Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
AMD: R9xx Speculation
- Thread starter Lukfi
- Start date
And some DC5.0 benching - ComputeMark. Quite slow...
Hmm, it's 91% _faster_ than HD5870. I wouldn't call it slow.
http://www.geeks3d.com/20100606/gpu-computing-directcompute-computemark-2-1-gtx-480-vs-hd-5870/
Correct, I haven't noticed the resolution setting.Hmm, it's 91% _faster_ than HD5870. I wouldn't call it slow.
http://www.geeks3d.com/20100606/gpu-computing-directcompute-computemark-2-1-gtx-480-vs-hd-5870/
")
Jawed
Legend
Now that's actually interesting.
HD6970 v HD5870:
The other three tests are pure math but with a lot of branching. I guess we're seeing a combination of short clauses of instructions and a high proportion of transcendental instructions. Julia set should have more intense branching.
I haven't looked at the compilation for this application but I suspect these fractals result in clauses that are short, which would tend to increase the demerit of VLIW-4 for transcendentals, e.g. 3 instruction clause on Cypress versus a 4 instruction clause on Cayman is a 33% slowdown per work item.
Rightmark Mineral and Fire shaders would be another good test for transcendentals, but without branching.
Can anyone get the extreme tests to run on NVidia? That Geeks3D page shows NVidia hardware failing for some reason.
HD6970 v HD5870:
- Fluid 3D texture - 196 v 42 = 467%
- Fluid 2D texture array - 116 - 44 = 264%
- Mandelbrot Vector - 58 - 61 = 95%
- Mandelbrot Scalar - 29 - 26 = 112%
- QJulia Ray Tracing - 56 - 65 = 86%
The other three tests are pure math but with a lot of branching. I guess we're seeing a combination of short clauses of instructions and a high proportion of transcendental instructions. Julia set should have more intense branching.
I haven't looked at the compilation for this application but I suspect these fractals result in clauses that are short, which would tend to increase the demerit of VLIW-4 for transcendentals, e.g. 3 instruction clause on Cypress versus a 4 instruction clause on Cayman is a 33% slowdown per work item.
Rightmark Mineral and Fire shaders would be another good test for transcendentals, but without branching.
Can anyone get the extreme tests to run on NVidia? That Geeks3D page shows NVidia hardware failing for some reason.
Interesting that Cayman remains atleast 2x or better than Cypress at all levels where as Barts drops off to Cypress levels after a factor of 10.

For better understanding of ComputeMark scores here is my HD5770 @880/1300 (can't get memory higher to match Cayman), same CPU but clocked a tad slower (CPU doesn't influence this score anyway).

Uploaded with ImageShack.us


Uploaded with ImageShack.us
GF100 has some performance woes with 3D textures under DC.Can anyone get the extreme tests to run on NVidia? That Geeks3D page shows NVidia hardware failing for some reason.
For better understanding of ComputeMark scores here is my HD5770 @880/1300 (can't get memory higher to match Cayman), same CPU but clocked a tad slower (CPU doesn't influence this score anyway).
Uploaded with ImageShack.us
So, compared to the scores over aat geeks3d.com this would imply that compute mark is basically NOT compute bound? I mean, your 5770 gets basically the same scores as a 5870 with twice as much compute horsepower.
And the fact that it's a bit more than 2x as fast from factor 16 upwards is probably mostly due to the slightly higher core clock.I think this is result of the 2 geometry engines... (= 2x performance over Cypress + some additional improvements here and there, which were implemented already in Barts)
Unknown Soldier
Veteran
So, compared to the scores over aat geeks3d.com this would imply that compute mark is basically NOT compute bound? I mean, your 5770 gets basically the same scores as a 5870 with twice as much compute horsepower.
Comparing the 5770 and 5870
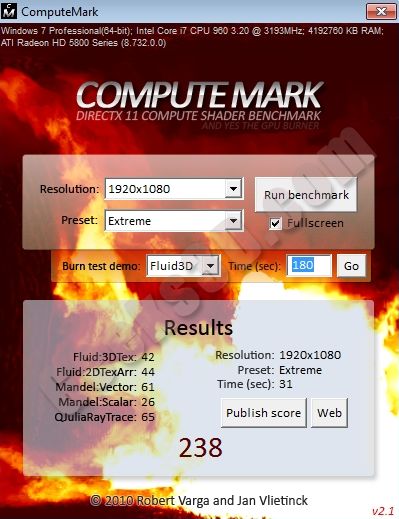
It seems the 5770 has a higher Fluid3D:Tex - 66 compared to the 5870's 42
Hence the scores look similar.
Unknown Soldier
Veteran
Now that's actually interesting.
HD6970 v HD5870:
The first two tests might be texture cache bound - in which case there's something radical going on.
- Fluid 3D texture - 196 v 42 = 467%
- Fluid 2D texture array - 116 - 44 = 264%
- Mandelbrot Vector - 58 - 61 = 95%
- Mandelbrot Scalar - 29 - 26 = 112%
- QJulia Ray Tracing - 56 - 65 = 86%
The other three tests are pure math but with a lot of branching. I guess we're seeing a combination of short clauses of instructions and a high proportion of transcendental instructions. Julia set should have more intense branching.
I haven't looked at the compilation for this application but I suspect these fractals result in clauses that are short, which would tend to increase the demerit of VLIW-4 for transcendentals, e.g. 3 instruction clause on Cypress versus a 4 instruction clause on Cayman is a 33% slowdown per work item.
Rightmark Mineral and Fire shaders would be another good test for transcendentals, but without branching.
Can anyone get the extreme tests to run on NVidia? That Geeks3D page shows NVidia hardware failing for some reason.
Very interesting
Broken Hope
Regular
There was an updated build of GPU-Z

Comparing the 5770 and 5870
http://www.ozone3d.net/public/jegx/201006/computemark_hd5870_1920x1080_extreme.jpg
It seems the 5770 has a higher Fluid3D:Tex - 66 compared to the 5870's 42
Hence the scores look similar.
So, that makes either the score provided for HD 5870 or the benchmark itself even more un-bound by pure compute. Or do I miss the obvious explanation as to why a HD 5770 should outperform a HD 5870 by more than 50%?
edit:I am just running this ComputeMark 2 on a GTX 580. Seems like the drivers have been holding Fermi back quite a bit. Plus, it doesn't crash on Extreme any more.

Last edited by a moderator:
For me the most interesting thing about this graph is actually the lower-than-2x improvement for tesselation levels 3-5. Must be some overhead somewhere?I think this is result of the 2 geometry engines... (= 2x performance over Cypress + some additional improvements here and there, which were implemented already in Barts)
The front-end is still quite far behind GF110 as far as I can tell. More like GF104, at least as far as tesselation goes. That's not necessarily a bad thing, though.Cayman seems to have still big room for improvements. Although AMD improved the front-end, it still falls a little behind GF110 while offering 70% higher INT8 fill-rate and MADD ALU peak.
DavidGraham
Veteran
There was an updated build of GPU-Z
Wizzard posted a new build of GPU-Z (0.4.9) yesterday , which supports 6900 .
Sadly that just confirms the number of SPs (1536)
.Wizzard posted a new build of GPU-Z (0.4.9) yesterday , which supports 6900 .
Sadly that just confirms the number of SPs (1536)
GPU-Z is an ARCHIVE!
it can't read nothing from GPU.
Similar threads
- Replies
- 50
- Views
- 9K
- Replies
- 3K
- Views
- 692K
- Replies
- 1K
- Views
- 393K
- Replies
- 12K
- Views
- 2M
- Replies
- 6
- Views
- 6K