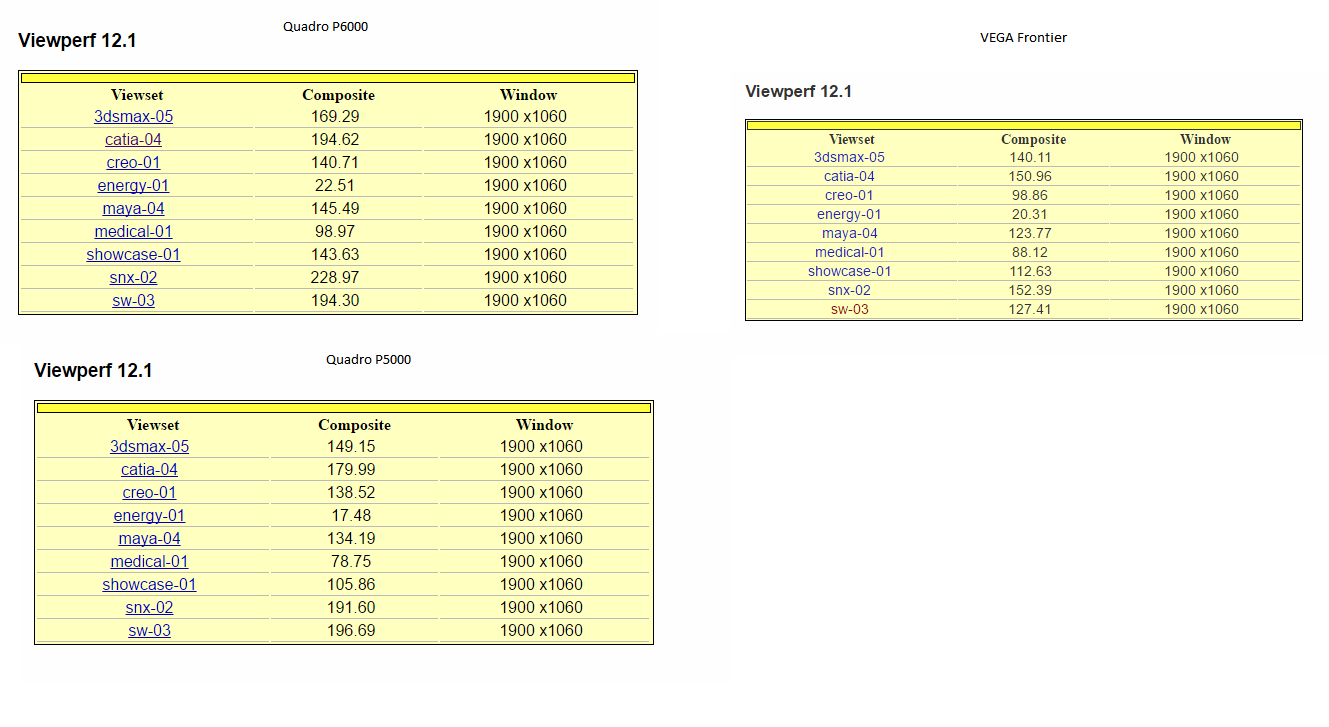
- "You can't compare these cards to Quadro! I don't care that AMD themselves categorizes this card as part of Pro line and boasts "professional, but not certified drivers". It's not a "Pro card"!
- "OK then, if we look at some gaming benchmarks..."
- "OMG, what kind of idiot would expect a PRO card to have decent gaming drivers? "
You know how sometimes the studios refuse to screen a movie for the critics...?
-Certified drivers by Autodesk, solidworks Dassault, etc take time... never seen a pro card got them available at launch before tests are conducts intensively.. In general, we allow our customers to use non certified drivers at their own risks, but they can still use them.. before we give the green light on selected drivers. ( Meaning in general a few certified drivers will be given green light in a year ) . ( By green light, i mean after conduct all tests in intern, we give a certification that this driver is stable for use with our software and recommended . ).-. Certified drivers are more for the company who bring sofwares to protect them vs bring satisfaction to consumers.... Thoses are not WHQL from MS..
Last edited:
")